Deep Research Agents: A Systematic Examination And Roadmap
Abstract: The rapid progress of LLMs has given rise to a new category of autonomous AI systems, referred to as Deep Research (DR) agents. These agents are designed to tackle complex, multi-turn informational research tasks by leveraging a combination of dynamic reasoning, adaptive long-horizon planning, multi-hop information retrieval, iterative tool use, and the generation of structured analytical reports. In this paper, we conduct a detailed analysis of the foundational technologies and architectural components that constitute Deep Research agents. We begin by reviewing information acquisition strategies, contrasting API-based retrieval methods with browser-based exploration. We then examine modular tool-use frameworks, including code execution, multimodal input processing, and the integration of Model Context Protocols (MCPs) to support extensibility and ecosystem development. To systematize existing approaches, we propose a taxonomy that differentiates between static and dynamic workflows, and we classify agent architectures based on planning strategies and agent composition, including single-agent and multi-agent configurations. We also provide a critical evaluation of current benchmarks, highlighting key limitations such as restricted access to external knowledge, sequential execution inefficiencies, and misalignment between evaluation metrics and the practical objectives of DR agents. Finally, we outline open challenges and promising directions for future research. A curated and continuously updated repository of DR agent research is available at: {https://github.com/ai-agents-2030/awesome-deep-research-agent}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is a guide to a new kind of AI system called “Deep Research (DR) agents.” Think of DR agents as smart, tireless research assistants. They don’t just answer simple questions—they plan multi-step investigations, search the web and databases in real time, use tools (like code, charts, and calculators), keep notes, and then write clear, structured reports. The paper explains how these agents work, compares different designs, reviews how they’re tested, and lays out a roadmap for making them better.
A living list of DR agent projects is here: https://github.com/ai-agents-2030/awesome-deep-research-agent
Goals and questions in simple terms
The authors set out to answer a few practical questions:
- What exactly is a Deep Research agent, and how is it different from earlier AI systems?
- How do these agents find information (through APIs or by browsing the web like a person)?
- What tools can they use (coding, data analysis, images/video)?
- How are these agents organized (one big agent vs. a team of specialized agents)?
- How are they tested, and what do current tests miss?
- What still doesn’t work well, and how can researchers improve these systems?
How the authors approached the topic
Instead of running one big experiment, this paper reviews many recent systems and stitches together what we’ve learned into a clear map of the field. Here’s the approach, explained with everyday analogies:
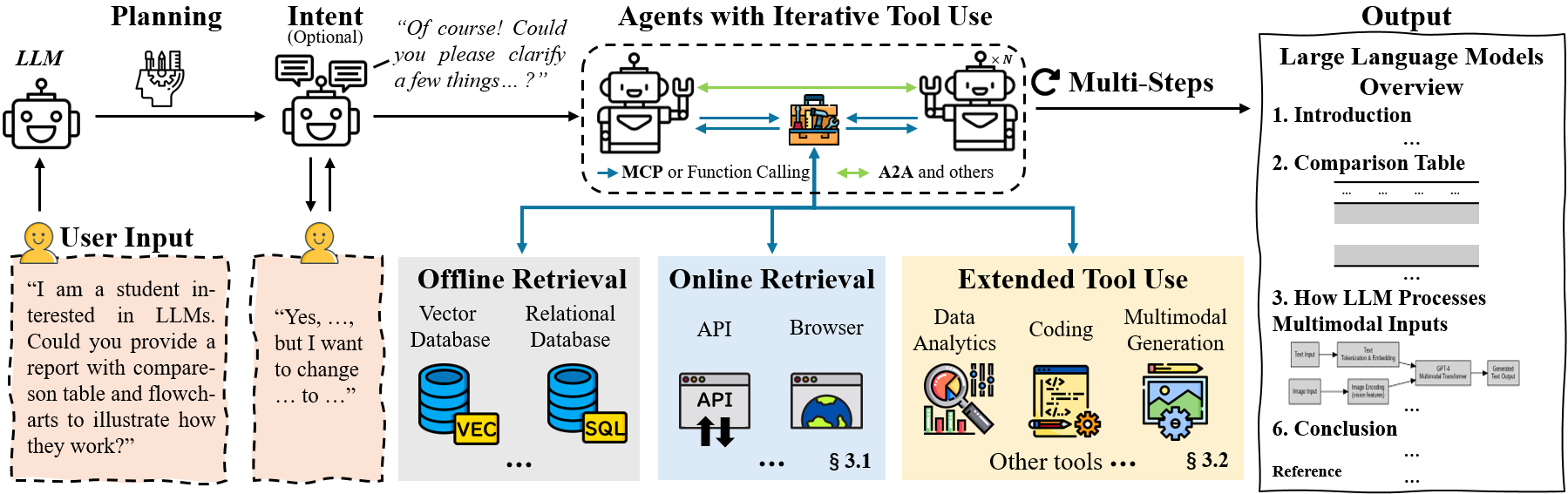
- Two ways to collect information:
- API-based search: Like asking a librarian for specific, well-organized cards. It’s fast and structured but may miss content hidden behind interactive webpages.
