- The paper introduces Weaver, a framework that aggregates multiple weak verifiers to reduce the gap between generated and verified outputs.
- It employs adaptive weighting, binarization, and weak supervision to estimate verifier accuracies and improve candidate selection.
- Empirical results show Weaver achieves near-oracle performance, outperforming majority voting by up to 15.5% and enabling efficient distillation.
Shrinking the Generation-Verification Gap with Weak Verifiers: The Weaver Framework
Introduction and Motivation
Verification is a central challenge in the deployment of LLMs, particularly for tasks requiring high precision such as mathematics, code generation, and scientific reasoning. While repeated sampling from LLMs can increase the likelihood of generating a correct response, the ability to reliably select the correct response from a pool of candidates is fundamentally limited by the quality of the verifier. Perfect (oracle) verifiers are either unscalable (e.g., human evaluation) or only available in narrow domains (e.g., formal proof checkers like Lean). In practice, most available verifiers—reward models (RMs) and LMs prompted as judges—are weak: they are noisy, poorly calibrated, and often exhibit high false positive rates.
This work introduces Weaver, a framework for aggregating multiple weak verifiers to close the generation-verification gap without requiring large amounts of labeled data. Weaver leverages weak supervision (WS) techniques to estimate verifier accuracies and adaptively combine their outputs, outperforming naive ensembling and majority voting. The framework is further extended via distillation, enabling efficient deployment with minimal compute overhead.
Given a query q and a set of K candidate responses {rj}j=1K generated by an LLM, the goal is to select a correct response rj∗ such that y(q,rj∗)=1, where y is the (unknown) correctness label. Each verifier vk provides a score sjk=vk(q,rj) for each candidate. The challenge is to aggregate these scores into a selection rule f(q,rj) that maximizes the probability of selecting a correct response, ideally approaching the upper bound set by Pass@K (the probability that at least one correct response exists among K samples).
The generation-verification gap is defined as Pass@K−Success Rate, where the success rate is the empirical accuracy of the selection rule. The objective is to minimize this gap.
Weighted vs. Naive Verifier Ensembling
Naive ensembling—averaging verifier scores—implicitly assumes uniform verifier quality. However, empirical analysis reveals substantial heterogeneity in verifier accuracies, with ranges up to 37.5% across tasks. Weighted ensembles, where each verifier is assigned a learned weight, can exploit this heterogeneity for improved selection accuracy. Supervised approaches (e.g., logistic regression, Naive Bayes) require substantial labeled data, which is often unavailable.
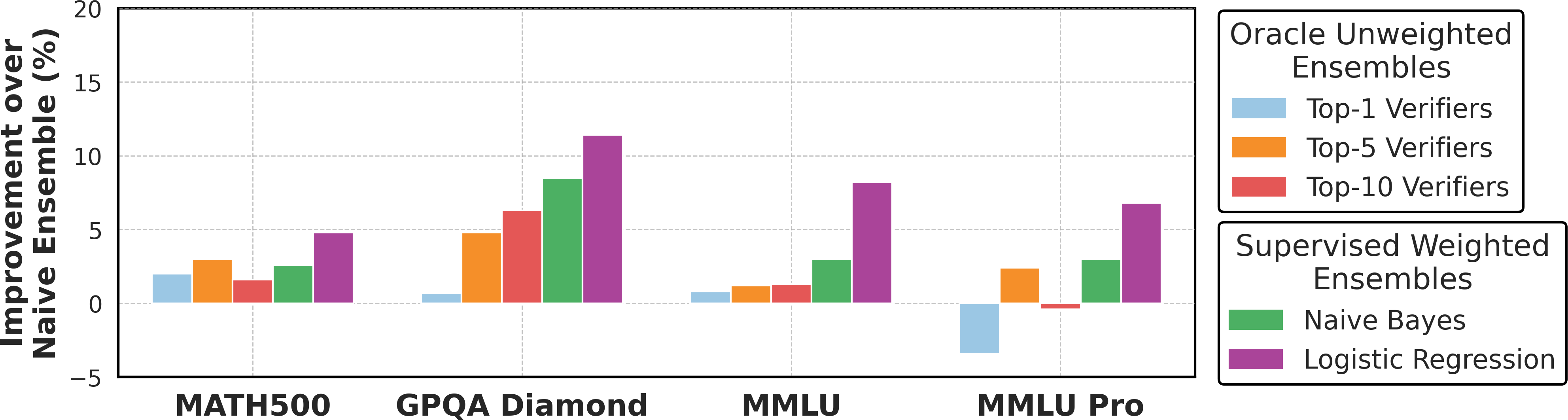
Figure 1: Weighted verifier ensembles, using oracle data or learned aggregation weights, outperform naive combinations by 3.6% and 7.8% on average, respectively.
