- The paper introduces EcoVector and SCR to deliver fast, memory-efficient, and energy-saving on-device RAG for mobile devices.
- It employs a hybrid RAM-disk indexing and post-retrieval content reduction, achieving up to 42% token reduction without sacrificing accuracy.
- Empirical results demonstrate up to 8.89× lower latency and 24.4–40.2% power savings versus conventional server-based RAG methods.
MobileRAG: Architectures and Empirical Assessment for On-Device RAG
Introduction and Motivation
Retrieval-Augmented Generation (RAG) frameworks provide context-aware, semantic query handling by coupling similarity-based retrieval with LLM inference. While RAG's utility for ambiguous/natural-language queries is well established on server hardware, supporting such pipelines on mobile devices poses distinct technical constraints. Principally, mobile environments are limited by RAM (typically 4–12GB available), battery, and the need for minimal latency to sustain user experience and resource responsiveness. Existing RAG solutions predominantly assume server-scale computational and memory resources, rendering them impractical for device-centric scenarios, especially when private, user-specific data must remain on-device. MobileRAG addresses these limitations by integrating a novel EcoVector embedding index that supports dynamic, memory-efficient vector search with partial loading, alongside a Selective Content Reduction (SCR) method that minimizes sLM (Small LLM) inference workload.
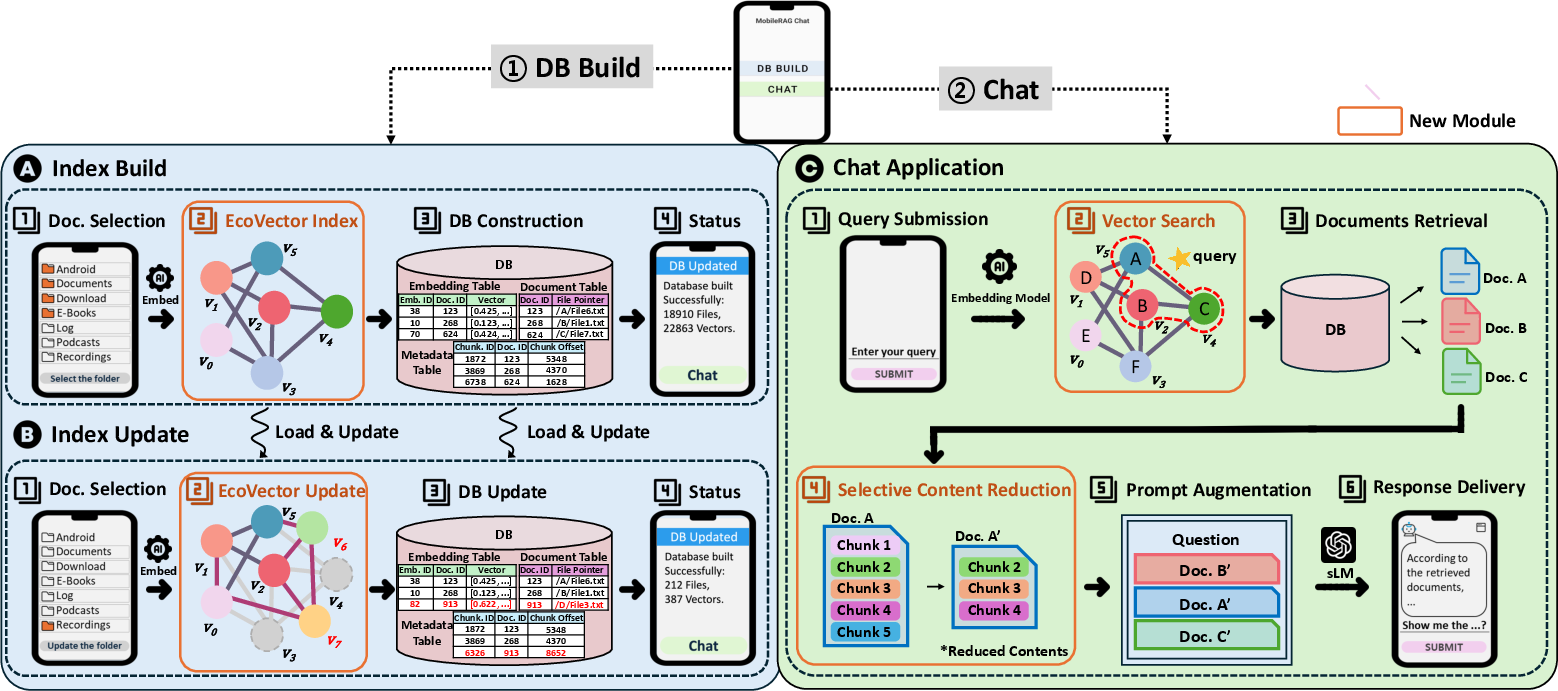
Figure 1: MobileRAG's on-device pipeline: Index Build, Index Update, and Chat Application operations are performed locally, ensuring privacy and resource efficiency.