- Browser-based search: Like walking the library yourself, opening books, clicking links, and scrolling. It finds richer, dynamic content but is slower and more complex.
- Tool use:
- Code interpreter: The agent can run little programs (often Python) to calculate, clean data, or test ideas—like using a calculator and spreadsheet.
- Data analytics: Turning raw text and tables into charts, summaries, and basic statistics—like making a lab report.
- Multimodal: Handling not just text, but images, maps, PDFs, maybe audio/video—like studying with photos and diagrams, not just words.
- Standard “plug and play” connections:
- Model Context Protocol (MCP): A common “plug” so different tools connect to agents safely and consistently.
- Agent-to-Agent (A2A): A shared “language” so different agents can talk, share tasks, and collaborate.
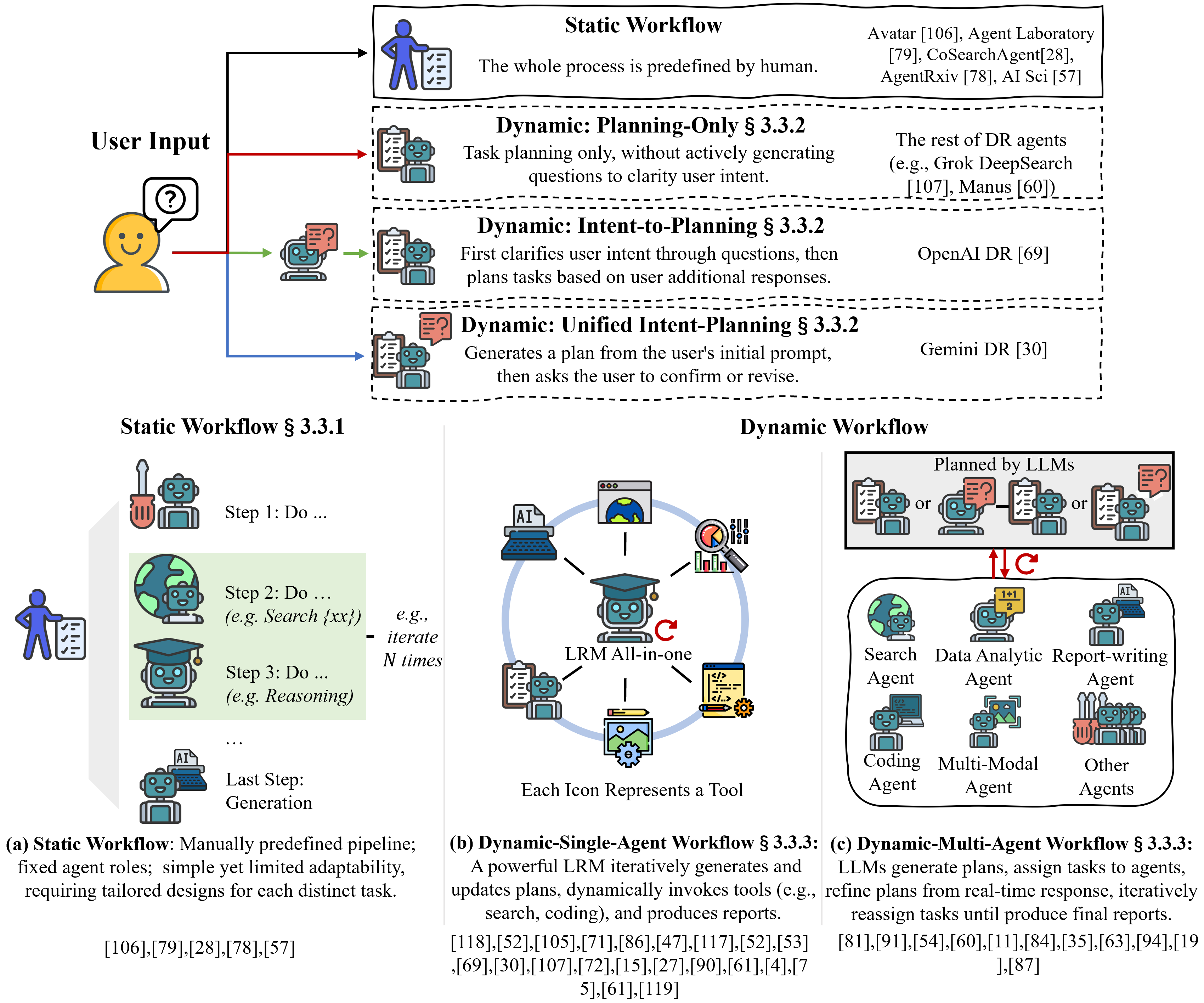
- Workflows (how the agent plans and acts):
- Static workflow: A fixed recipe (step 1, step 2, step 3). Easy to follow but not flexible.
