- The paper presents the EST, a hybrid model that fuses Transformer attention with fixed-size reservoir computing to overcome quadratic complexity.
- It introduces a working memory block with adaptive leak rates and previous state attention to effectively capture temporal dependencies.
- Evaluations on the STREAM benchmark show EST outperforming GRUs, LSTMs, and standard Transformers in resource-constrained and low-data scenarios.
Hybrid Architecture for Sequence Processing
The paper "Echo State Transformer: When chaos brings memory" (2507.02917) introduces the Echo State Transformer (EST), a novel hybrid architecture designed to address the quadratic complexity challenge of traditional Transformers when processing sequential data. The EST combines the attention mechanisms of Transformers with the principles of Reservoir Computing, specifically Echo State Networks (ESNs), to create a fixed-size working memory system. Evaluations on the STREAM benchmark demonstrate that ESTs can outperform GRUs, LSTMs, and even Transformers in resource-constrained environments and low-data scenarios across various sequential processing tasks.
Background and Motivation
Transformers have revolutionized NLP, but their computational complexity grows quadratically with sequence length due to the self-attention mechanism. This limitation hinders their applicability in scenarios requiring long-term memory and efficient processing. The paper posits that the brain processes and learns cognitive tasks like language and working memory differently, suggesting potential benefits from exploring biologically inspired memory mechanisms. The EST aims to create a more efficient model less reliant on intensive computations and massive datasets by integrating a working memory block into the standard Transformer architecture (Figure 1).
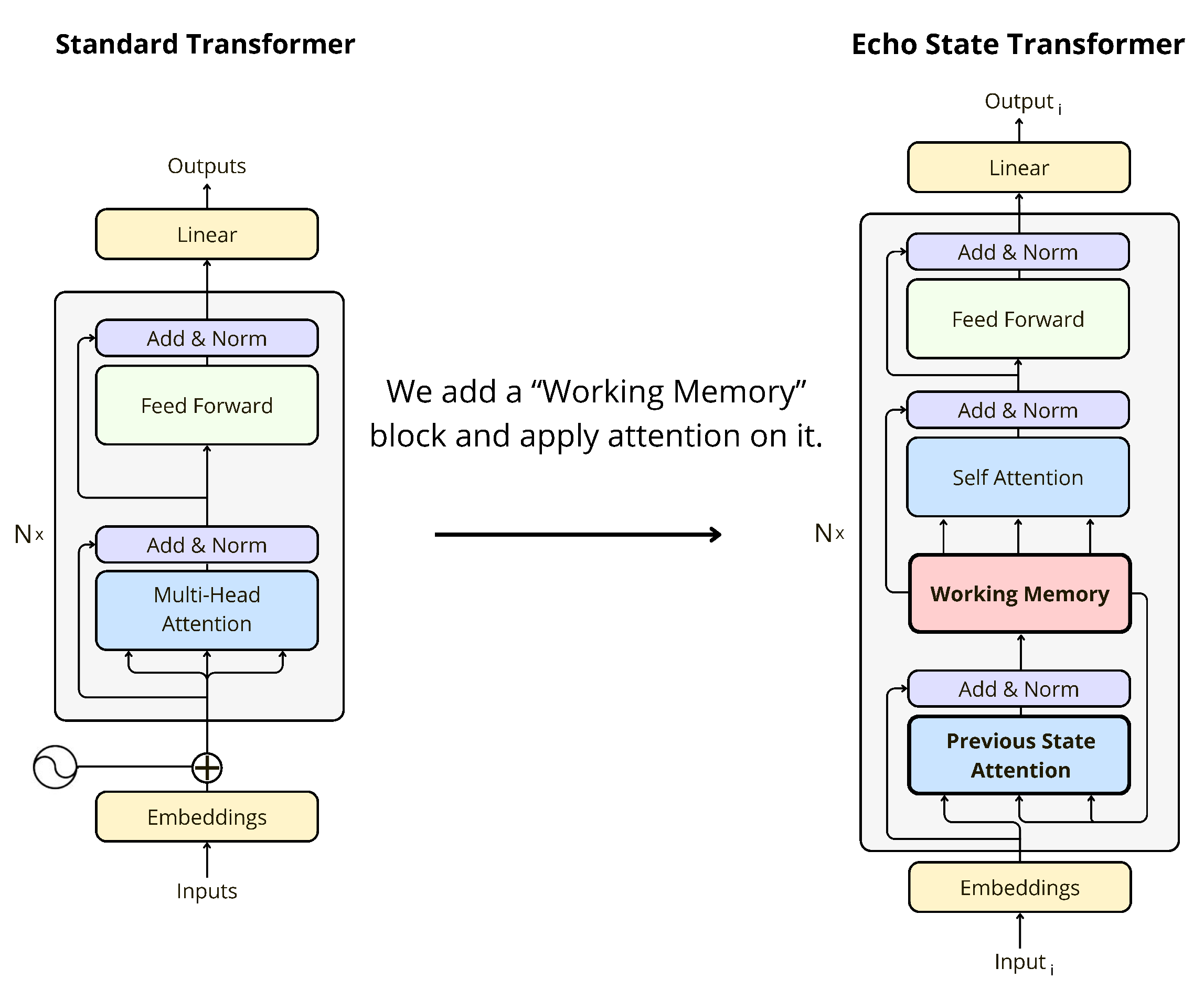
Figure 1: Comparison of standard Transformer and Echo State Transformer architecture.
