- The paper reveals significant discrepancies between traditional objective metrics and human perception in evaluating music source separation.
- It employs a large-scale listener study on the MUSDB18 dataset to compare legacy and deep-learning models using metrics like SI-SAR and FAD.
- Results indicate that state-of-the-art systems consistently outperform older methods, highlighting the need for perception-informed evaluation.
Musical Source Separation Bake-Off: Comparative Analysis of Objective Metrics and Human Perception
Introduction
The paper "Musical Source Separation Bake-Off: Comparing Objective Metrics with Human Perception" (2507.06917) explores the field of music source separation, where the task is to isolate individual sound sources, or stems (e.g., vocals, drums, guitar), from a mixed audio recording. This process has far-reaching implications for applications like karaoke and various music information retrieval tasks. Traditionally, evaluation of the separation process relies heavily on objective energy-ratio metrics like the Source-to-Distortion Ratio (SDR), Source-to-Artifacts Ratio (SAR), and Source-to-Interference Ratio (SIR). However, these metrics frequently misalign with subjective human perception, necessitating the exploration of alternative, perception-oriented metrics.
Methodology
The study conducted a large-scale listener evaluation utilizing the MUSDB18 test set, involving approximately 30 ratings per track, aggregated across seven separate listener groups with at least two years of musical experience. The listeners assessed outputs from a variety of separation systems, including both legacy methods and modern deep-learning models. State-of-the-art systems like HTDemucs-ft and SCNet-large were scrutinized against the oracle method IRM1 and legacy systems like Open-Unmix and REP1, with evaluations conducted online through the webMUSHRA platform.
Comparison of Objective Metrics
The work compared several objective metrics, both traditional energy-ratio and more recent embedding-based metrics. For the latter, innovative measures such as Fréchet Audio Distance (FAD) with different embeddings (e.g., CLAP-LAION-music, EnCodec, VGGish, Wave2Vec2, HuBERT) were evaluated. Results highlighted the superiority of the traditional SDR metric for vocal estimates, whereas the Scale-Invariant Signal-to-Artifacts Ratio (SI-SAR) was more predictive for drums and bass.
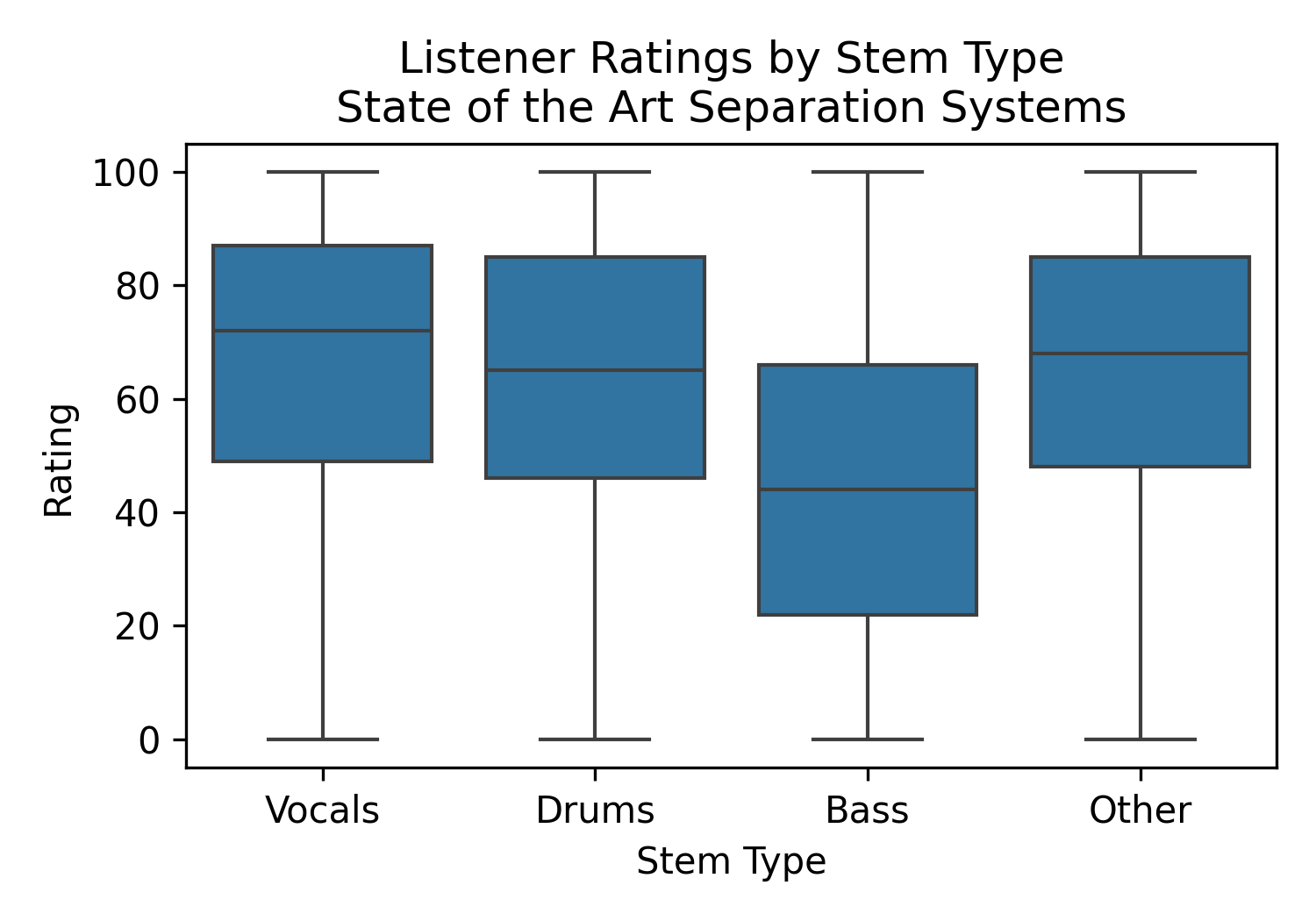
Figure 1: Rating distribution of state-of-the-art systems, by stem type. Bass estimates often suffer due to masking by other sounds, impacting their perceived quality.