- Dynamic workflow: The agent adapts the steps as it learns more—like a detective changing the plan based on new clues.
- Planning styles:
- Planning-only: The agent plans right away based on your prompt.
- Intent-to-planning: The agent first asks clarifying questions, then plans.
- Unified intent-planning: The agent drafts a plan and asks you to confirm or adjust it.
- Single agent vs. multi-agent:
- Single agent: One very capable agent does all tasks.
- Multi-agent: A manager agent divides work among specialist agents (like a team with roles).
- Memory strategies (how agents handle long, messy research):
- Bigger “backpack” (longer context window): Feed more text into the AI at once. Simple but can be expensive.
- Summarizing (compression): Keep the important bits to save space—like concise notes.
- External storage: Save info in databases or files and fetch it later—like a personal filing cabinet or note system.
- Training/tuning:
- Beyond prompting: Some systems fine-tune models or use reinforcement learning (RL) to reward good research behavior (accurate retrievals, useful plans, correct answers).
- Benchmarks and testing:
- The paper reviews common tests (e.g., question-answering, multi-step tasks) and explains where they fall short (for example, limited access to real-time web info or poor fit with detailed research goals).
What they found and why it matters
Here are the main takeaways, put simply:
- DR agents = LLM “thinking” + real-time information + tool use + planning + reporting. They’re designed for deep, multi-step research, not just quick answers.
- Two complementary ways to retrieve info:
- APIs are fast and clean but may miss complex, interactive content.
- Browsers reach dynamic, real-world pages but are slower and trickier.
- The best systems often mix both.
- Tool use is central:
- Running code, analyzing data, and handling images/PDFs lets agents move from raw facts to meaningful insights.
- Clear taxonomy (map of designs):
- Static vs. dynamic workflows
- Three planning styles (plan now, clarify then plan, or plan + confirm)
- Single-agent vs. multi-agent architectures
- Memory is a big deal:
- Agents need good note-taking and storage strategies to avoid drowning in text.
- Current benchmarks have gaps:
- Many tests don’t allow full web access, expect slow one-step execution, or use metrics that don’t match what real research needs (like report quality or source coverage).
- Open challenges and roadmap:
- Improve information access (especially dynamic, real-time content).
- Run steps in parallel where possible (not just one-after-another).
- Build better multimodal tests (text + images + data).
- Make multi-agent coordination more robust and efficient.
- Use shared protocols (MCP, A2A) for smooth tool and agent collaboration.
- Support “non-parametric” continual learning (agents get better by upgrading tools, memory, and workflows without retraining the whole model).
Why this matters: As DR agents get better, they can help students, scientists, journalists, and analysts do trustworthy, up-to-date research faster and more thoroughly.
What this could mean for the future
If researchers follow this roadmap:
- You’ll see AI research assistants that can handle complex, real-world tasks: tracking breaking news, analyzing studies, checking sources, and drafting reliable reports.
- Teams of agents will collaborate more smoothly (thanks to A2A) and use tools more easily (thanks to MCP), reducing the time spent setting up custom integrations.
- Benchmarks will better match real research work, pushing systems to be more accurate, explainable, and useful.
- Agents will become more adaptable without expensive retraining, by upgrading their tools and memory systems.
- Overall, this could make high-quality research more accessible—helping people make evidence-based decisions at school, in the lab, and at work.
Practical Applications
Immediate Applications
Below are applications that can be deployed now using the paper’s surveyed capabilities (dynamic planning, hybrid API+browser retrieval, code execution, multimodal processing, MCP/A2A integration, memory stores, and ReAct-style loops), as already demonstrated by systems such as OpenAI DR, Gemini DR, Grok DeepSearch, Perplexity DR, Manus/OpenManus, OWL, AutoGLM Rumination, Agent-R1, Search-R1, ReSearch, and DeepResearcher.