Architectural Details
The EST architecture consists of six distinct blocks: input, previous state attention, working memory, self-attention, feed-forward, and output.
Working Memory
The core innovation lies in the working memory block, which comprises multiple parallel reservoir units derived from Reservoir Computing principles. Each reservoir, a recurrent network with fixed random weights, functions as a dynamic system retaining temporal information. The dynamics of each reservoir are governed by:
st=(1−α).st−1+α.f(Win.ut+W.st−1)
where st is the reservoir state, ut is the input, Win and W are fixed random matrices, f is a non-linear activation (typically tanh), and α is the leak rate. Uniquely, each unit learns its own dynamics parameters, including its spectral radius, through backpropagation. An adaptive leak rate mechanism, using a softmax function, determines how much information persists between time steps, allowing certain units to maintain fixed information over time (Figure 2).
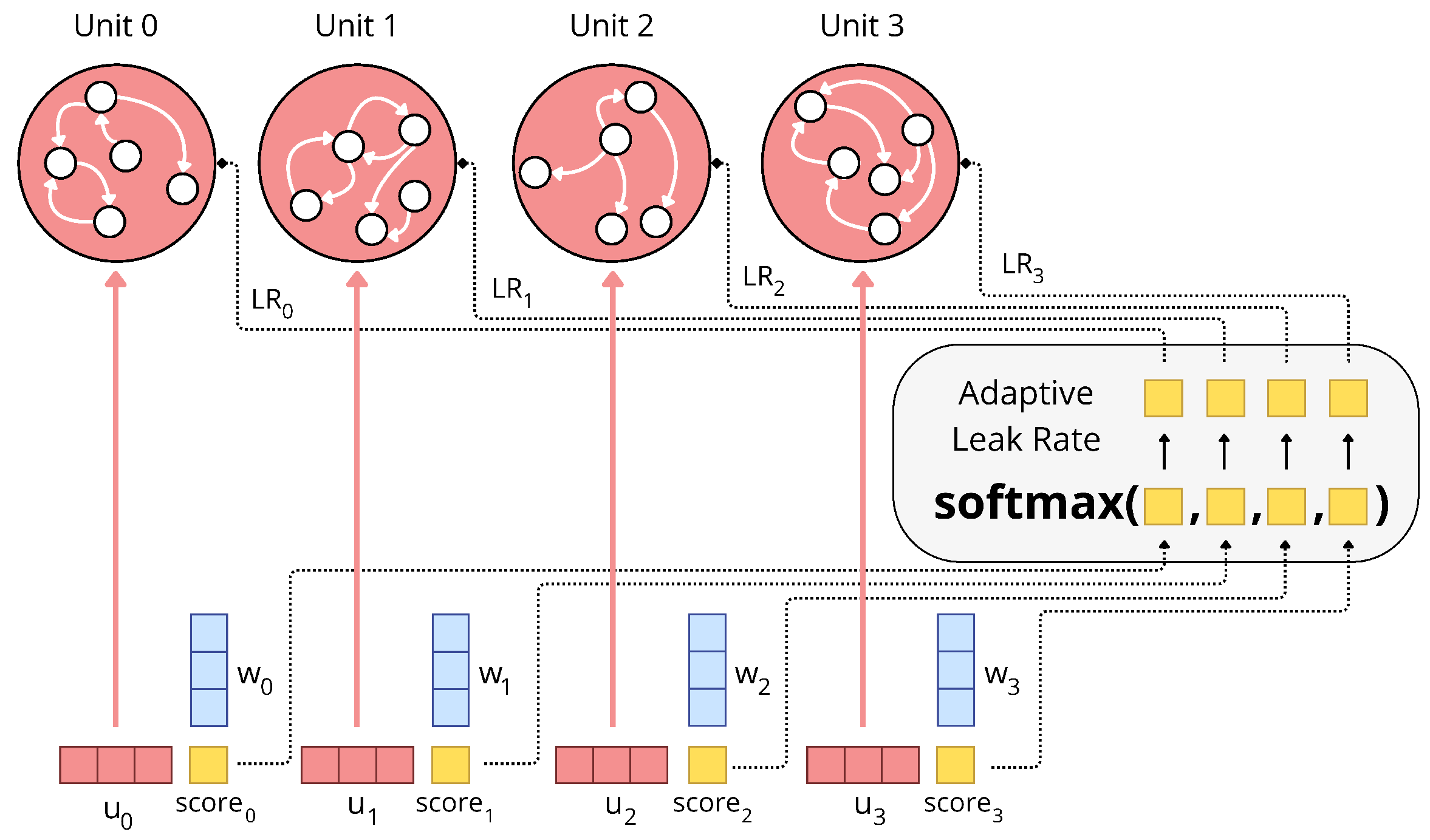
Figure 2: This figure displays the mechanism behind the Working Memory block and more particularly the adaptive leak rate. Each memory unit compute a score from its input vector. Then a softmax is applied on all of this score to compute the leak rate for each unit.
Attention Mechanisms
The EST employs two attention mechanisms. The first, previous state attention, allows each memory unit to create a unique information vector by attending to the states of all other memory units (Figure 3). This mechanism enables each unit to extract relevant information from the collective memory and compare it to the input. The second attention mechanism, self-attention, is applied to all units of the working memory to exploit their content for output prediction.
