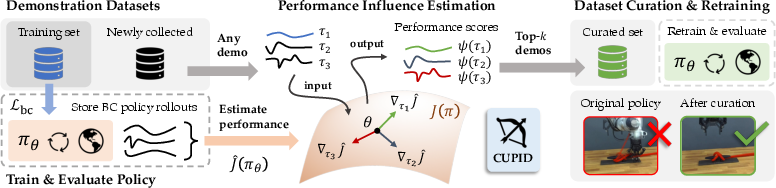
- The paper’s main contribution is a scalable method that uses influence functions to causally attribute demonstration impact on closed-loop policy returns.
- It employs action-level attributions to filter harmful and select beneficial training samples, outperforming traditional heuristic-based approaches.
- Empirical evaluations demonstrate improved policy robustness under distribution shifts and enhanced data efficiency in various robotic tasks.
Influence-Function Data Curation for Robot Imitation Learning: The CUPID Approach
The paper “CUPID: Curating Data your Robot Loves with Influence Functions” (2506.19121) presents a formal and scalable methodology for robot demonstration dataset curation based on influence functions. The approach leverages a precise, action-level attribution mechanism to relate each demonstration’s causal effect on the downstream policy’s closed-loop expected return, facilitating both filtering harmful or redundant samples and selecting trajectories that maximize policy performance.
Motivation and Problem Statement
Policy performance in behavior cloning (BC), and more broadly in imitation learning (IL), depends intricately on not just the overall quality but the exact composition of demonstration data. Current strategies for robot data curation typically rely on task-agnostic heuristics (e.g., mutual information, classifier-based success state metrics), which do not explicitly link training data to closed-loop policy evaluation metrics and can result in misattribution—especially where spurious data correlations exist.
CUPID formalizes robot data curation as the identification of which demonstrations maximally contribute to the policy’s expected return:
- Filter-$k$ Demonstrations: Remove $k$ samples from training set that degrade expected return.
- Select-$k$ Demonstrations: Add $k$ demonstrations into training set to maximize policy return, given a budget.
Evaluation policies are tested via rollouts, aligning estimation with practical robot testing protocols.

