- The paper introduces EasyCache, a runtime-adaptive caching framework that reuses transformation vectors during video diffusion inference to reduce computation without retraining.
- The method employs a runtime-adaptive threshold to reuse cached transformation vectors, achieving up to 3.3× speedup and a 36% PSNR improvement over prior caching techniques.
- The approach democratizes video synthesis by reducing computational costs, facilitating real-time applications while maintaining high visual fidelity.
Video Diffusion Acceleration via Runtime-Adaptive Caching
Introduction
Video generation models, particularly those leveraging Diffusion Transformers (DiTs), have gained prominence in generative modeling due to their ability to craft high-fidelity dynamic content. While the performance of these models in producing complex spatiotemporal dynamics is notable, their real-world applicability is hindered by high computational costs and slow inference speeds. This bottleneck arises from the iterative nature of the denoising process, which demands substantial computational resources, making it challenging to democratize video synthesis technologies. The paper "Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching" (2507.02860) addresses these challenges through the introduction of the EasyCache framework. EasyCache presents a training-free approach to accelerate video diffusion models by dynamically reusing previously computed transformation vectors during inference, thereby avoiding redundant computations.
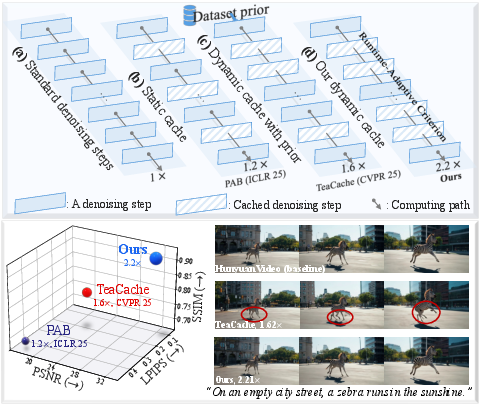
Figure 1: The comparison between (a) the default iterative denoising, (b) static caching with fixed intervals, (c) dynamic cache with external ``Dataset prior", and (d) our dynamic cache reuses computation by a runtime-adaptive criterion.
Methodology
EasyCache is built on the premise that the transformation vectors, indicating changes in predicted noise and latent input, exhibit relative stability over certain phases of the denoising process. This leads to the hypothesis that these vectors can be reused without compromising the generative fidelity of the models. Unlike previous caching methods that employ static intervals or rely on dataset-specific priors for dynamic caching, EasyCache uses a runtime-adaptive criterion that evaluates changes in transformation rates during inference. Specifically, EasyCache monitors the relative transformation rate stability, defined as the ratio of output changes to input changes between consecutive steps, and employs this as a basis for caching decisions.
A runtime-adaptive threshold mechanism governs the reuse of transformation vectors. During inference, if this threshold suggests local stability, previously computed transformations are reused, approximating future outputs and thus circumventing full computations. This decision process is fully autonomous of external profiling or explicit training requirements, marking a divergence from existing acceleration strategies that necessitate extensive pre-computation or parameter tuning.
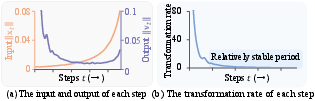
Figure 2: Analysis of feature dynamics. (a) The L1 norm of the input and output of each step. (b) The changes in the relative transformation rate between consecutive steps.
Experimental Evaluation
The effectiveness of EasyCache was demonstrated through extensive experiments across various state-of-the-art video generation models, including OpenSora, Wan2.1, and HunyuanVideo. The results indicate a substantial reduction in inference time, achieving speedups of up to 3.3× compared to the baseline models, while maintaining high visual fidelity. For instance, EasyCache showed a 36% PSNR improvement over previous state-of-the-art caching methods, making it an efficient solution for high-quality video generation in both research and practical applications. Additionally, EasyCache proved its utility by enhancing computational efficiency alongside other acceleration methods like efficient attention mechanisms, indicating its compatibility and potential for integration into existing workflows.
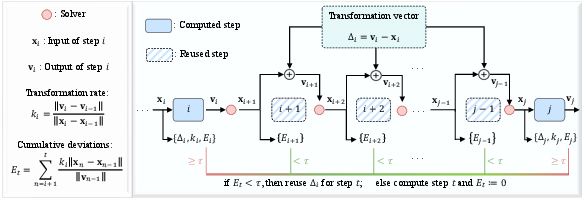
Figure 3: The overall of our method. For simplicity, we start from a computed step i. A runtime-adaptive criterion evaluates each subsequent step, reusing the cached transformation vector Delta_i while the accumulated deviation E_t remains below a threshold tau. A full computation is performed when the threshold is exceeded, as exemplified in step j.
Implications and Future Work
EasyCache not only advances the efficiency of video generation models but also holds implications for the broader adoption of generative technologies in real-time applications and computationally constrained environments. By eliminating the dependency on offline profiling, EasyCache democratizes access to sophisticated video synthesis processes, paving the way for more prolific use cases across creative industries and interactive applications.
Theoretically, the work suggests avenues for further exploration into the inherent dynamics of diffusion processes and their stability. Future research could extend runtime-adaptive caching strategies to other domains such as text-to-image synthesis or 3D content generation, leveraging the principles outlined in this study to enhance generative model efficiency across modalities.

Figure 4: Qualitative comparison of EasyCache with baseline and prior acceleration methods~\cite{zhao2024real,liu2025timestep.
Conclusion
The EasyCache framework exemplifies a significant advancement in the acceleration of video diffusion models by introducing a runtime-adaptive caching mechanism that enables substantial computation reuse. It effectively reduces inference time without compromising visual fidelity, making it an accessible and efficient solution for integrating high-quality video generation into practical applications. Through its innovative approach that sidesteps the need for retraining and offline profiling, EasyCache sets a new standard for training-free inference acceleration in generative modeling, offering promising directions for future research and development in AI-driven content creation technologies.