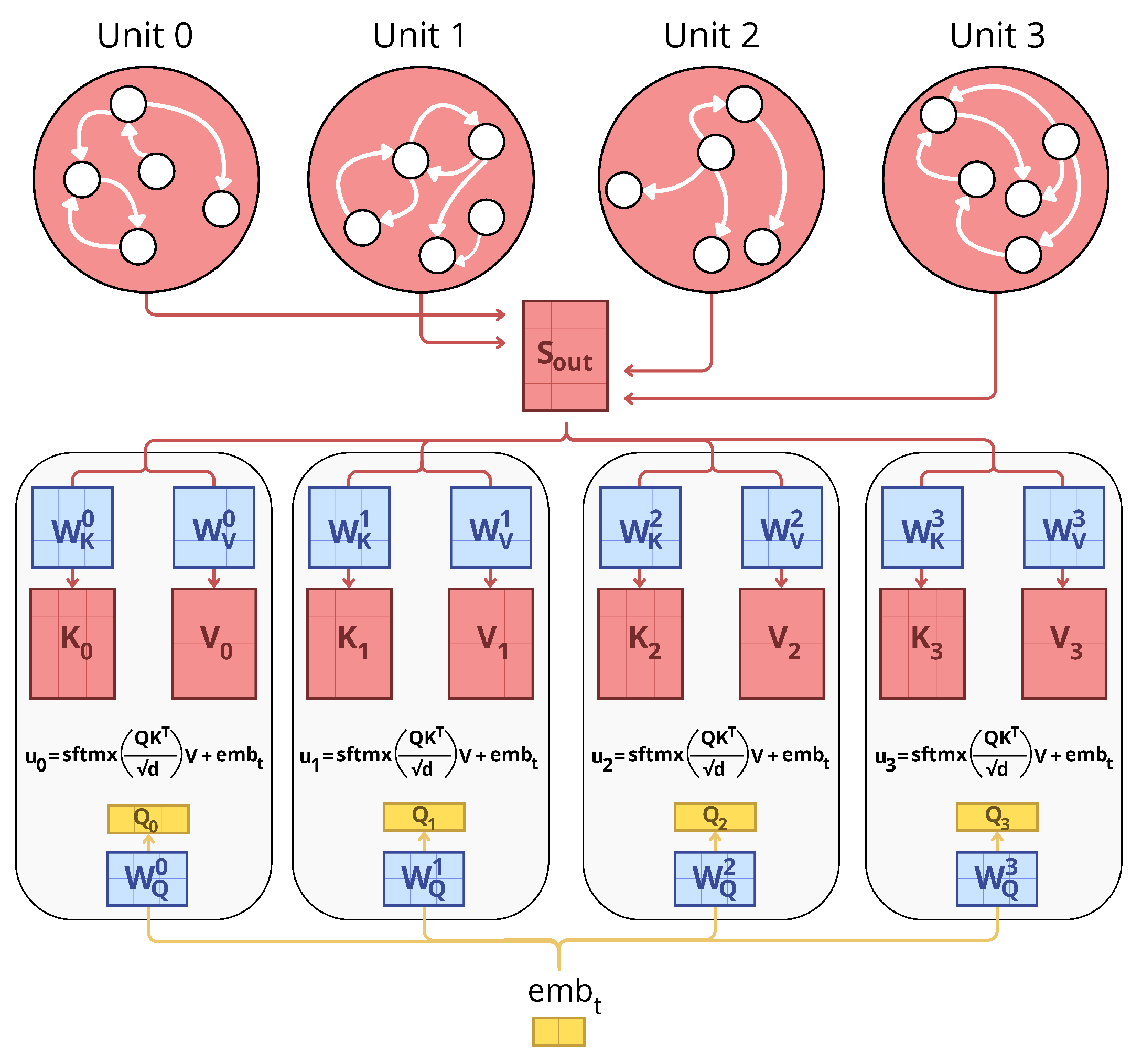
Figure 3: This figure display the mecanism of the Previous State Attention block. It produces Keys and Values from all memory units (Sout) and Queries from the embedding at time t (embt). Similarly to Transformer and its Multi-Head Attention block, we compute several distinct products of attention -- one per memory unit -- that allows each unit to compute its own input vector.
Complexity
Unlike Transformers, which allow complete parallelization of the entire sequence, ESTs require sequential training like GRUs and LSTMs, and thus, backpropagation through time. However, by maintaining a fixed number of memory units, the EST achieves constant computational complexity at each processing step, effectively breaking the quadratic scaling problem of standard Transformers.
Experimental Results
The authors evaluated the EST on the STREAM benchmark, a diverse set of 12 sequential tasks designed to assess working memory and non-linear computation. The EST was compared against GRUs, LSTMs, and standard Transformers. The results, measured using Best When Averaged (BWA) and Best Over All (BOA) metrics, demonstrate that ESTs outperform all competitors on 8 out of 12 tasks, especially for models with 1k and 10k parameters (Table 1). Transformers performed best on 4 tasks, while GRUs excelled on 1 task. The authors observed that larger EST models (100k or 1M parameters) did not outperform their smaller counterparts, suggesting potential optimization challenges when scaling up EST models.
Discussion
The EST demonstrates the potential of combining Transformer attention mechanisms with Reservoir Computing principles for efficient sequence processing. The model's ability to learn dynamics parameters and adapt leak rates allows for fine-grained control of information retention. The EST exhibits a remarkable capacity to handle a wide range of sequential tasks, frequently outperforming traditional architectures on the STREAM benchmark. However, the degradation in performance with larger EST models suggests that further research into appropriate regularization techniques or architectural modifications may be necessary to fully unlock their potential at larger scales.
Conclusion and Future Directions
The Echo State Transformer presents a promising hybrid architecture for overcoming the quadratic complexity of traditional Transformers. By introducing a fixed-size working memory inspired by Reservoir Computing, the EST achieves constant complexity in time and space for inference. The experimental results demonstrate the effectiveness of the EST in various sequential processing tasks, particularly in resource-constrained environments.
Future work could explore methods to eliminate the non-linearity in the reservoirs' dynamics to enable parallel training over all time steps, similar to Transformers. This could significantly improve training efficiency and unlock the full potential of ESTs for larger tasks.