- The paper introduces a training-free approach for compressing chain-of-thought reasoning by injecting a steering vector into the model's activations.
- The method achieves a 67.43% reduction in CoT length and a 2.73× speedup in inference while maintaining model accuracy.
- The approach generalizes across tasks and complements existing techniques, offering practical benefits for latency-sensitive applications.
Activation Steering for Chain-of-Thought Compression
The paper "Activation Steering for Chain-of-Thought Compression" (2507.04742) proposes a method for reducing the verbosity of Chain-of-Thought (CoT) reasoning in LLMs by manipulating the hidden representations at inference time. This technique aims to compress CoTs without retraining, thus optimizing reasoning pathways for efficiency while maintaining accuracy.
Introduction to Activation-Steered Compression (ASC)
Chain-of-thought prompting in LLMs facilitates improved multistep reasoning, but often leads to verbose output, increasing computational costs and latency. The ASC method addresses this by analyzing the internal activation space of LLMs, separating verbose, English-heavy CoTs from concise, math-centric ones. ASC achieves compression by injecting a steering vector into the model’s residual-stream activations to transition between verbose and concise reasoning modes.
Methodology
ASC bypasses retraining by modifying the model's hidden representations through inference-time intervention. The process involves:
- Sampling Paired CoTs: From the MATH500 and GSM8K datasets, verbose CoTs are generated using standard prompts, while concise CoTs are produced by instructing GPT-4o to minimize verbosity.
- Extracting Steering Vectors: The model's residual-stream activations are extracted for both verbose and concise CoTs at a selected layer, using t-SNE visualizations to identify distinct activation regions (Figure 1).
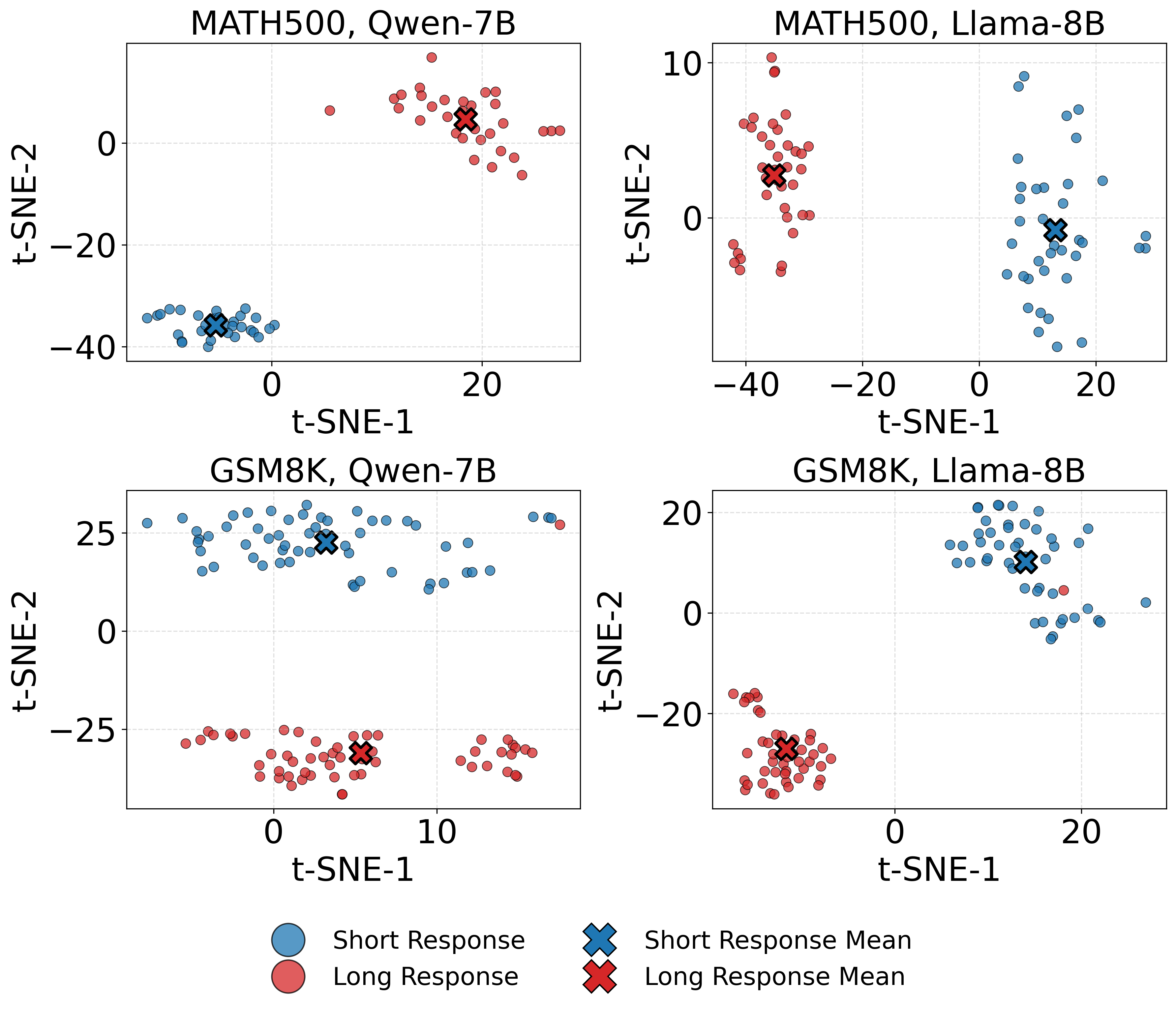
Figure 1: t-SNE visualization of residual stream representations for long (verbose) and short (concise) CoT responses across two datasets and two models.