- Enterprise market and competitive intelligence reports (sectors: software, e-commerce, media, finance)
- Workflow: Unified intent-planning to clarify goals; hybrid API retrieval (Google/Bing, company registries, news feeds) plus browser for press releases/blogs; memory (vector DB) to avoid redundant reads; code interpreter for charts and KPI tables; MCP connections to CRM/Confluence/Notion for distribution.
- Dependencies: API keys and rate limits; ToS/legal compliance for scraping; human review for high-stakes decisions; provenance/citation requirements.
- Automated scientific literature reviews and research digests (sectors: academia, biotech, healthcare)
- Workflow: API retrieval (arXiv, PubMed, Semantic Scholar), browser PDF access, “Reason-in-Documents” compression for long texts, citation tracking, code interpreter for basic meta-analysis and plots; multi-agent division (retriever, summarizer, evidence weaver).
- Dependencies: Paywalls and institutional access; domain expert validation; consistent citation metadata; reproducibility guardrails.
- Policy briefs and horizon scanning (sectors: public policy, government, NGOs)
- Workflow: Intent-to-planning for stakeholder alignment; browser-based retrieval of committee reports, white papers, and PDFs; iterative evidence triangulation; report generation with alternative scenarios and uncertainty annotations.
- Dependencies: Timeliness of sources; bias and coverage across regions/languages; clear citation trails; editorial oversight.
- Due diligence and compliance monitoring (sectors: finance, legal, enterprise risk)
- Workflow: API calls to corporate filings (e.g., EDGAR), sanctions/PEP lists; browser for investigative reporting; tool-use for entity resolution and risk scoring; memory of prior cases; audit logs for traceability.
- Dependencies: PII handling and data privacy; regulated-use approvals; false positive mitigation; secure MCP connectors to internal KYC tools.
- Customer support knowledge base upkeep and drift correction (sectors: software, telecom, fintech)
- Workflow: Scheduled agentic RAG runs over release notes/forums/docs; browser extraction; MCP to CMS for draft updates; human-in-the-loop approval; memory for change diffs.
- Dependencies: Content governance; CMS permissions; rate limits on community platforms; rollback mechanisms.
- Consumer product decision assistant (sectors: daily life, e-commerce)
- Workflow: Unified intent-planning to capture user constraints; browser-based retrieval of reviews/spec sheets; price-history analysis via code interpreter; side-by-side comparisons with cited claims.
- Dependencies: Review spam/affiliate bias; ad-heavy pages; timely refresh; clear disclaimers.
- Sales/account research packs (sectors: B2B software, services)
- Workflow: MCP connectors to CRM; search APIs plus browser for public signals; report generation (org charts, initiatives, tech stack) with citations; manager-agent loop for quality control.
- Dependencies: Platform ToS (e.g., LinkedIn signals); data privacy; internal policy compliance.
- Grant and collaborator scouting (sectors: academia, research offices, non-profits)
- Workflow: Funding APIs and program pages; topic clustering via vector search; knowledge graph of PIs/institutions; email-ready summaries and deadlines.
- Dependencies: Regional disparities in data availability; link rot; eligibility nuances.
- Equity research copilot for public companies (sectors: finance)
- Workflow: EDGAR/API retrieval of 10-K/Q, browser for earnings calls and analyst notes; code interpreter for ratio/sensitivity analysis; memory for longitudinal coverage; structured thesis with risk factors.
- Dependencies: Compliance and supervision rules; not investment advice; data licensing.
- Standards/RFC and tech proposal synthesizer (sectors: software, networking)
- Workflow: Browser retrieval of RFCs/issue threads; code interpreter to run example snippets/tests; structured FAQs; cross-reference maps.
- Dependencies: Correctness verification; licensing of sample code; fast refresh of evolving standards.
- OSINT triage for cyber threat intel (sectors: cybersecurity)
- Workflow: Browser-based exploration of repos, forums, CVE feeds; multi-agent enrichment (IOC extraction, clustering); daily intel briefs with confidence tags.
- Dependencies: False positives; ethics/legalities of forum scraping; need for analyst validation.
- Course reading packs and study guides (sectors: education)
- Workflow: Intent-to-planning for learning objectives; retrieval from open courseware/texts; multimodal content inclusion (figures/tables); spaced review schedules stored in memory.
- Dependencies: Copyright and fair use; accessibility; age-appropriate filtering.
Long-Term Applications
The following require further research, scaling, standards, or integration maturity (e.g., asynchronous parallel execution, robust multimodal reasoning, secure computer-use, A2A ecosystems, continual learning, and aligned benchmarks), as identified in the paper’s roadmap and open challenges.