EcoVector: Partitioned Graph Indexing for Efficient Vector Search
The EcoVector algorithm establishes a RAM-disk partitioned vector search architecture optimized for mobile constraints. Embeddings of document chunks are clustered (e.g., via k-means), yielding centroids that reside in RAM, while per-cluster HNSW-based inverted lists are stored on disk. Query-time search proceeds by traversing the RAM-resident centroids graph, then selectively loading only the most promising clusters’ graphs to minimize random-access disk I/O and RAM pressure. EcoVector supports asynchronous incremental updates, with efficient graph insertion and hierarchical neighbor maintenance via robust, bidirectional link management.
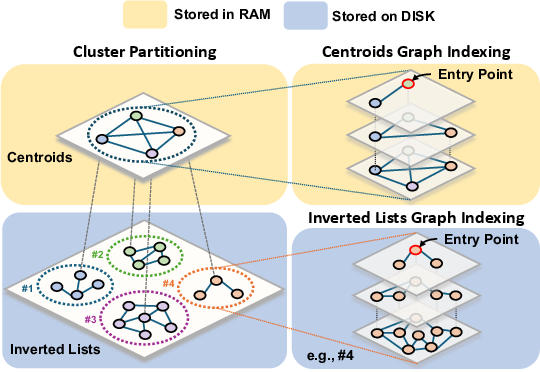
Figure 2: Schematic of EcoVector architecture: the centroids graph is kept in RAM, while clusters maintain disk-based HNSW graphs, supporting efficient query and update operations.
Empirical analysis shows that, compared to IVF, IVFPQ, HNSW, and their disk-based variants, EcoVector achieves a comparable memory footprint (see Figure 3) yet substantially reduces the number of high-dimensional distance computations required per query, offsetting the disk overhead through judicious cluster selection. EcoVector’s per-query search latency and energy consumption are both minimized, as shown via Recall vs QPS and power consumption metrics (Figure 4, Figure 5). This approach effectively decouples scalability from RAM limitations, permitting deployment on commodity mobile hardware.
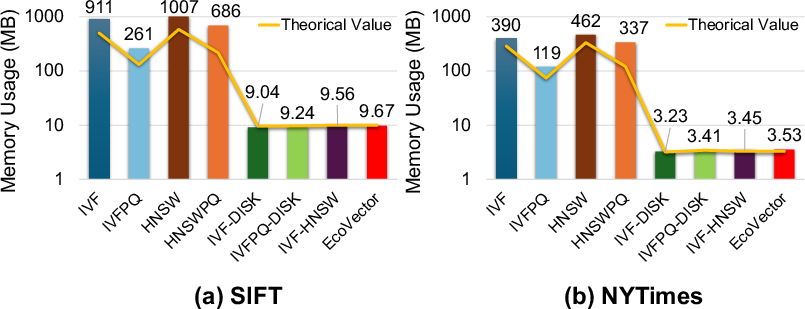
Figure 3: Memory usage profile across algorithms and datasets confirms EcoVector's optimal use of limited mobile RAM.
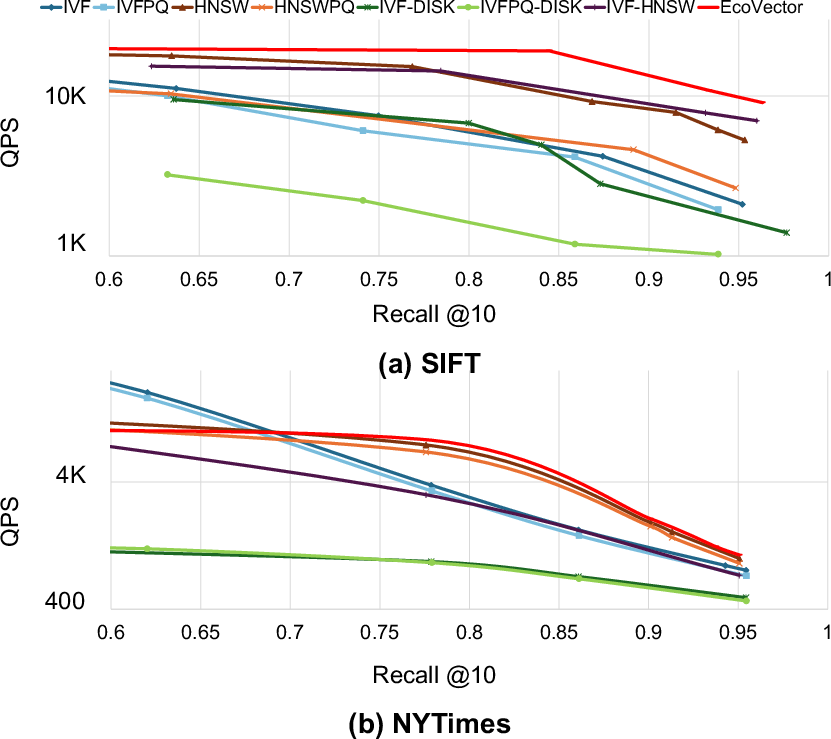
Figure 4: EcoVector achieves superior query speed at fixed recall, demonstrating efficient use of hybrid RAM-disk indexing.
