- The paper introduces an LLM-enhanced method that integrates action triplet prompts with CLIP to capture fine-grained action semantics for image-text matching.
- Multi-modal prompt tuning and an adaptive interaction module refine visual-text alignment, demonstrating significant improvements in retrieval metrics on COCO and Flickr30K.
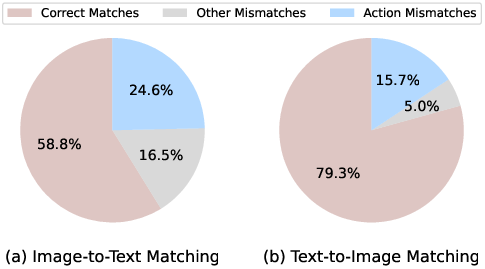
- Experimental results showcase enhanced R@1, R@5, and R@10 performance, validating the method's capability to mitigate action-level mismatches in complex scenarios.
LLM-enhanced Action-aware Multi-modal Prompt Tuning for Image-Text Matching
Introduction
The paper "LLM-enhanced Action-aware Multi-modal Prompt Tuning for Image-Text Matching" presents a novel approach to improving image-text matching leveraging the capabilities of LLMs and CLIP. This method addresses the limitations of traditional CLIP models, particularly their inability to grasp fine-grained action-level semantics crucial for aligning images and text. The authors introduce a technique that integrates action-related knowledge derived from LLMs into the CLIP framework via multi-modal prompt tuning to enrich the semantic understanding of actions and enhance image-text matching tasks.


Figure 1: Image-to-Text Matching.
Methodology
The proposed method enhances CLIP by introducing LLM-generated action triplets and state awareness, which are then embedded into the multi-modal framework through designed prompts. The process involves several critical steps:
- Action Knowledge Generation: Utilizing the in-context learning capabilities of GPT-3.5, the system generates action triplets and state descriptions. These are used to construct prompts that represent fine-grained action semantics implicitly stored within LLMs. Each prompt is infused with detailed compositional and causal information about object actions.
- Multi-modal Prompt Tuning: The methodology injects action triplet prompts and action state prompts into the image encoder. These prompts are tailored to guide the encoder to focus on significant action cues within the visual content, effectively bridging the gap between high-level textual instructions and the visual representations drawn by CLIP.
- Adaptive Interaction Module: This module enhances feature extraction by focusing only on salient action cues relevant to the visual content, thereby reducing noise and irrelevant information interference. It facilitates adaptive alignment between visual and textual representations conditioned on action-aware prompted knowledge.
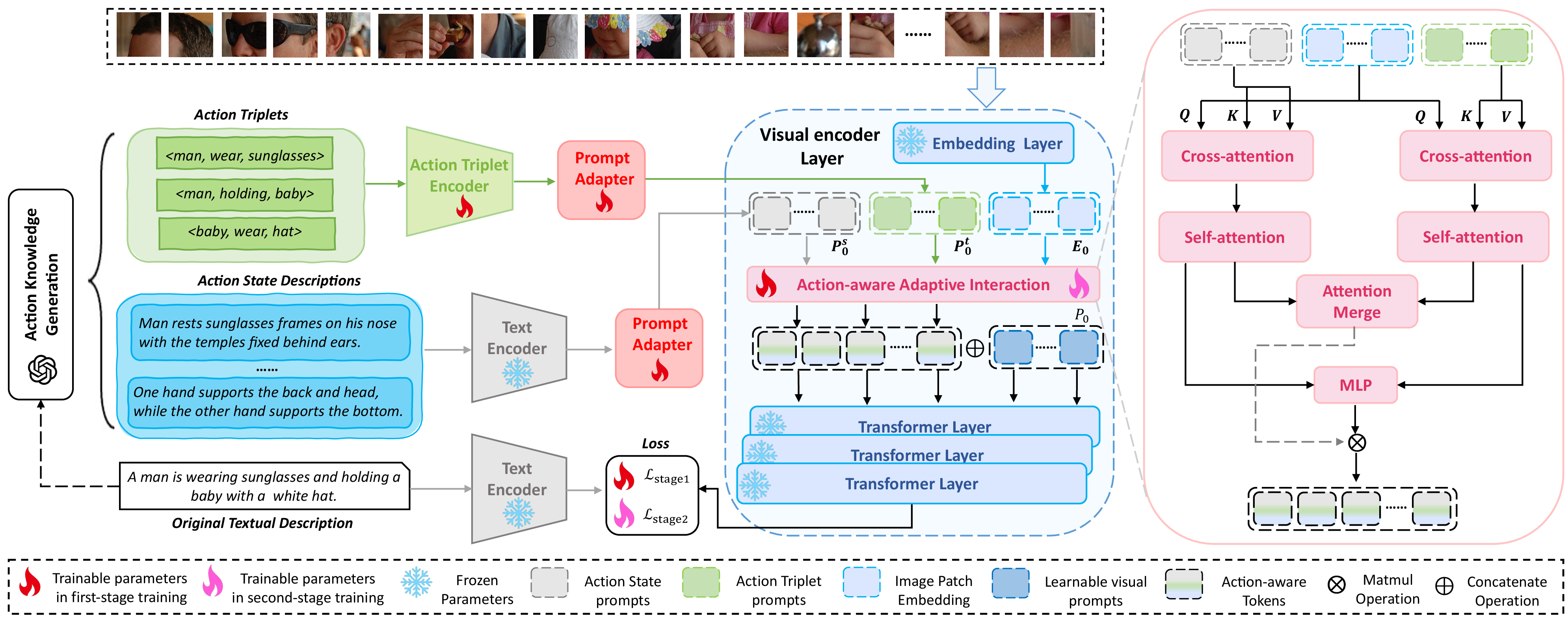
Figure 2: Overview of the proposed method.
Experimental Results
Experiments conducted on the COCO and Flickr30K datasets demonstrate the method's efficacy. The proposed system outperforms existing methods on standard benchmarks by significantly improving retrieval accuracy. The metrics reveal robust performance in both image-to-text and text-to-image retrieval tasks, attributed to the enhanced action-aware patterns captured in the learned embeddings.
Implementation Considerations
Implementing this method requires access to powerful LLMs like GPT-3.5 or its successors for generating action-related prompts. The integration into existing CLIP architectures demands modifications in prompt handling and interpretation to accommodate action-specific data. Additionally, the adaptive interaction module necessitates careful tuning of hyperparameters to balance between action-related and general visual information.
Future Directions
The integration of LLMs into vision-language tasks opens avenues for further exploration of context-specific interactions and learning paradigms. Extending this approach to more dynamic datasets involving temporal actions in videos could leverage action-aware perceptions for broader applications including video-text matching and action recognition. Moreover, improving LLM prompt designs could further bridge semantic gaps in other AI-driven multi-modal tasks.
Conclusion
The paper contributes a significant advancement in image-text matching by leveraging the strengths of LLM-enhanced prompting techniques. By addressing the limitations of traditional image-text encoders in action perception, this research paves the way for more sophisticated integration of LLMs with visual understanding systems. This enhancement promises improvements in various applications within the multi-modal domain, utilizing fine-grained action knowledge to better contextualize and align images with textual descriptions.