- Autonomous “AI Scientist” loops from hypothesis to manuscript (sectors: academia, biotech, materials)
- Workflow: Dynamic multi-agent orchestration (planner, experiment designer, analyst, writer); MCP to ELNs/LIMS and lab robots; continual memory via knowledge graphs; RL-tuned single-agent reasoning within ReAct loops for end-to-end coherence.
- Dependencies: Safe lab integration; experimental design ethics; reproducibility standards; peer-reviewable transparency.
- Regulatory-grade clinical evidence synthesis and guideline drafting (sectors: healthcare)
- Workflow: Continuous ingestion from PubMed/clinical trial registries; study appraisal pipelines; multimodal inclusion (figures, scans); uncertainty quantification and audit trails; periodic updates.
- Dependencies: Regulatory approvals; clinician oversight; liability; strong provenance and bias controls.
- Autonomous computer-use for enterprise transactions (sectors: operations, procurement, finance)
- Workflow: Headless browser with authenticated sessions; secure MCP connectors to ERP/SaaS; A2A task handoffs; guardrails for action limits and approvals.
- Dependencies: Identity and access management; ToS compliance; robust rollback; SOC2/ISO controls.
- Real-time regulatory monitoring and impact simulation (sectors: policy, finance, energy)
- Workflow: Event-driven, asynchronous retrieval; economic or power-system simulators via code interpreter; scenario planning with sensitivity analyses; alerting to stakeholders.
- Dependencies: Reliable real-time feeds; model calibration/validation; false alarm costs.
- Cross-organization agent ecosystems via A2A (sectors: research consortia, supply chains, standards bodies)
- Workflow: Agent Cards for discovery, Tasks/Artifacts for collaboration; mixed-vendor agent swarms; provenance-preserving workflows; federated knowledge graphs.
- Dependencies: Interoperability standards; data-sharing agreements; governance and dispute resolution.
- Multimodal deep research over video/audio/geospatial/satellite data (sectors: media, defense, agriculture, energy)
- Workflow: Multimodal LRMs; geospatial analytics in code interpreter; hybrid API+browser for sensor metadata; temporal memory for time-series reasoning.
- Dependencies: Compute cost; data licensing and export controls; domain-specific benchmarks.
- Personalized lifelong learning researchers (sectors: education, corporate L&D)
- Workflow: Unified intent-planning with learner models; non-parametric continual learning of user preferences and gaps; multimodal learning plans; privacy-preserving on-device caches.
- Dependencies: Consent and privacy; drift detection; explainability.
- Enterprise “knowledge OS” with continuous indexing and self-evolving tools (sectors: all)
- Workflow: Hybrid retrieval with non-parametric continual learning; auto-instantiation of MCP servers tailored to tasks (as in Alita); RL-based query refinement; knowledge-graph memory.
- Dependencies: Change management; data governance; cost control; tool supply-chain security.
- Verified research outputs with formal evaluation and provenance signatures (sectors: software, legal, academia)
- Workflow: Structured CoT with redaction-safe traces; artifact hashing; deterministic replay; benchmarks aligned with DR goals (depth, coverage, tool-use).
- Dependencies: Community standards; infrastructure for notarization; privacy-preserving explainability.
- Smart-city and infrastructure planning agents (sectors: government, energy, transport)
- Workflow: Asynchronous multi-source ingestion (sensors, reports, public forums); simulation models; multi-agent negotiation of trade-offs; public-ready briefs with alternatives.
- Dependencies: Data-sharing MoUs; fairness and community engagement; long-horizon accountability.
- End-to-end robo-analysts producing compliant research dossiers (sectors: finance)
- Workflow: Continuous ingestion of filings/news; model-driven theses with stress tests; automated compliance checks; A2A collaboration with audit agents.
- Dependencies: Regulatory approval; rigorous supervision; market abuse safeguards.
- ESG and environmental monitoring agents (sectors: energy, manufacturing, retail)
- Workflow: Web plus sensor APIs; claim verification against third-party data; periodic ESG narratives with quantified metrics and evidence links.
- Dependencies: Data quality and greenwashing detection; standard taxonomies; assurance processes.
Notes across applications: Many rely on hybrid API- and browser-based retrieval; code interpreters for analysis; memory via vector databases and knowledge graphs; MCP for tool interoperability; A2A for cross-agent collaboration; dynamic single- or multi-agent workflows; and RL-tuned reasoning. Feasibility hinges on secure tool invocation, provenance, evaluation alignment, compute cost, and human oversight in high-stakes domains.
Collections
Sign up for free to add this paper to one or more collections.