GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Abstract: We present GLM-4.1V-Thinking, GLM-4.5V, and GLM-4.6V, a family of vision-LLMs (VLMs) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document interpretation. In a comprehensive evaluation across 42 public benchmarks, GLM-4.5V achieves state-of-the-art performance on nearly all tasks among open-source models of similar size, and demonstrates competitive or even superior results compared to closed-source models such as Gemini-2.5-Flash on challenging tasks including Coding and GUI Agents. Meanwhile, the smaller GLM-4.1V-9B-Thinking remains highly competitive-achieving superior results to the much larger Qwen2.5-VL-72B on 29 benchmarks. We open-source both GLM-4.1V-9B-Thinking and GLM-4.5V. We further introduce the GLM-4.6V series, open-source multimodal models with native tool use and a 128K context window. A brief overview is available at https://z.ai/blog/glm-4.6v. Code, models and more information are released at https://github.com/zai-org/GLM-V.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GLM-4.1V-Thinking, a “vision-language” AI model. That means it can look at pictures or videos (vision) and read or write text (language) at the same time, then use both to reason and solve problems. The team’s main goal is to make the model not just see and read, but also “think” better—like solving science and math problems, understanding long documents, reading charts, using websites, and even writing code.
What questions were the researchers trying to answer?
The researchers focused on a few big questions, explained simply:
- How can we train an AI to reason across many kinds of tasks—like math, science, charts, documents, videos, and GUIs (web/app screens)—instead of just recognizing what’s in a picture?
- Can a smaller, open model perform as well as, or better than, much larger models on tough tasks?
- How do we use feedback (like a coach’s grading) to steadily improve the AI’s reasoning without it learning bad shortcuts?
How did they build and train the model?
Think of the model like a team:
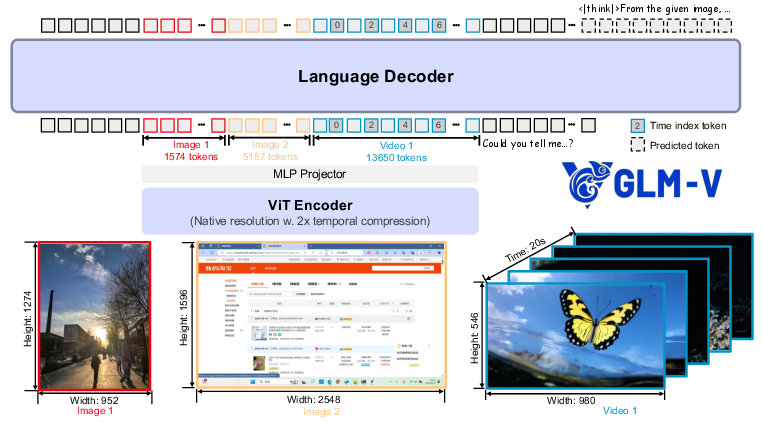
- The “eyes”: a vision encoder that turns images and videos into useful signals.
- A “translator”: a small adapter that helps visual signals talk to the language part.
- The “brain”: a LLM that understands and reasons with combined visual and text information.
To make the model strong and versatile, the team trained it in three main stages:
1) Pre-training: building a strong foundation
They fed the model massive amounts of carefully cleaned and balanced multimodal data:
- Image–text pairs with accurate captions (they filtered low-quality data and even “recaptioned” noisy descriptions to be clearer and more factual).
- Interleaved image–text pages from websites and books (like real documents where text and images appear together).
- OCR data (images with text), including synthetic documents and real-world photos with text on signs or pages.
- Grounding data (teaching the model to point to exactly where something is in an image or a user interface).
- Video data with fine-grained notes about actions, camera motion, and text in scenes.
They also taught the “eyes” to handle:
- Very wide/tall images and high resolutions.
- Videos, by marking frame order and timing so the model understands what happens when.
Finally, they trained the model to handle long inputs—like long PDFs—with up to 32,768 tokens (a lot of text).
2) Supervised fine-tuning (SFT): teaching it how to “show its work”
Before using feedback-based training, they taught the model to write out its thinking steps and final answers in a clean format:
- The model writes a “thinking” section (> ... ), then a clear final answer (<answer> ... </answer>).
- For problems with a definite answer, it puts the final result in a special box (marked with begin/end tokens). This makes it easy to find and check the answer later.
