- The paper introduces CARE-RAG, a novel framework that integrates parameter record comparison and retrieval result refinement to mitigate knowledge conflicts and reduce hallucinations.
- It employs conflict-driven summarization to reconcile internal and external evidence, leading to improved factual consistency and transparency in generated answers.
- Experimental results on multiple QA benchmarks show significant gains in EM and F1 scores, underlining the framework's robust performance and impact on trustworthy RAG systems.
CARE-RAG: Enhancing Trustworthy Retrieval-Augmented Generation
The paper "Rethinking All Evidence: Enhancing Trustworthy Retrieval-Augmented Generation via Conflict-Driven Summarization" (2507.01281) introduces CARE-RAG, a novel framework designed to improve the trustworthiness of RAG systems by explicitly addressing knowledge conflicts between internal knowledge and retrieved content. The approach involves conflict-driven summarization of all available evidence, including parameter-aware evidence derived from LLMs and context-aware evidence refined from retrieved documents. The framework aims to mitigate hallucinations and improve the reliability of RAG systems in knowledge-intensive tasks.
CARE-RAG Framework
CARE-RAG enhances RAG by clarifying the relationships between internal knowledge and retrieved content. The framework consists of four stages: (I) Parameter Record Comparison, (II) Retrieval Result Refinement, (III) Conflict-Driven Summarization, and (IV) CARE-RAG Generation. (Figure 1) illustrates the CARE-RAG framework.
Figure 1: An illustration of CARE-RAG rethinking all available evidence via conflict-driven summarization. The framework consists of four stages: (I) Comparison of parameter Records licits and aggregates the model’s internal diverse perspectives into parameter-aware evidence; (II) Refinement of Retrieved Evidence removes irrelevant noise from raw retrieved content to produce concise, context-aware evidence; (III) Conflict-Driven Summarization detects and analyzes conflicts between parameter-aware and context-aware evidence; (IV) CARE-RAG Generation synthesizes a final answer by reconciling conflicts and integrating all information.
The Parameter Record Comparison stage elicits the model's internal knowledge baseline before introducing external evidence. This stage involves iterative prompting to generate diverse internal perspectives, reducing internal hallucinations by capturing variability within its parameter knowledge. The Retrieval Result Refinement stage distills retrieved documents into concise, context-aware evidence by extracting salient information and eliminating irrelevant or redundant content. This refinement enhances the clarity and relevance of external evidence, facilitating subsequent conflict detection. The Conflict-Driven Summarization stage identifies discrepancies between parameter-aware evidence and refined context-aware evidence using a dedicated conflict detection module. This module assesses the conflict between two evidences and provides related reasoning, enabling the model to synthesize diverse knowledge perspectives. The CARE-RAG Generation stage synthesizes a final answer by reconciling conflicts and integrating all information. This enhances the transparency of parametric knowledge, factual accuracy, and robustness to conflicting or ambiguous evidence in the generated output.
Implementation Details
The implementation of CARE-RAG involves several key components. For the parameter Record Comparison stage, iterative prompting is used to generate multiple perspectives from the LLM. In the Retrieval Result Refinement stage, the LLM extracts critical factual claims and eliminates irrelevant content from the retrieved documents using instruction-based prompting. For Conflict-Driven Summarization, a distilled LLaMA-3.2B model, fine-tuned on DeepSeek annotations, is used to identify conflicts between parameter-aware and context-aware evidence. The final CARE-RAG Generation stage synthesizes the answer by integrating all available information, reconciling conflicts, and enhancing transparency and accuracy.
QA Repair for Valid Evaluation
The paper addresses the issue of outdated or mismatched ground truths in standard QA benchmarks by introducing a QA Repair pre-processing step. This step involves manually analyzing and correcting errors in the benchmark datasets to ensure fairer comparisons. A manual analysis of 1,000 randomly sampled instances from each dataset revealed significant annotation flaws, including outdated answers and semantic mismatches. The QA Repair process corrects these errors, leading to substantial gains in both EM and F1 scores across datasets. This pre-processing step ensures more accurate and reliable evaluation for the community.
