- The paper introduces a dynamic KDE algorithm that maintains (1±ε)-approximate estimates during continuous data insertions.
- It presents a novel sparse similarity graph construction method that supports fast dynamic spectral clustering with sub-linear update times.
- Experimental results indicate that the proposed algorithms outperform traditional static methods on large datasets.
Dynamic Similarity Graph Construction with Kernel Density Estimation
Introduction
The paper "Dynamic Similarity Graph Construction with Kernel Density Estimation" explores the kernel density estimation (KDE) problem within dynamic settings. The research introduces a data structure that efficiently maintains KDE estimates as data points are added over time and develops algorithms for constructing sparse similarity graphs and fast dynamic spectral clustering.
Kernel density estimation is critical for approximating the sum of kernel function values over data points. The challenge compounded in dynamic environments—where both data and query sets change—necessitates efficient updating mechanisms to maintain accurate estimates. The methodologies in this paper aim to offer solutions by ameliorating update times in dynamic scenarios.
Dynamic Kernel Density Estimation
The authors propose an algorithm tailored for dynamic settings that optimally adjusts as data points are iteratively introduced. Designed to handle insertions and deletions within query points, the data structure maintains estimates with sub-linear time complexity for Gaussian kernels, extending its utility across arbitrary kernel functions.
A notable finding is the capacity to maintain (1±ε)-approximate estimates throughout the sequence of data point insertions. This is particularly significant as it represents the first instance of a dynamic KDE solution capable of sustaining query estimates efficiently under continuous data point additions.
Approximate Similarity Graphs
Similarity graphs, vital for clustering algorithms, are traditionally fully connected with Θ(n2) edges, focusing on kernel similarities among data points. This paper introduces a dynamic approach, yielding approximate graphs that retain the inherent cluster qualities of the fully connected version with substantially fewer edges.
The dynamic graph algorithm presented builds upon KDE principles, ensuring each graph update reflects the current data structure’s cluster properties. By leveraging spectral clustering, the algorithm guarantees comparable performance metrics to static graph models but with an enhanced efficiency in maintaining sub-linear update durations.
Experimental Evaluation
The research substantiates its claims through experimental analysis on varied datasets. The dynamic KDE algorithm scales efficiently, demonstrating superior performance over baseline methods like static KDE estimators in large dataset environments. Similarly, the dynamic graph construction algorithm outperforms traditional nearest neighbor approaches in speed while preserving clustering quality.
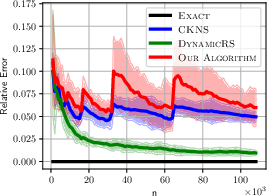
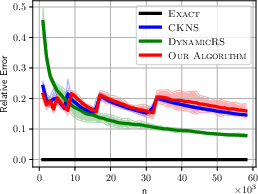
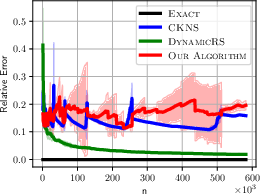
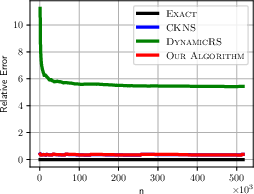
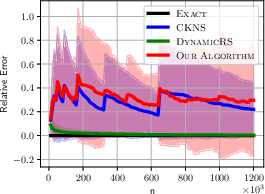
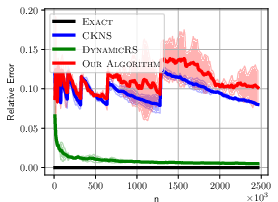
Figure 1: ALOI Relative Error for different algorithms showcasing the reliability and efficiency of the dynamic KDE method.
Implications and Future Directions
Practically, implementing these dynamic methodologies can revolutionize industries reliant on real-time spatial data analysis and clustering. These include fields as varied as market basket analysis, geographical tracking, and network security, offering robust alternatives to existing static approaches.
Theoretically, this research paves pathways for future exploration into dynamic data structure optimization and efficiency, particularly in the realms of high-dimensional data analysis and large-scale network simulations.
Conclusion
The paper embodies significant advancements in dynamic similarity graph construction. With rigorous optimization strategies and proven lower time complexities in dynamic settings, the methodologies developed hold potential to transform both academic exploration and practical applications, expanding dynamic capabilities within KDE and clustering frameworks.