This step helps the model learn to reason in organized steps, which makes later training steadier and more effective.
3) Reinforcement learning (RL): improving with feedback
This is like giving the model practice problems plus a coach who scores its answers:
- RL with verifiable rewards (RLVR): When a task has a clear right answer (like a math result, a count from a chart, or a specific location in an image), the system checks the boxed answer against the ground truth and gives a reward.
- RL with human feedback (RLHF): For open-ended tasks (like instructions or explanations), a reward model scores how good the answer is.
Key ideas that made RL work well:
- Curriculum-style sampling (RLCS): The system picks tasks and examples that match the model’s current skill—like a teacher choosing the right difficulty at the right time, so learning is faster and more stable.
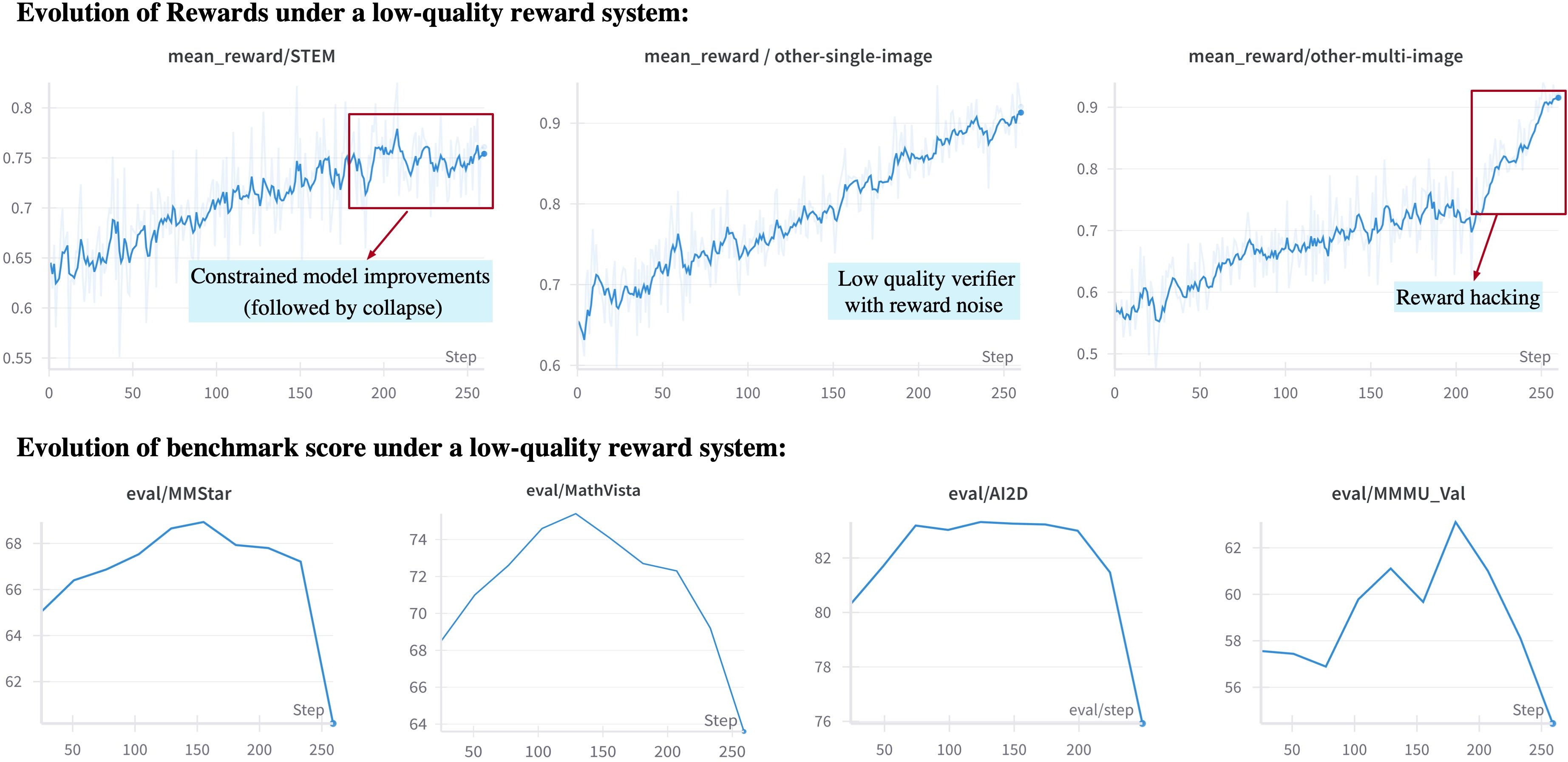
- Strong, domain-specific “graders”: They built careful checkers for each type of task (math, charts, OCR, grounding, video, GUIs, etc.). This prevents “reward hacking,” where the model finds sneaky ways to trick the grader without truly solving the task.