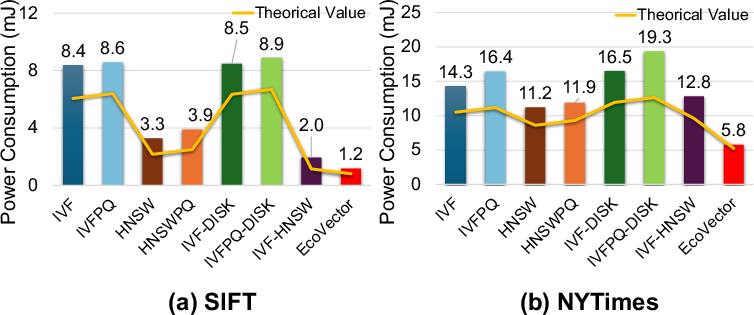
Figure 5: Power consumption per retrieval on mobile hardware; EcoVector markedly lowers energy usage versus baselines.
SCR: Post-Retrieval Selective Content Reduction for sLM Efficiency
The SCR procedure is invoked after document retrieval, prior to prompt construction for sLM inference. The method applies sentence-level chunking (sliding windows with overlap), recalculates embedding similarities to the query, and selects only the most relevant segments—optionally extending context by a fixed number of sentences before/after selection. Documents are re-ranked according to segment-level similarity, further refining prompt coherence and relevance. This post-retrieval reduction sharply curtails the effective context size fed to the sLM, leading to significant improvements in latency and lower energy draw with no detectable degradation in retrieval accuracy.
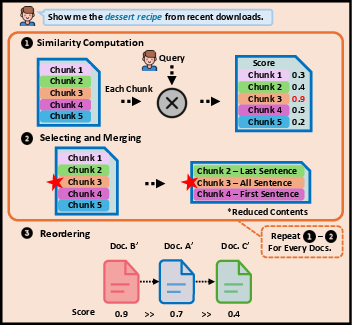
Figure 6: SCR architecture enables precise selection and contextual merging of relevant content for efficient prompt construction.
Quantitative analysis confirms up to 42% reduction in input token count for SQuAD, 31% for TriviaQA, and 7% for HotpotQA while maintaining original accuracy levels. The SCR approach outperforms both naive chunk-size reduction and general-purpose text compression, achieving better resource utilization (see Figure 7, Figure 8) and robust downstream accuracy.
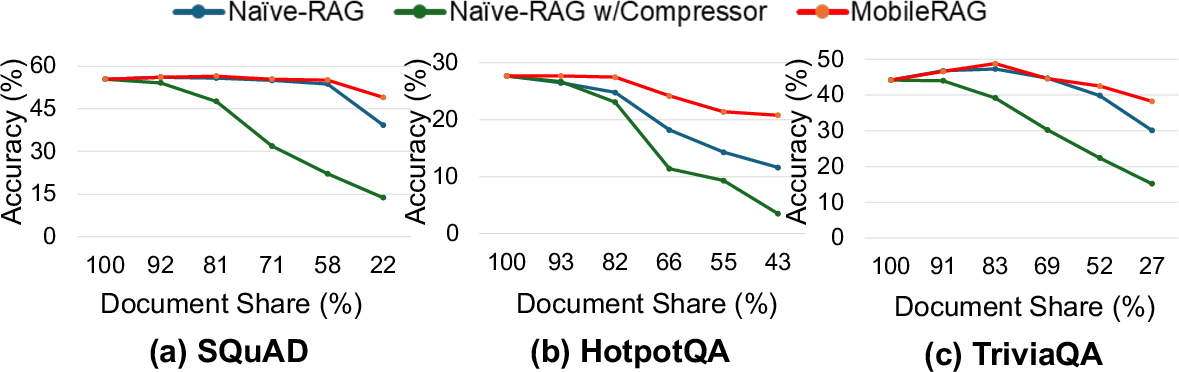
Figure 7: Comparative evaluation of SCR-based MobileRAG, Naive-RAG with small chunks, and compressor approaches: SCR balances context and efficiency without accuracy loss.