- Injection of Steering Vectors: The average activation difference forms the steering vector. At runtime, the model’s residual stream is adjusted by this vector, guiding the model toward concise reasoning (Figure 2).
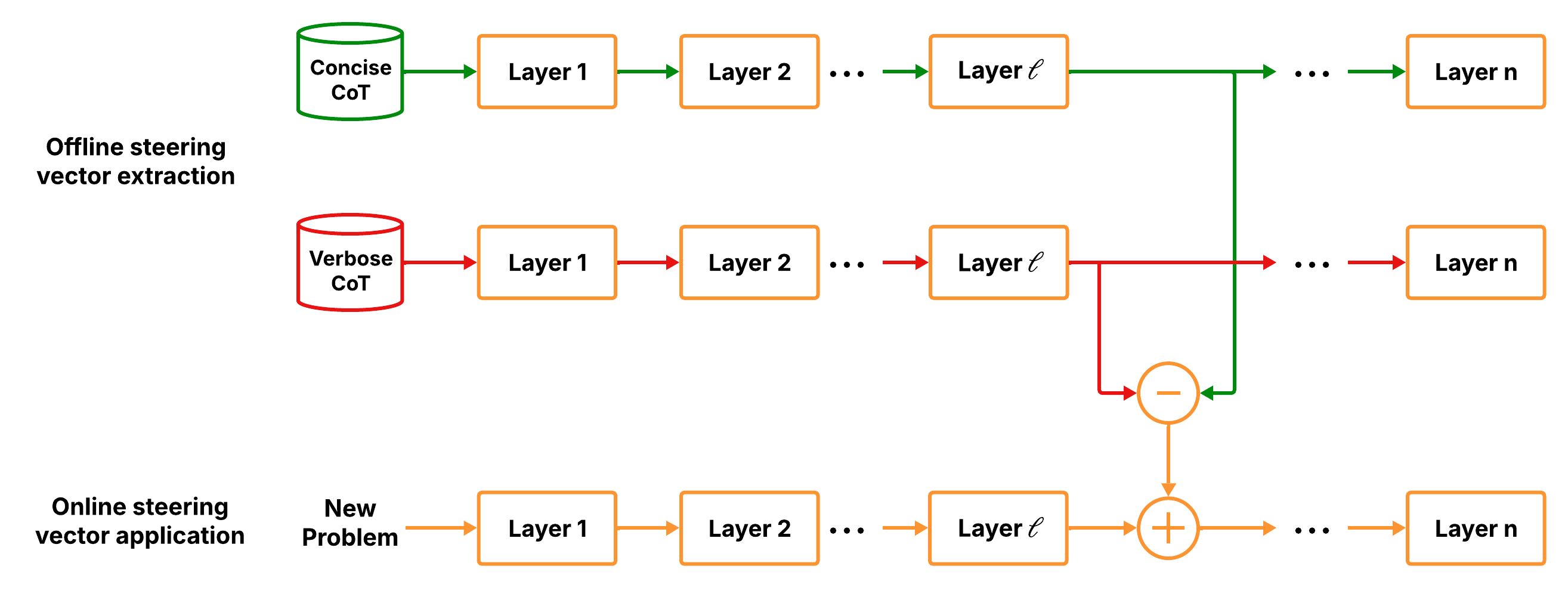
Figure 2: Steering vector extraction and application using pairs of concise and verbose CoTs.
Theoretical Analysis of Steering Strength
A critical aspect of ASC is the choice of steering strength, γ, which impacts the balance between compression efficacy and accuracy retention. The paper introduces a closed-form scaling rule that bounds the KL divergence between the original and modified output distributions, ensuring controlled distribution shifts while effectively compressing CoTs.
Experimental Results
ASC demonstrates substantial CoT length reductions across various models and datasets. For instance, on the MATH500 dataset, ASC achieves a 67.43% decrease in CoT length with up to a 2.73× speedup in inference time on an 8B model. This reduction is attained with negligible loss in accuracy, outperforming other prompt-based and heuristic exit compression strategies.
Moreover, ASC is shown to be orthogonal to existing compression methods, allowing composition for enhanced efficiency, providing models with a practical solution in latency-sensitive applications.
Discussion on Cross-Task Generalization
ASC's ability to generalize across tasks suggests that verbosity in CoT resides along a shared latent dimension in LLMs. Cross-task experiments indicate high alignment between steering vectors derived from different datasets, supporting the hypothesis that such verbosity can be steered uniformly.
Conclusion
Activation-Steered Compression provides a novel, training-free approach to optimize reasoning in LLMs, reducing verbosity by manipulating representation-level controls. By reframing rationale compression as an activation-level problem rather than output-level post-processing, ASC offers a robust, efficient methodology for deploying LLMs in environments where computational constraints are critical. This paper underscores the potential for leveraging internal model architectures for real-time compression, suggesting new avenues for enhancing LLM efficiency without compromising performance.
Overall, ASC represents a significant step forward in the pursuit of efficient AI systems, paving the way for future developments that exploit the geometry of activation spaces for diverse applications in AI.