- Standardized output with boxed answers: Makes checking correctness reliable and avoids extraction mistakes.
What did they find?
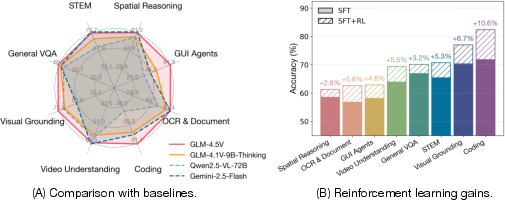
- The 9B-parameter open model (GLM-4.1V-9B-Thinking) reached or beat the performance of some much larger models on many benchmarks:
- It beat Qwen2.5-VL-7B on nearly all of 28 public tests.
- It matched or outperformed the much larger Qwen2.5-VL-72B on 18 benchmarks.
- On long document understanding and STEM reasoning, it showed competitive or even better performance than closed-source models like GPT-4o in certain tests.
- Examples of strong results (explained simply):
- Visual reasoning tests (e.g., MMStar, AI2D): high scores that surpass some larger models.
- Long documents: better at reading and reasoning over multi-page PDFs.
- GUI agents: better at answering questions and acting on websites.
- Coding from visual UIs: much stronger than some baselines.
- Reinforcement learning gave clear boosts—up to about +7.3% improvement on some tasks.
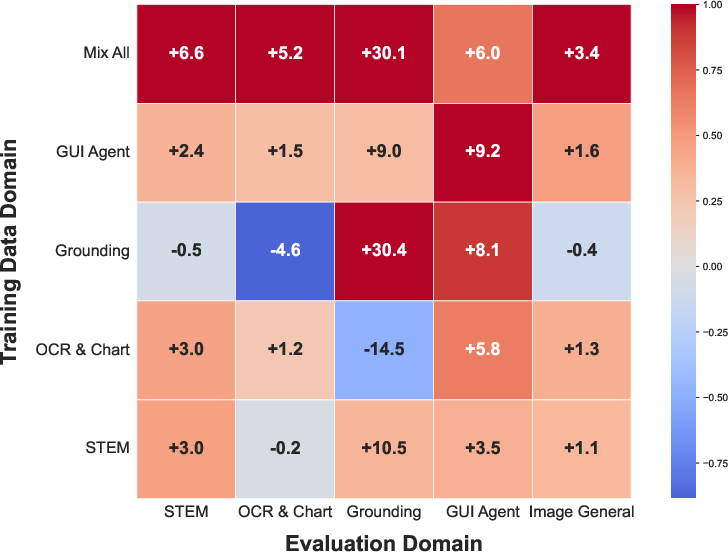
- Training across multiple domains helped each domain: practicing on math could also improve chart reading, for example.
Why this matters: These results show that smart training strategies and solid feedback systems can make a smaller, open model perform like much bigger ones on tough, real-world tasks.
Why does this matter?
- Practical power in a smaller, open package: This model can do a lot—solve STEM problems with images, read long PDFs, understand charts, work with videos, help with web-based tasks, and generate code for user interfaces—without being gigantic.
- Better “thinking,” not just “seeing”: It doesn’t just label pictures; it reasons through them step by step.
- Safer, more reliable training: The paper shows how important it is to design good, cheat-resistant graders for RL. This leads to more trustworthy models.
- Helpful for many users:
- Students: explaining diagrams, charts, and textbook pages.
- Professionals: reading long reports, extracting information from documents, analyzing visuals, or automating web tasks.
- Developers and researchers: the team open-sourced the 9B reasoning model and the base model, plus reward systems and code, so others can build on this work.
In short, GLM-4.1V-Thinking shows that with the right data, careful formats, smart sampling, and strong feedback, an open, mid-sized model can become a versatile “multimodal thinker” that handles complex, real-world problems across pictures, text, and video.
Collections
Sign up for free to add this paper to one or more collections.