The Weaver Framework: Weak Supervision for Verifier Aggregation
Weaver adapts weak supervision to the verification setting, addressing unique challenges:
- Inconsistent Output Formats: Verifiers emit scores in diverse formats (continuous, binary, Likert).
- Low-Quality/Adversarial Verifiers: Some verifiers perform near chance or worse, necessitating filtering.
- Limited Labeled Data: Only a small development set is available for estimating global statistics.
Algorithmic Details
- Binarization and Normalization: Verifier scores are normalized and binarized using thresholds estimated from a small labeled development set, ensuring comparability and robustness to calibration differences.
- Filtering: Verifiers with extreme marginals or low accuracy are pruned to ensure identifiability and stability in the WS model.
- Latent Variable Model: Weaver models the joint distribution of binary verifier outputs and the latent correctness label, assuming conditional independence of verifiers given the label. The posterior probability of correctness is computed as:
Pr(Y=1∣S1,…,Sm)=Pr(S1,…,Sm)∏k=1mPr(Sk∣Y=1)Pr(Y=1)
Verifier accuracies Pr(Sk=1∣Y=1) are estimated via moment matching on observed pairwise statistics, following the Snorkel paradigm.
Empirical Results
Closing the Generation-Verification Gap
Weaver is evaluated on MATH500, GPQA Diamond, MMLU College, and MMLU Pro, using Llama 3.3 70B Instruct as the generator and a pool of 33 open-source RMs and LM judges as verifiers. Weaver achieves an average accuracy of 87.7%, outperforming majority voting by 15.5% and coming within 4.2% of the Pass@100 oracle. Notably, Weaver matches or exceeds the performance of much larger or more heavily tuned models (e.g., OpenAI o3-mini) using only repeated sampling and weak verifier aggregation.
Scaling with Generations and Verifiers
Increasing the number of candidate generations K amplifies the benefits of strong verification. While majority voting and naive ensembling quickly plateau, Weaver continues to improve, closely tracking the oracle upper bound.
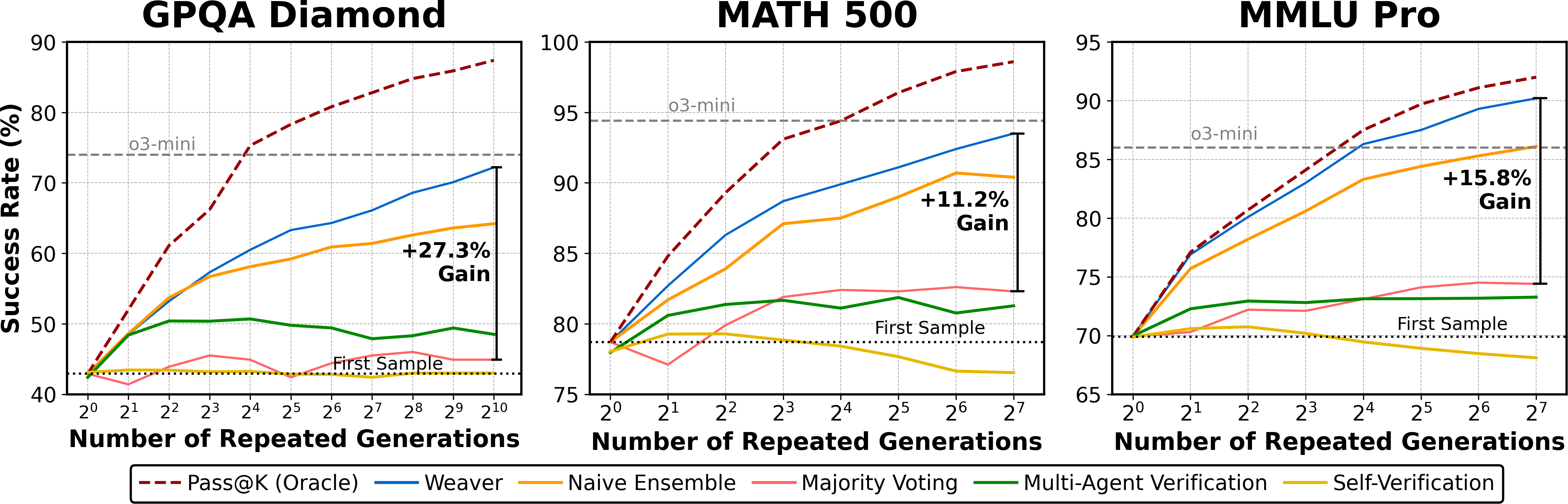
Figure 2: As K increases, Weaver narrows the generation-verification gap, outperforming alternative verification methods by an average of 18.3%.
