- The paper proposes TTSDS2, a novel metric that uses the 2-Wasserstein distance to measure distribution similarity between synthetic and real speech.
- It incorporates four perceptual factors—generic, speaker, prosody, and intelligibility—and is validated across 14 languages.
- The metric achieves an average Spearman correlation of 0.67 with human evaluations, providing a robust alternative to subjective MOS tests.
TTSDS2: Resources and Benchmark for Evaluating Human-Quality Text to Speech Systems
Introduction
The evaluation of Text to Speech (TTS) systems presents significant challenges, especially with the advent of systems capable of generating speech indistinguishable from human speech. Traditional subjective metrics, such as the Mean Opinion Score (MOS), although prevalent, are inconsistent across various studies, driving a need for objective metrics that consistently correlate with human evaluations. This study introduces the Text-to-Speech Distribution Score 2 (TTSDS2), an advanced and robust metric for evaluating TTS systems, designed to maintain high correlation with human evaluations across diverse domains and languages.
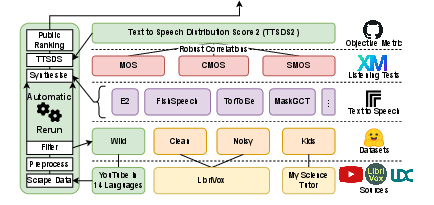
Figure 1: Overview of TTSDS2, utilizing a diverse collection of public and academic datasets for validation across multiple domains.
TTSDS2 Methodology and Features