MobileRAG was benchmarked on a Galaxy S24 (8GB RAM, Exynos 2400, Android 14) using large-scale datasets for both ANNS (SIFT, NYTimes) and QA tasks (SQuAD, HotpotQA, TriviaQA). Key results include:
- Memory: EcoVector achieves memory efficiency similar to disk-centric baselines (IVF-DISK, IVF-HNSW), permitting index sizes far beyond RAM capacity.
- Search Latency: EcoVector yields up to 8.89× lower latency at comparable recall (SIFT @ 0.93 recall@10).
- TTFT: MobileRAG’s integrated SCR reduces TTFT by 1.18–1.41× across sLM backends.
- Power Consumption: EcoVector and SCR together yield overall pipeline power savings of 24.4–40.2% versus leading baselines.
- Update Latency: EcoVector’s partitioned graph structure enables scalable, balanced insert/delete operations.
- Accuracy: MobileRAG’s SCR approach matches or exceeds RAG variants employing explicit re-rankers, with advanced document reordering.
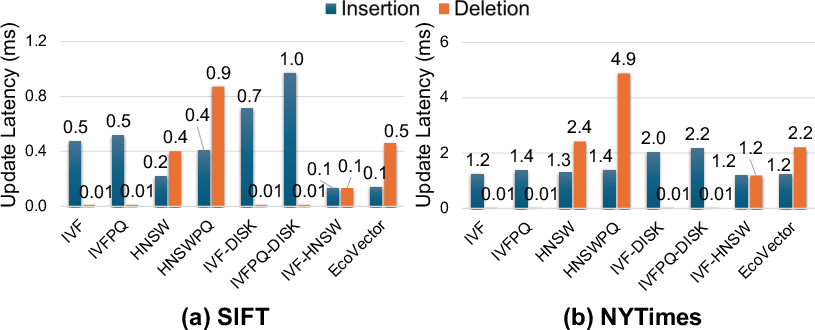
Figure 9: EcoVector sustains moderate insertion and deletion latency via cluster-local graph updates, balancing update throughput and efficiency.

Figure 10: Breakdown of TTFT on HotpotQA: SCR overhead is offset by substantial gains in sLM inference speed.
Practical and Theoretical Implications
MobileRAG’s hybrid index architecture and post-retrieval selective reduction represent critical advances for on-device deployment of RAG pipelines. The design ensures strict data privacy (offline operation), supports large-scale personal data collections, and enables real-time, contextualized query-response capabilities. The methodology is extensible to diverse sLM models, supporting progressive improvements in mobile-oriented inference by exploiting memory, energy, and context-control algorithms. The analytical models provided for memory, latency, and power constitute a rigorous framework for future mobile RAG optimization.
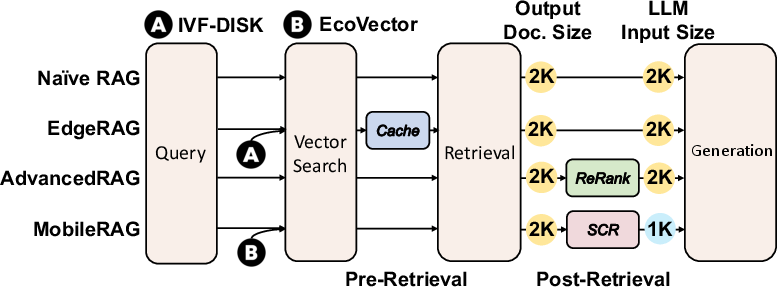
Figure 11: Comparative overview of RAG methods, with MobileRAG uniquely supporting fully on-device resource-constrained operation.
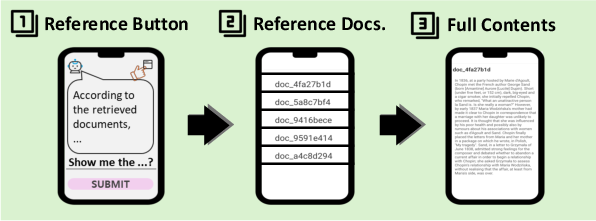
Figure 12: Document source reference tracking in the MobileRAG chat application supports transparent, context-rich responses.
Conclusion
MobileRAG introduces a comprehensive architecture for fast, memory- and energy-efficient RAG on mobile devices, integrating partitioned graph indexing with post-retrieval content refinement. Empirical evaluations demonstrate strong improvements in memory usage, search latency, TTFT, and power consumption, with competitive or superior QA accuracy versus established baselines. These results validate MobileRAG's viability for real-world on-device deployment and provide a foundation for future exploration of NPU/GPU co-processing and advanced embedding strategies for mobile-scale RAG.