Scaling the number of verifiers also yields substantial gains, with Weaver outperforming naive ensemble averaging across both oracle top-5 and total verifier configurations.
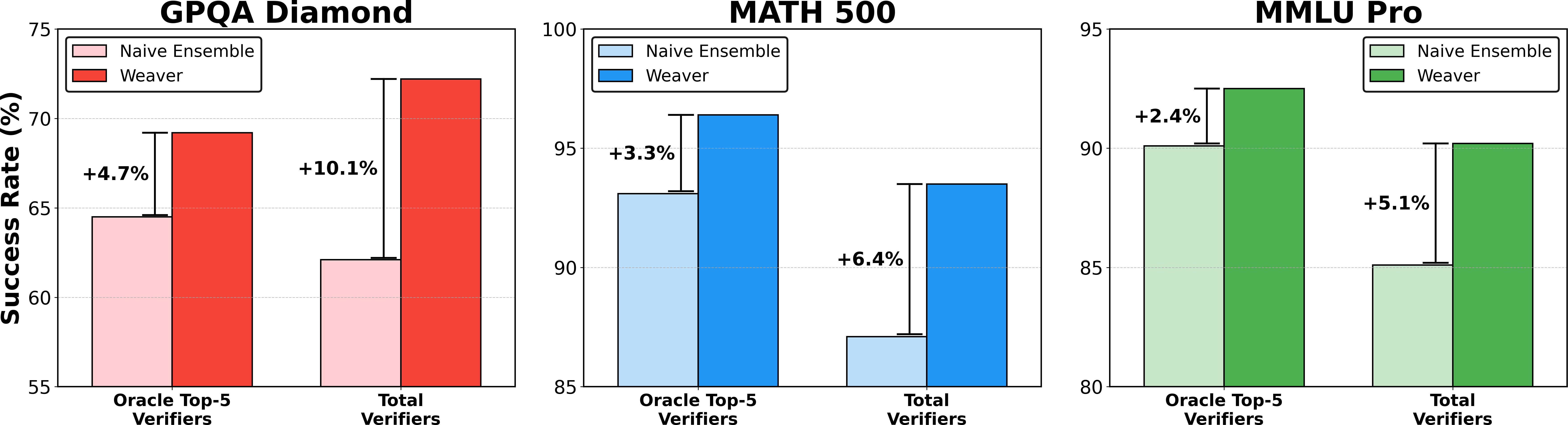
Figure 3: Weaver consistently outperforms naive ensemble averaging, with improvements ranging from +2.4% to +10.1% across datasets.
Compute-Accuracy Trade-Offs
Verification can dominate inference-time compute costs. Weaver achieves the highest accuracy but at increased compute, as each candidate must be scored by multiple verifiers. To address this, Weaver is distilled into a 400M-parameter cross-encoder, retaining 98.7% of the full ensemble's accuracy while reducing verification compute by 99.97%.