Experimental Results
The experimental evaluation of CARE-RAG involves five QA benchmarks: Natural Questions (NQ), TriviaQA, HotpotQA, ASQA, and WikiQA. The results demonstrate that CARE-RAG consistently achieves the highest EM and F1 scores across all datasets and models, outperforming strong RAG baselines. Specifically, CARE-RAG improves EM scores by up to 23.6% compared to standard RAG and outperforms the strongest existing baseline by an average of 3.8% on EM.
Ablation Studies and Sensitivity Analysis
Ablation studies demonstrate the contribution of each component of CARE-RAG to its overall performance. Removing any of the three key stages—Parameter Record Comparison, Retrieval Result Refinement, or Conflict-Driven Summarization—results in a significant performance decrease. Sensitivity analysis reveals that CARE-RAG is robust to variations in the number of retrieved evidences. (Figure 2) illustrates the sensitivity to retrieval size. Performance peaks around K=15–20, beyond which it plateaus, showing stability even when lower-quality evidence is included.
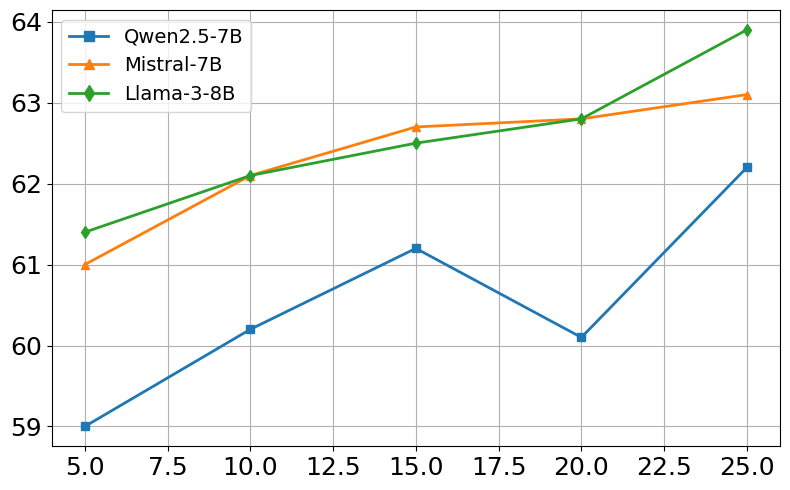
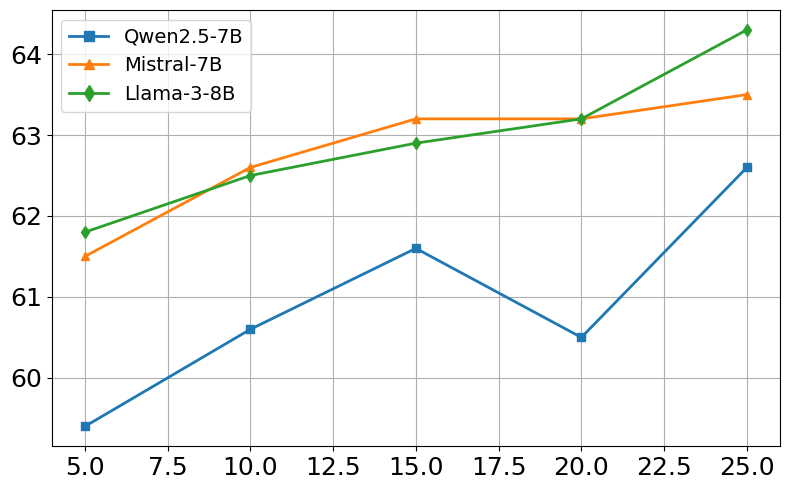
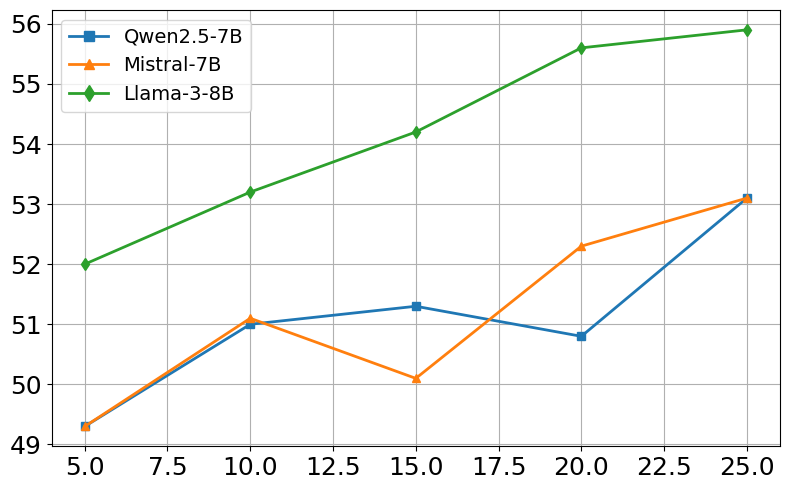
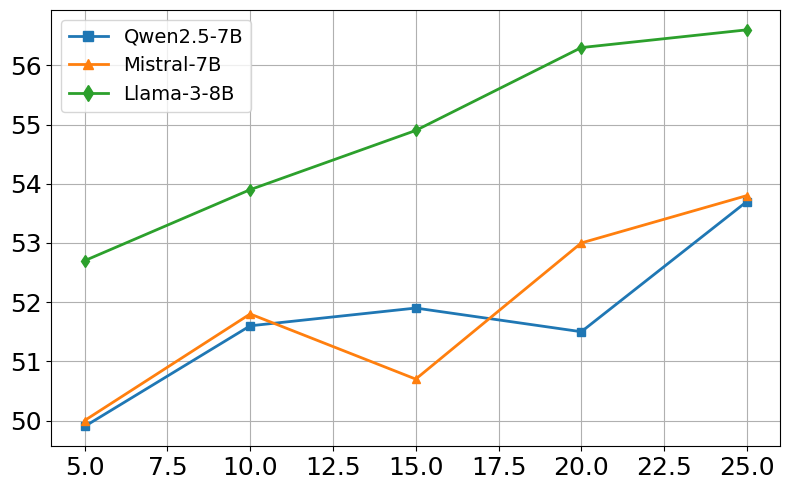
Figure 2: Sensitivity to retrieval size (K). EM/F1 scores for NQ and HotpotQA across three open-source models.
Robustness to Retrieval Variations
The paper evaluates the robustness of CARE-RAG to retrieval variations by comparing its performance under different evidence strategies. CARE-RAG consistently outperforms both contextual and parameter-only baselines, achieving gains of up to 0.239 EM. These results demonstrate CARE-RAG's superior robustness to variations in evidence quality and composition, particularly in scenarios with conflicting or incomplete information. (Figure 3) highlights the EM performance across different retrieval evidence sources.