Figure 1: CUPID leverages influence functions to answer counterfactual data attribution questions by precisely measuring impact on policy performance.
The core methodological advance is adapting influence function theory (originally for supervised learning, e.g. [koh2017understanding]) to attributing sequential policy decisions. For demonstration $\xi$ and a trained BC policy $\pi_\theta$, the performance influence is defined:
$I(\xi) := \frac{dJ(\pi_\theta)}{d\epsilon}\bigg|_{\epsilon=0} = -\nabla_\theta J(\pi_\theta)^\top H_{\mathrm{bc}}^{-1} \nabla_\theta \ell_{\mathrm{traj}}(\xi; \pi_\theta)$
where $J(\pi_\theta)$ is expected return from policy rollouts, $H_{\mathrm{bc}}$ the Hessian of the BC loss, and $\ell_{\mathrm{traj}}$ is trajectory-level BC loss.
Critically, this influence decomposes into a weighted sum of action influences (at the level of individual state-action pairs) over test rollouts and demonstration transitions:
$I(\xi) = \mathbb{E}_{\tau\sim p(\tau|\pi_\theta)}\left[\frac{R(\tau)}{H} \sum_{(s',a')\in\tau} \sum_{(s,a)\in\xi} a\left((s',a'),(s,a)\right)\right]$
where $a\left((s',a'),(s,a)\right) := -\nabla_\theta \log \pi_\theta(a'|s')^\top H_{\mathrm{bc}}^{-1} \nabla_\theta \ell(s,a; \pi_\theta)$.
Practical Implementation: Diffusion Policy Attribution
In modern robot policy architectures (e.g., diffusion policies [chi2023diffusion]), directly computing log-likelihood gradients is nontrivial due to the denoising generative process. CUPID approximates the log-likelihood gradient with the denoising loss and leverages the Gauss-Newton Hessian and random projection ensemble (TRAK [park2023trak]) for scalable influence estimation. Surrogate loss functions further improve correlation with actual leave-one-out changes in policy behavior.
Implementation specifics:
- For each rollout (success/failure trajectory), compute $I(\xi)$ via action-level influences between all demonstration samples and rollout transitions.
- The top-$k$ removal/select sets are thus chosen by ranking demonstrations by $I(\xi)$.
- The estimator’s accuracy and ranking fidelity are robust for $m \geq 25$ rollouts for most tasks, scaling up to $m \geq 100$ for high-precision, complex tasks (see Figure 2 and Figure 3).
Contrast with Baselines and Ablative Benchmarks
The method is compared against several state-of-the-art and practical baselines:
CUPID exhibits several strong empirical findings:
- Contradictory to common intuition, highest human-quality demonstrations do not always yield the best policy performance (see Figure 5, Figure 6, Figure 7).
- CUPID’s causal attribution allows it to outperform quality-based methods in identifying robust strategies, especially under test-time distribution shift, and in mitigating spurious correlations (Figure 8, Figure 9).
- On tasks with highly redundant data (e.g., RoboMimic LiftMH), aggressive filtering increases performance; on precision-critical tasks (e.g., Figure-8, TuckBox), it avoids the low-variance failures induced by spurious correlations and strategy mode collapse.
Scaling Properties and Computational Considerations
- Influence computation is tractable for datasets up to hundreds of demonstrations (matching policy training cost), and can be batched via random projection and Hessian approximation.
- For large-scale generalist models (e.g., Vision-Language-Action (VLA) policies [black2410pi0]), CUPID-curated single-task datasets improve post-training success, as shown in transfer experiments (Figure 10).
- Estimator variance is suppressed for curation (ranking) compared to reinforcement learning (absolute value) tasks; a relatively small number of rollouts suffices for reliable ranking of helpful/harmful demonstrations.
- Joint demonstration effects (beyond greedy top-$k$ selection) represent a future direction for optimizing set diversity and group interactions.
Flexibility: Hybrid Metrics and Policy Generalization
- CUPID optionally hybridizes its influence signal with heuristic quality metrics for tasks where low variance and predictability are desirable, preserving the ability to ablate or blend signals based on problem specifics (see Figure 11, Figure 12).
- The influence-function framework is architecturally agnostic, supporting attribution in diffusion models, autoregressive policies, or others supporting computation of trajectory-level or action-level gradients.
Implications and Future Directions
Theoretically, the influence-function viewpoint provides a controllable lever for counterfactual analysis (“what-if” removal/addition) of training samples, allowing precise diagnosis and repair of dataset pathologies. Practically, CUPID’s curation can improve robot data efficiency, policy robustness under distribution shift, and generalization, especially as demonstration datasets continue to scale in diversity and volume.
Further advances will focus on:
- Joint set optimization for diversity.
- Reducing computational overhead for large robot data corpora.
- Extending beyond passive curation to active dataset explanation and collection guidance.
Conclusion
CUPID advances data curation for robot imitation learning by directly causally attributing closed-loop policy performance to individual demonstrations via scalable influence function methods. Empirical results show strong improvements over baselines, robustness to distribution shift, and effective mitigation of spurious correlations, even when using a fractional subset of the original data. This methodology is broadly applicable to curation in both single-task and generalist robotic policy training, and represents a foundational step toward trustworthy, systematic robot data valuation and selection.
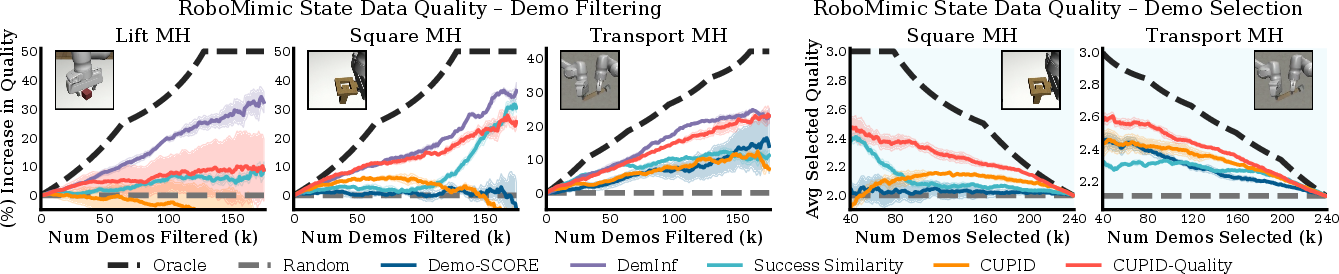
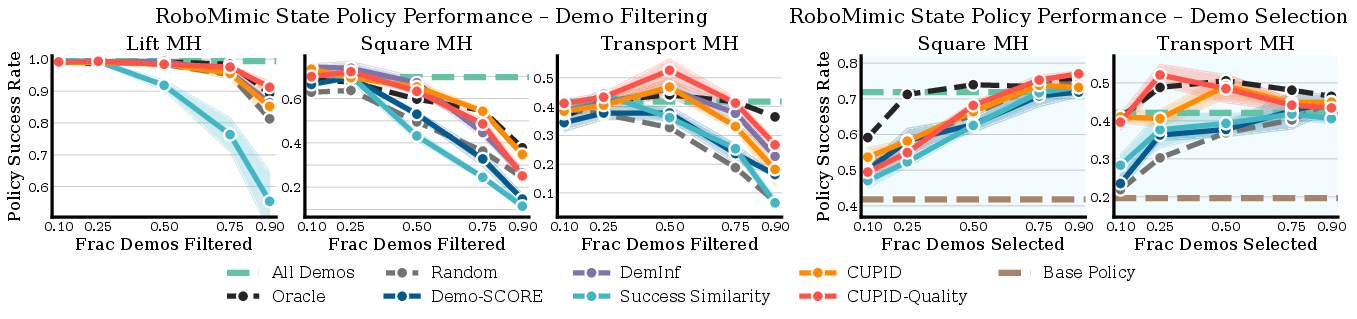
Figure 5: CUPID-curated policies outperform baselines on RoboMimic mixed-quality curation benchmarks, demonstrating that perceived demonstration quality does not always maximize success.


Figure 8: Franka real-world robot policy performance demonstrates CUPID’s ability to filter brittle or spurious strategies while increasing overall robustness.

Figure 2: Rollout ablation: estimation of demonstration influence stabilizes with modest numbers of rollouts, supporting practical scalability.
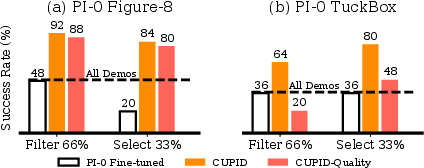
Figure 10: Transfer learning: datasets curated for single-task policies improve post-training performance for generalist $\pi_0$ models.