- The paper introduces neuron-centric model fusion that leverages neuron attribution scores to align and integrate models from different data distributions.
- It employs clustering techniques to group neurons and optimizes both linear and non-linear layers to minimize approximation errors.
- Experiments on VGG11 and ViT architectures demonstrate superior performance in zero-shot and non-IID scenarios with theoretical matching guarantees.
Model Fusion via Neuron Interpolation
Introduction
The paper "Model Fusion via Neuron Interpolation" explores an innovative, neuron-centric approach to model fusion, aiming to synthesize multiple trained neural networks into a unified model. This method stands out by leveraging neuron attribution scores, allowing for effective integration of models trained on different data distributions. The proposed algorithms show improved performance in benchmarks over previous model fusion techniques, particularly in challenging zero-shot and non-IID fusion scenarios.
Core Contributions
The paper introduces several key contributions that differentiate the proposed approach from existing techniques:
- Neuron-Centric Fusion: The approach formulates fusion as a representation matching problem, decomposing it into grouping and approximation components. This structured method offers a systematic way to align neuron representations across models.
- Incorporating Neuron Importance: By incorporating neuron attribution scores, the method biases the fusion process to preserve important features, leading to better alignment and performance. This involves weighting neurons based on their importance, significantly impacting the fusion outcome.
- Generalization Across Architectures: Unlike many existing methods limited to specific architectures, the algorithms presented can generalize to arbitrary network types, enhancing their applicability across various domains.
Technical Implementation
The implementation is structured into a two-step procedure. Initially, neuron outputs are clustered using techniques such as Lloyd's algorithm or Hungarian Matching to minimize grouping error. Next, approximation error is minimized through either closed-form solutions for linear layers or stochastic gradient descent for non-linear layers.
Code Example:
1
2
3
4
5
6
7
8
9
10
11
|
def neuron_interpolation_fusion(models, data, importance_scores):
for level in range(num_levels):
outputs = [model.get_outputs(data, level) for model in models]
scores = importance_scores[level]
# Group neurons with K-means or Hungarian Matching
clusters, cluster_centers = cluster_neurons(outputs, scores)
# Optimize model weights to match cluster centers
for cluster in clusters:
optimize_weights(cluster, cluster_centers) |
Experimental Analysis
The algorithms were rigorously tested on VGG11 and ViT architectures across various data splitting regimes, including non-IID and sharded partitions. A consistent finding was the superior performance of the proposed method not only in handling standard datasets but also under stress-test conditions with disparate data distributions.
Results Summary:
- Zero-Shot Fusion: The method maintains competitive performance without requiring post-fusion retraining, reflecting its robustness.
- Non-IID Performance: On non-IID data, the method outperforms traditional ensembling and existing fusion algorithms.
- Sharded Data Handling: Demonstrates robustness in scenarios with extreme class distribution disparities.
Theoretical Guarantees
The method provides theoretical guarantees for optimality in one-to-one matching scenarios via Hungarian Fusion, and approximation bounds for more general configurations through K-means Fusion, leveraging local-search algorithms with proven approximation ratios.
Conclusion
This research contributes a robust, versatile approach to model fusion, applicable across a wide range of neural network architectures and data distributions. The introduction of neuron importance scores into the fusion process represents a notable advancement, facilitating the construction of fused models that closely match or exceed the performance of individual base models. Future work could explore automated hyperparameter tuning, adaptive level definitions, and the role of fusion in network compression.
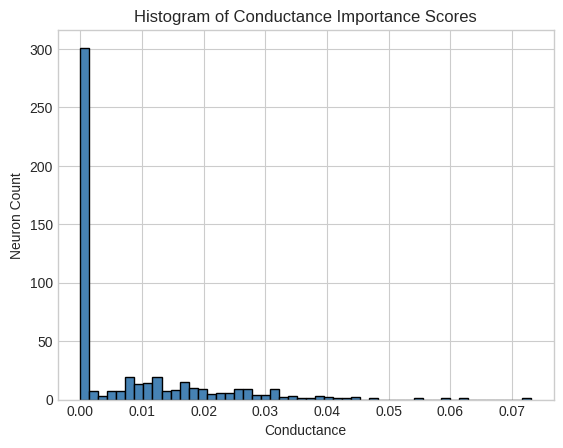
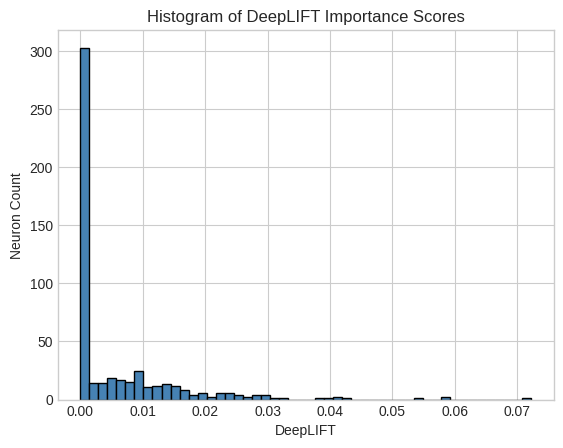
Figure 1: Histogram of Conductance and DeepLIFT Importance Scores illustrating the distribution of neuron importance.