- The paper introduces Lift to Match (L2M) that lifts 2D images into 3D space via a two-stage framework to enhance dense feature matching.
- It employs a 3D-aware encoder using multi-view synthesis and a robust decoder that generates synthetic views for varied conditions.
- Experimental results demonstrate that L2M outperforms state-of-the-art methods in accuracy across diverse, challenging real-world scenarios.
Summary of "Learning Dense Feature Matching via Lifting Single 2D Image to 3D Space"
Introduction
Dense feature matching is integral to computational vision technologies, especially in the domains of 3D reconstruction, visual localization, and robotics navigation. Traditional methodologies for feature matching rely on multi-view datasets which restrict scalability due to their requirement for controlled environments and extensive data collections. The proposed research introduces a framework, Lift to Match (L2M), which leverages large-scale single-view datasets, transforming them into 3D environments to improve feature recognition and matching significantly.
Methodology
Two-Stage Framework
L2M operates through a two-stage process:
- 3D-Aware Encoder Learning: The first stage involves synthesizing multi-view images from single 2D pictures. This is achieved by infusing the encoder with 3D geometry knowledge via processing with 3D feature Gaussians, enabling the feature encoder to retain multi-view perception capabilities. By building feature representations informed by 3D structures, the encoder is well-equipped to handle complexities such as occlusions and geometric distortions in view alignment.
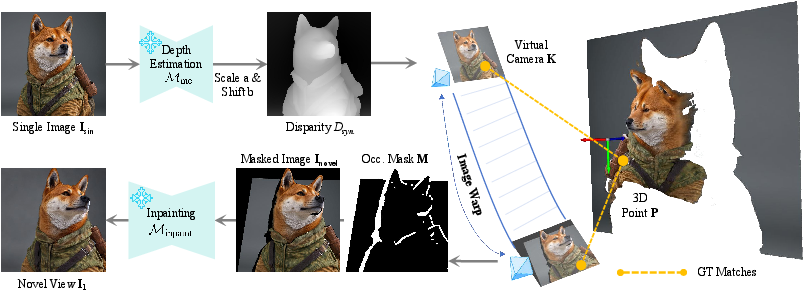
Figure 1: Illustration of our proposed novel-view synthesis strategy via lifting single-view 2D images to 3D space with monocular depth estimation and inpainting, which unlocks the potential for training dense feature matching networks using large-scale, diverse data.
- Robust Decoder Learning: The second stage employs novel image rendering strategies, incorporating generated synthetic views from varying perspectives and lighting conditions. Utilizing monocular depth estimation, the framework generates expansive datasets capturing diverse scenes and inconsistencies in real-world settings, thereby enabling improved learning for robust feature matching.
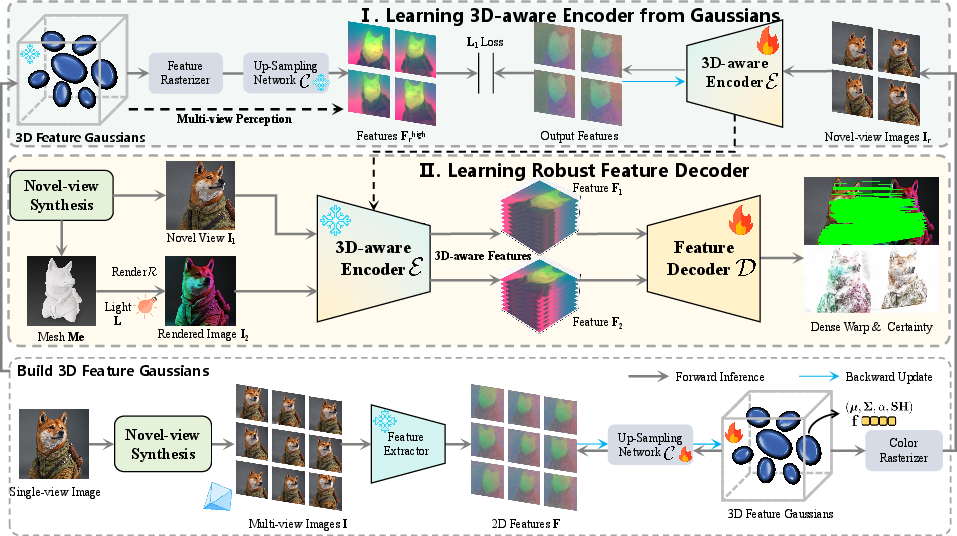
Figure 2: Illustration of our two-stage framework. In the first stage, the 3D-aware feature encoder learning process utilizes multi-view synthesis and 3D feature Gaussians to transfer 3D geometry knowledge into the encoder. In the second stage, the robust feature decoder learning process utilizes large-scale, easy-to-collect single views with re-rendering strategy, providing much more diverse data for training.
Implementation
Depth estimation models are integral to lifting 2D images into 3D space, which are subsequently processed to create diverse synthetic datasets for learning feature matching under varying conditions. A notable component is the development of point clouds from 2D pixel datasets, which are used to construct 3D meshes applicable in novel-view rendering.
Experimental Results
Extensive experimentation validates L2M's effectiveness across various benchmarks, outperforming state-of-the-art techniques in zero-shot evaluations. This includes broad-ranging datasets with significant environmental and lighting discrepancies, wherein L2M shows superior generalization capabilities. Performance metrics demonstrate enhanced accuracy across datasets, reinforcing L2M’s adaptiveness to dynamic real-world scenarios.

Figure 3: Example of generated image pairs. The first row shows the original single-view images after re-lighting and re-rendering. The second row shows the generated novel-view images.
Implications and Future Work
The implications of L2M extend into practical applications forecasting enhanced computational vision capabilities that circumvent the limitations of traditional feature matching paradigms. The research suggests further exploration into extending 3D-aware learning mechanisms and expanding synthetic dataset generation will refine feature matching models. The prospect of integrating AI-driven monocular depth estimation expands possibilities for real-time feature correspondence across disparate visual environments.





Figure 4: Qualitative comparison with dense feature matching methods \cite{edstedt2023dkm, shen2024gim, edstedt2024roma}.
Conclusion
L2M presents substantial advancements in dense feature matching by leveraging the strengths of single-view 2D images transformed into dynamic 3D settings. Through a detailed framework incorporating novel-view synthesis and robust decoder learning processes, it surpasses existing technologies in terms of computational efficiency and applicability to diverse real-world conditions. Future studies may build on these promising methodologies, further challenging the domain-specific constraints inherent to traditional computer vision approaches.