The methodology behind TTSDS2 is rooted in measuring distributional similarity to real speech rather than individual sample comparisons, effectively addressing the inherent one-to-many nature of TTS tasks. TTSDS2 comprises four primary perceptual factors: Generic, Speaker, Prosody, and Intelligibility. Each factor derives scores based on multiple features such as SSL embeddings for generic similarity, speaker identity fidelity, pitch and rhythm for prosody, and ASR-derived features for intelligibility.
Figure 2 provides a visual representation of these features and their distributions, focusing on the feature-wise distances between synthetic and real speech datasets.
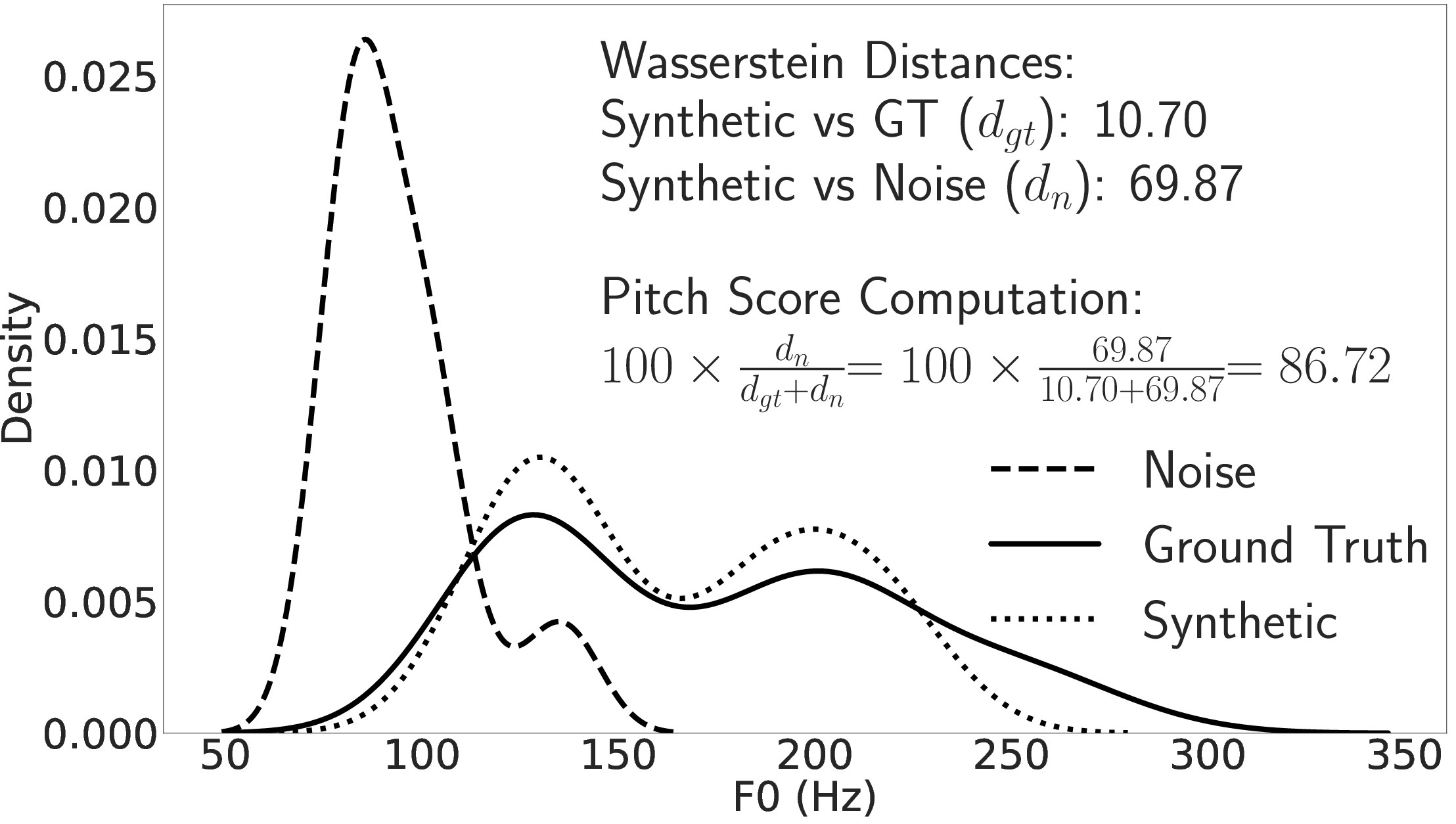
Figure 2: Distribution of F0 in TTSDS for ground-truth, synthetic, and noise datasets.
The computation employs the 2-Wasserstein distance, a robust metric known for its properties suited to distribution comparison tasks.
Multilingual Application and Continuous Evaluation
To ensure TTSDS2's applicability beyond English, the methodology was extended to a multilingual context, incorporating 14 languages and involving a process of continuous quarterly benchmarking. This ensures the metric remains up-to-date with the latest advancements in TTS technology and dataset diversity. The multilingual process involves a curated pipeline for data collection and evaluation, minimizing data leakage and ensuring that the evaluation reflects real-world conditions.
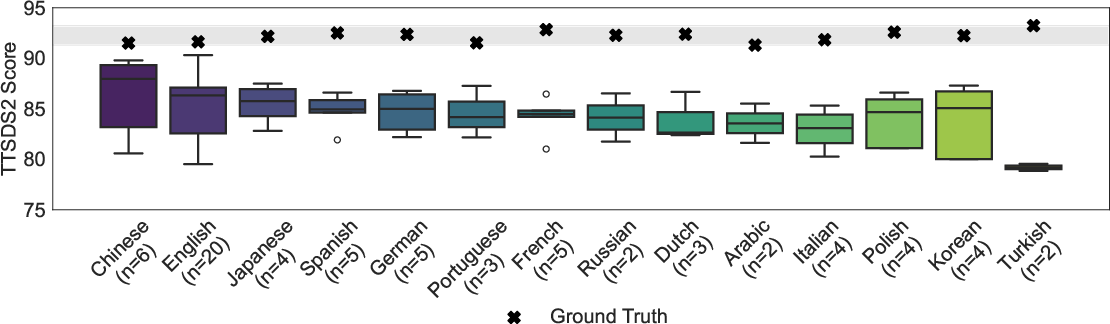
Figure 3: TTSDS2 scores across 14 languages.