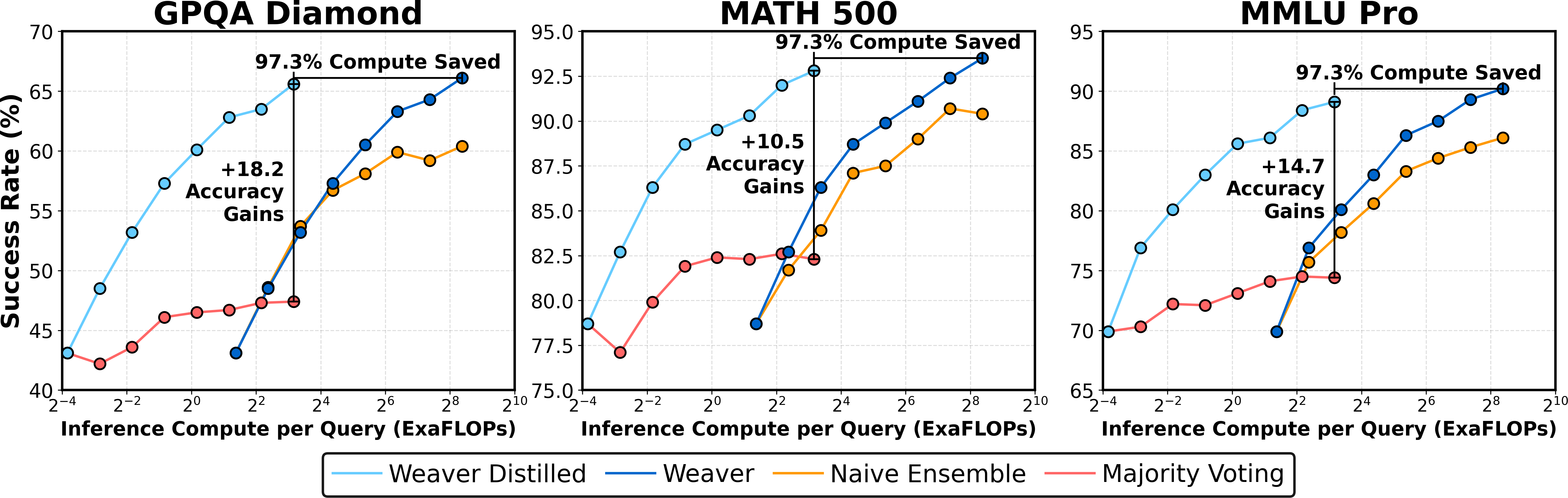
Figure 4: Weaver improves the accuracy-compute trade-off, and distillation enables high accuracy with three orders of magnitude less compute.
Distillation: Efficient Deployment
Weaver's distilled cross-encoder is trained to predict the ensemble's output, enabling efficient deployment. On GPQA Diamond, the distilled model achieves 98.2% of Weaver's accuracy at 0.03% of the compute cost, requiring only a single A100 GPU for inference.
Analysis and Ablations
- Verifier Filtering and Binarization: Pruning low-quality verifiers and adaptive binarization are critical for stability and performance.
- Difficulty-Aware Clustering: Partitioning queries by empirical difficulty and fitting separate WS models per cluster yields further gains, especially for smaller models or highly imbalanced datasets.
- Prompt Optimization: Optimizing LM judge prompts via discrete search (e.g., DSPy) can further reduce false positive rates and improve precision, complementing ensemble aggregation.
Implications and Future Directions
Weaver demonstrates that reliable, scalable verification is achievable without large labeled datasets or specialized verifiers. This has several implications:
- Data Filtering and Model Alignment: Weaver can be used to improve data curation and RLHF pipelines by providing higher-quality labels than individual verifiers.
- Test-Time Compute Scaling: Verification becomes a new axis for scaling LLM performance, orthogonal to model size and number of generations.
- Efficient Deployment: Distillation enables practical deployment of strong verification strategies in resource-constrained settings.
- Extension to Multimodal and Domain-Specific Tasks: Adapting Weaver to multimodal verification or specialized domains (e.g., code, math) is a promising direction.
Conclusion
Weaver provides a principled, label-efficient framework for aggregating weak verifiers, substantially reducing the generation-verification gap in repeated sampling regimes. By leveraging weak supervision, adaptive filtering, and distillation, Weaver achieves strong empirical performance, robust scaling, and efficient deployment. These results suggest that strategic aggregation and distillation of weak verifiers can enable scalable, high-precision verification for LLMs without the need for extensive labeled data or retraining of the base generator.