- The paper introduces a norm-aware linear attention mechanism that decouples query norms to effectively manage entropy.
- It employs a novel kernel design with cosine inhibition to enforce non-negativity and achieve up to 4.2% improvement on various tasks.
- Experimental results highlight enhanced accuracy, lower perplexity, and efficient FLOPs curves in both vision and language applications.
Introduction
The "NaLaFormer: Norm-Aware Linear Attention for Transformer Models" (2506.21137) paper introduces a novel approach to enhance the efficiency and expressiveness of transformer models using linear attention mechanisms. The key innovation lies in addressing the limitations of existing linear attention frameworks, specifically the neglect of query norms and the inhibition of negative values in query and key vectors. These deficiencies often result in high entropy, limiting the model's ability to focus on critical tokens. To overcome these challenges, the authors propose the Norm-Aware Linear Attention (NaLaFormer), which incorporates norm-directed control over spikiness and recovers norm-perturbed distributions, thus maintaining both computational efficiency and expressiveness.
Methodology
Decoupling and Norm Awareness
NaLaFormer introduces a Norm-Aware Linear Attention mechanism by decoupling query and key matrices into norm and direction components. This decoupling facilitates norm-aware spikiness control and norm consistency. The mathematical analysis reveals the variability of entropy reduction with query norms within softmax normalization, prompting the development of a query-norm aware kernel function. By employing a norm-preserving mapping, positive value constraints are enforced, utilizing cosine similarity to manage dimensions with opposite directions.


Figure 1: Visualizations of correlation between entropy and vector norm. We visualize two critical properties of the feature map: entropy and vector norms.
Kernel Design and Cosine Inhibit
The paper proposes a novel kernel function that relies on power functions adapted to capture query norm dynamics while preserving non-negativity. The power function introduces norm awareness into linear attention mechanisms, ensuring expressive spikiness and facilitating dynamic entropy adjustments. Additionally, the cosine inhibit method is employed to maintain all features in positive domains, significantly reducing computational overhead typically associated with extended vector decompositions or negative value suppression techniques.
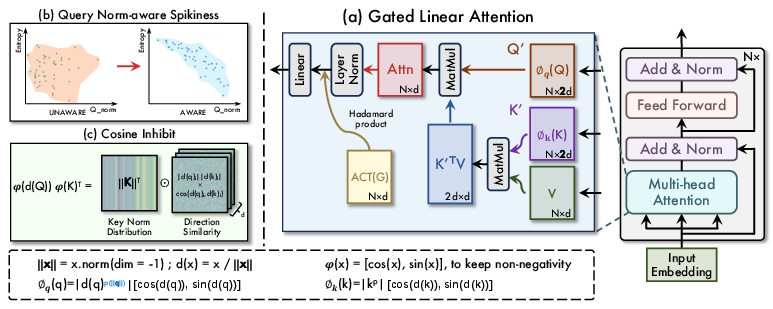
Figure 2: The overall framework of NaLaFormer. Our NaLaFormer block utilizes a simplified GLA architecture with a designed kernel function.
Experimental Results
NaLaFormer demonstrates performance improvements of up to 4.2% on various vision and language tasks, including ImageNet-1K classification and COCO segmentation. The efficiency analysis reveals favorable accuracy versus FLOPs curves, highlighting NaLaFormer’s balanced trade-off between performance and computational demand. In language modeling, NaLaFormer achieves lower perplexity and higher accuracy, outperforming both linear and softmax-based models across commonsense reasoning benchmarks.
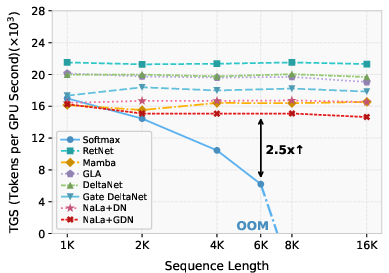
Figure 3: Comparison on training throughput of 340M models on a single A6000 GPU.
Conclusion
This work presents NaLaFormer as a compelling solution to the limitations encountered with conventional linear attention methods in transformer models. By integrating norm-awareness into the entropy management of query norms and ensuring non-negativity through cosine inhibition, NaLaFormer enhances both the performance and efficiency of attention mechanisms across vision and language tasks. The proposed framework not only surpasses existing linear attention models in expressiveness and computational cost but also provides a robust platform for further explorations in high-dimensional data understanding and processing within transformer architectures.
Future research efforts may focus on extending NaLaFormer’s applicability to more complex generative modeling tasks and addressing theoretical insights concerning the nuances of norm-directed self-attention dynamics in various contexts.