Correlation with Human Evaluations
TTSDS2 has been rigorously evaluated against human listening tests, consistently achieving a Spearman correlation exceeding 0.5 across all domains, with average correlations around 0.67. Such high correlation indicates TTSDS2's robustness and reliability in replicating human judgments of TTS output quality.
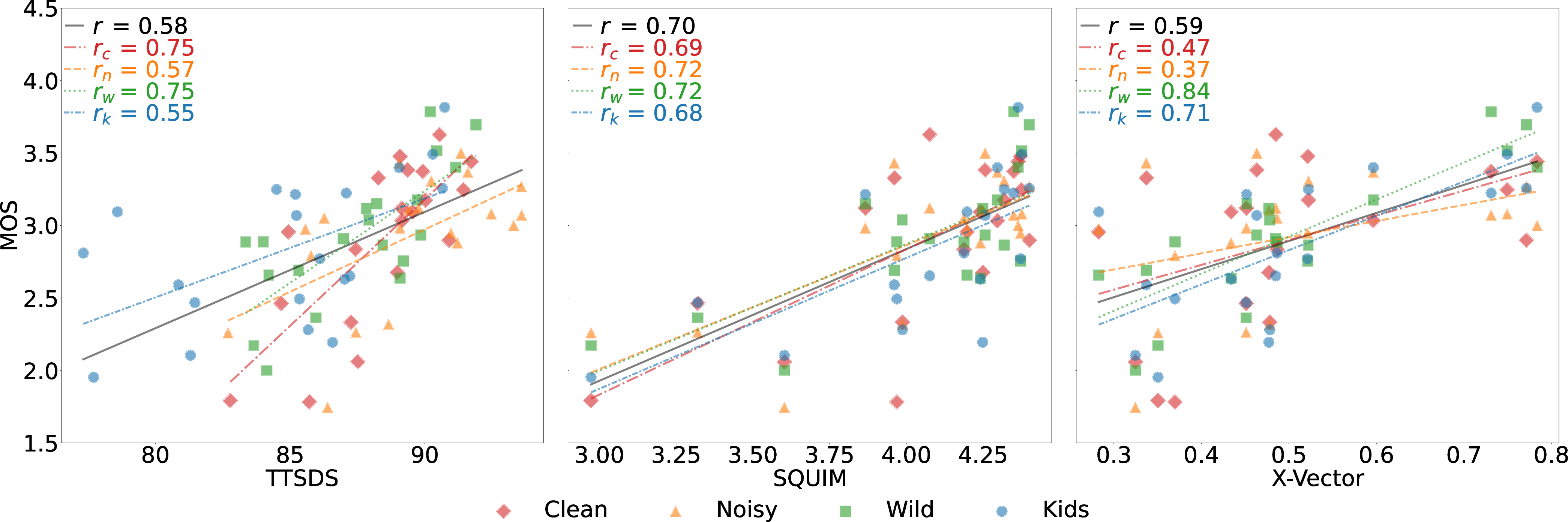
Figure 4: Correlation of three representative objective metrics with human MOS across the four datasets.
Limitations and Future Directions
Despite its advantages, TTSDS2's computational intensity could be a limitation, particularly when compared to simpler, less demanding metrics. Additionally, while it does not fully replace subjective listening tests, it serves as a highly reliable proxy. Future work may focus on reducing computational overhead and exploring further the uses of TTSDS2 in detecting more complex failure modes of TTS systems, such as nuanced contextual errors.
Conclusion
TTSDS2 represents a significant step forward in the objective evaluation of TTS systems, providing a more consistent and reliable metric correlated with human subjective evaluation across a wide array of domains and languages. By continuing to update and expand the benchmarking framework, TTSDS2 stands to significantly impact the development and refinement of future TTS technologies, ensuring they meet the ever-higher standards of linguistic and perceptual quality required by end-users.

