- The paper presents a novel multipole attention model (MANO) that achieves linear complexity using a multiscale hierarchical framework.
- MANO employs dynamic downsampling and upsampling techniques across spatial scales to effectively capture both global and local contexts.
- Empirical results show that MANO outperforms state-of-the-art models in image classification and physics simulations with reduced runtime and memory usage.
Linear Attention with Global Context: A Multipole Attention Mechanism for Vision and Physics
Introduction
The paper "Linear Attention with Global Context: A Multipole Attention Mechanism for Vision and Physics" (2507.02748) addresses the computational inefficiencies inherent in traditional Transformers due to their quadratic complexity in handling high-resolution inputs. By conceptualizing attention as an interaction problem akin to n-body simulations, the authors propose a novel Multipole Attention Neural Operator (MANO). MANO utilizes a distance-based multiscale attention mechanism, inspired by the Fast Multipole Method (FMM), to improve upon the existing Transformer models both in computational efficiency and performance. This methodology is empirically validated on image classification tasks and physics simulations such as Darcy flows.
Methodology
MANO introduces a hierarchical, multiscale attention framework. The essential innovation of MANO lies in its ability to compute attention with linear complexity by leveraging a structured hierarchy that captures interactions at multiple spatial scales. This method involves dynamic downsampling of input features and upsampling through convolutional techniques shared across multiple scales (Figure 1).
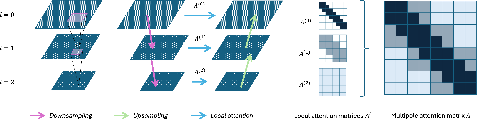
Figure 1: A depiction of the multi-scale grid structure, the V-cycle structure for computing multipole attention, and attention matrices across three levels.
This multiscale approach ensures that the model retains a global receptive field in each attention head, compared to conventional Transformers where attention is computed over the entire sequence with quadratic complexity. The attention matrix is formed in a multiscale manner, allowing MANO to significantly reduce memory and runtime while preserving the ability to capture long-range dependencies critical for both vision tasks and scientific simulations.
Empirical Results
The effectiveness of MANO is evaluated against state-of-the-art models, including Vision Transformers (ViT) and Swin Transformers. In image classification tasks, MANO demonstrates superior performance with reduced runtime and memory footprint. It achieves significantly higher accuracy across several datasets, including Tiny-ImageNet and CIFAR-100, with visible improvements in tasks requiring fine-grained classification such as Stanford Cars and Oxford Flowers (Table 1).

Figure 2: Darcy flow reconstruction showcasing MANO prediction alongside ViT predictions with varying patch sizes.
In physics simulations, MANO is tested on the Darcy flow PDE benchmark. It exhibits outstanding performance, achieving lower mean squared errors than both Fourier Neural Operators and traditional ViTs with various patch sizes. The visual quality of Darcy flow reconstructions shows that MANO's predictions are closer to the ground truth compared to other models, effectively demonstrating its capability to handle both global and local information (Figure 2).
Discussion and Implications
The proposed MANO model not only advances the efficiency of handling high-resolution data but also enhances the generality and scalability of neural operators for scientific modeling tasks. Its linear complexity in attention computation opens avenues for deploying Transformers in real-time and resource-constrained environments. By seamlessly integrating into Transformer backbones like SwinV2, MANO enables transfer learning across different tasks with minimal overhead.
Future research directions could explore extensions of MANO to other domains requiring dense prediction, such as medical image analysis or complex fluid dynamics, where retaining global context is crucial. Additionally, dynamic or learnable scale selection in MANO could further enhance its adaptability to various datasets and applications.
Conclusion
MANO represents a significant step forward in the development of efficient Transformer architectures. By bridging concepts from computational physics and machine learning, it provides a robust framework for both vision and physics tasks. The release of open-source code ensures reproducibility and encourages further innovation based on this model, setting the stage for new applications within AI and beyond.