- The paper presents the COCUS framework that decouples segmentation and classification to better localize camouflaged objects.
- It employs a modified SAM integrated with CLIP-derived prompts to enhance edge detection and segmentation precision in low-contrast conditions.
- Experimental results demonstrate state-of-the-art performance, validating the cascaded, region-aware strategy across challenging benchmarks.
COCUS: Cascaded Open-Vocabulary Camouflaged Object Understanding Network
This paper introduces a novel two-stage framework, named Cascaded Open-vocabulary Camouflaged UnderStanding network (COCUS), for Open-Vocabulary Camouflaged Object Segmentation (OVCOS). The approach addresses the challenges of segmenting and classifying camouflaged objects from arbitrary categories, focusing on scenarios with visual ambiguity and unseen classes. The framework leverages a Vision LLM (VLM)-guided approach, specifically using a modified Segment Anything Model (SAM) and CLIP, to enhance segmentation and classification accuracy.
Background and Motivation
OVCOS presents unique difficulties due to the low contrast, indistinct boundaries, and high similarity between camouflaged objects and their backgrounds. Existing methods often rely on generic segmentation models that are not optimized for camouflaged objects, leading to imprecise localization. One-stage methods using VLMs for pixel-wise classification suffer from granularity mismatch, as VLMs are pre-trained for image-level understanding. Two-stage methods, which first segment and then classify, still face challenges in the segmentation stage due to the limitations of generic models.
Proposed Methodology
The COCUS framework addresses these issues by explicitly decoupling segmentation and classification into two cascaded stages. (Figure 1) illustrates the overall architecture, highlighting the flow of information between the segmentation and classification stages.
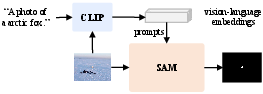
Figure 1: Overview of the cascaded segment and classify framework.
Stage 1: VLM-Guided Segmentation
In the first stage, the framework employs an adapted SAM model, guided by visual and textual embeddings from CLIP, to generate a class-agnostic segmentation mask. This involves integrating CLIP-derived features as prompts to SAM, which enhances attention to camouflaged regions and improves localization accuracy. The mask decoder is enhanced with conditional multi-way attention and an edge-aware refinement module to improve boundary precision. (Figure 2) shows the difference between using a generic segmentation model and visual-language prompted segmentation.
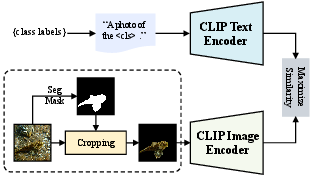
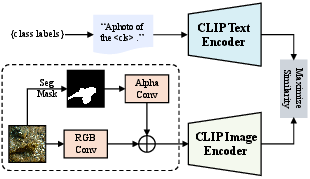
Figure 2: Comparison of mask-guided classification strategies.
Stage 2: Region-Aware Open-Vocabulary Classification
The second stage focuses on open-vocabulary classification using the segmentation output as a soft spatial prior. Instead of hard cropping the segmented regions, the framework treats the segmentation output as an alpha channel, retaining the full image context while providing precise spatial guidance. This approach mitigates the domain gap caused by the mismatch between VLMs' full-image training and cropped-region inference. The same VLM is shared across both stages to ensure efficiency and semantic consistency.
CLIP Fine-Tuning Pipeline
To enhance the sensitivity of CLIP to camouflaged objects, the framework fine-tunes CLIP using a multi-modal prompting strategy, jointly optimizing visual and textual prompts. (Figure 3) illustrates this fine-tuning pipeline, detailing how textual prompts are appended to the language branch and visual prompts are injected into the vision branch.
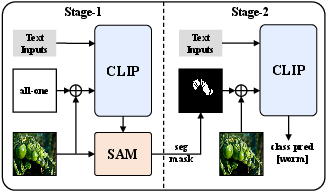
Figure 3: Overview of the cascaded segment and classify framework.
This process enhances semantic alignment and task-specific adaptability, enabling region-aware classification without disrupting global semantics. The visual and textual embeddings are processed to compute similarity scores, which are then used to calculate a cross-entropy loss against ground-truth class labels.
Experimental Results
The authors conducted extensive experiments on both OVCOS and conventional camouflaged object segmentation benchmarks. On the OVCamo dataset, the COCUS framework achieved state-of-the-art performance, surpassing existing methods across multiple evaluation metrics, including cSm, cFβw, cMAE, cFβ, cEm, and cIoU. The adapted SAM also demonstrated strong performance on the conventional COS task, validating the effectiveness of the framework across both open- and closed-set camouflaged segmentation scenarios. Qualitative results (Figure 4) further illustrate the framework's ability to accurately delineate camouflaged objects with well-preserved shapes and precise boundaries, even in low-contrast and cluttered backgrounds.

Figure 4: Qualitative comparison between our method and CLIP-based baselines on OVCamo.
Ablation studies validated the effectiveness of the fine-tuned CLIP model and the contributions of the Conditional Multi-Way Attention (CMA) and Edge Enhancement (EDE) modules in the adapted mask decoder.
Discussion
The paper highlights the significance of leveraging rich VLM semantics for both segmentation and classification of camouflaged objects. By explicitly decoupling segmentation and classification and using prompt-based guidance, the COCUS framework achieves more accurate semantic interpretation of camouflaged objects. The region-aware classification strategy, which avoids hard cropping, is crucial for mitigating the domain gap and improving classification accuracy.
Conclusion
The COCUS framework presents a significant advancement in OVCOS by addressing the limitations of existing methods and achieving state-of-the-art performance on challenging benchmarks. The framework's cascaded design, VLM-guided segmentation, and region-aware classification strategy offer a robust solution for segmenting and classifying camouflaged objects from arbitrary categories. The results confirm the benefits of the two-stage framework and edge-aware enhancements in complex camouflage scenarios. Future research could explore the application of this framework to other open-vocabulary tasks and investigate the use of more advanced VLMs for further performance improvements.