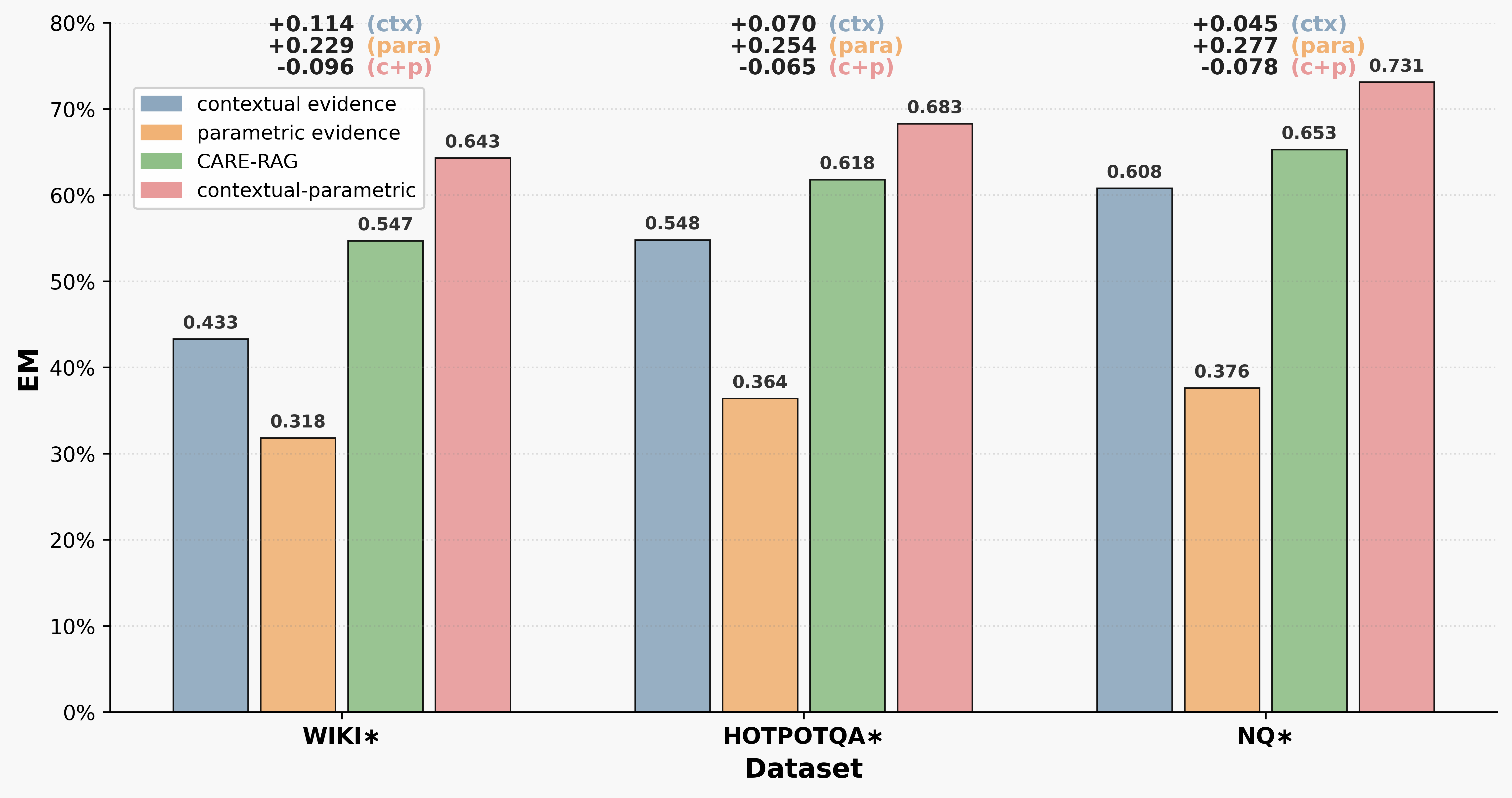
Figure 3: EM performance across three datasets using different retrieval evidence sources.
The paper discusses related work in the area of RAG, highlighting the challenges of improving retrieval integration and resolving knowledge conflicts. Existing methods, such as REPLUG [Shi2023] and RA-DIT [Lin2023], aim to improve RAG systems but may not fully address challenges from conflicting or low-quality retrievals. CARE-RAG explicitly targets post-retrieval synthesis to improve robustness under such scenarios. The paper also acknowledges the importance of knowledge editing in LLMs and the need for conflict resolution within RAG pipelines.
Conclusion
CARE-RAG is a framework for retrieval-augmented question answering that enhances factual consistency and robustness by integrating structured parameter introspection, fine-grained context refinement, and lightweight conflict detection. The experimental results demonstrate that CARE-RAG consistently outperforms strong baselines, highlighting the value of explicitly modeling knowledge conflicts for trustworthy and generalizable retrieval-augmented generation. The limitations section notes that CARE-RAG incurs greater computational overhead and is tied to the quality of the underlying LLMs. Ethical considerations include the need for transparent management of subjective judgments in the QA Repair process and the risk of generating convincing yet inaccurate information if misused.