Listener Study Results
The listener study revealed a pronounced preference for outputs from state-of-the-art separation systems over legacy methods. Notably, hidden references were consistently rated highest, followed by systems like SCNet-large and HTDemucs-ft, outshining even the oracle IRM1 method. This could imply the importance of perceivable musical qualities over strict mathematical accuracy in generating ideal ratio masks.
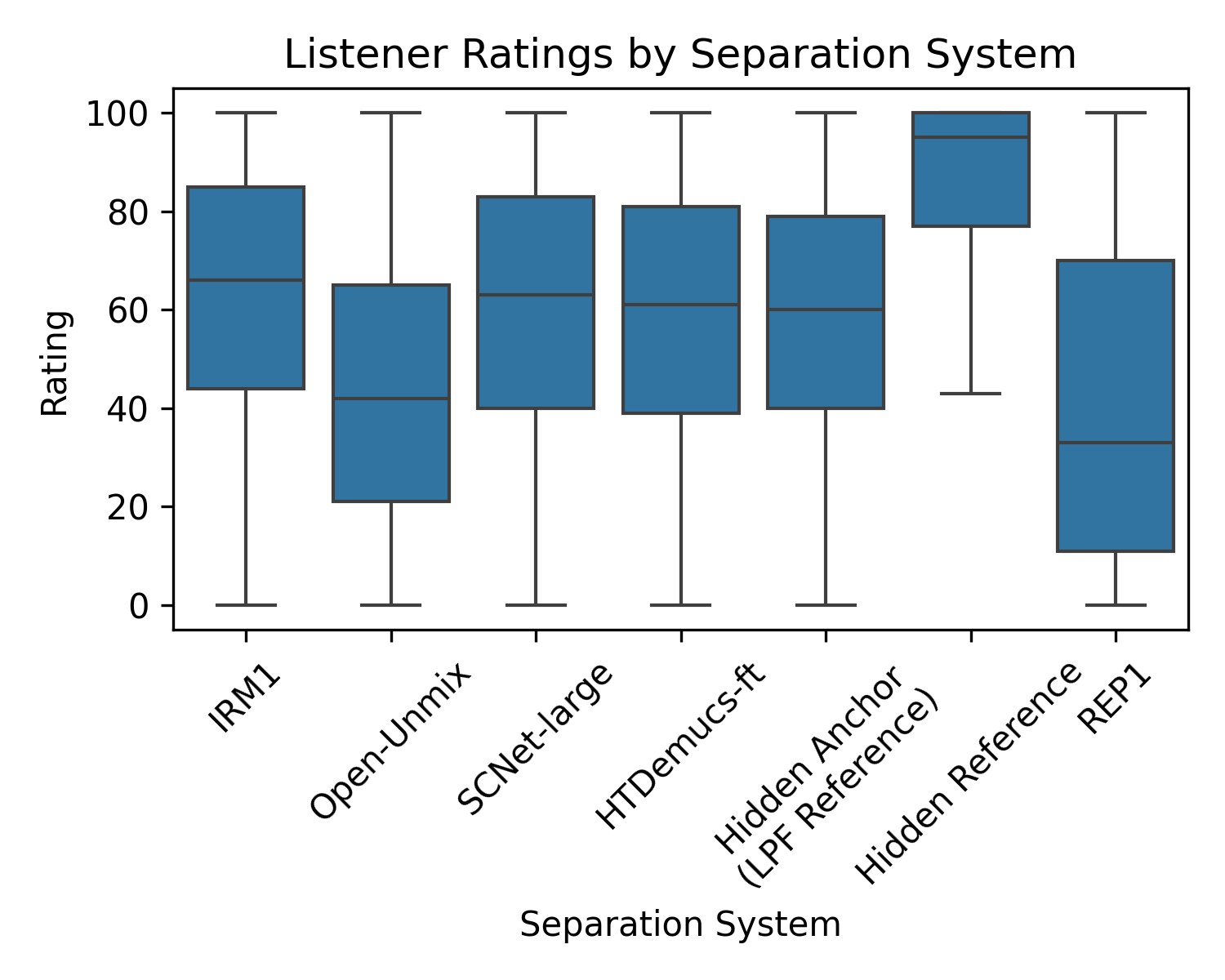
Figure 2: Rating distribution of all stems, by separation system. Listeners prefer state-of-the-art systems over legacy ones.
Correlation Studies
By employing Kendall’s τ as a correlation metric, the study uncovered that artifact errors more acutely predicted human perception than interference errors across most stem types, except bass. The investigation into SI-SDR and SI-SAR demonstrated their effectiveness, particularly for instrument stems where traditional metrics fell short.
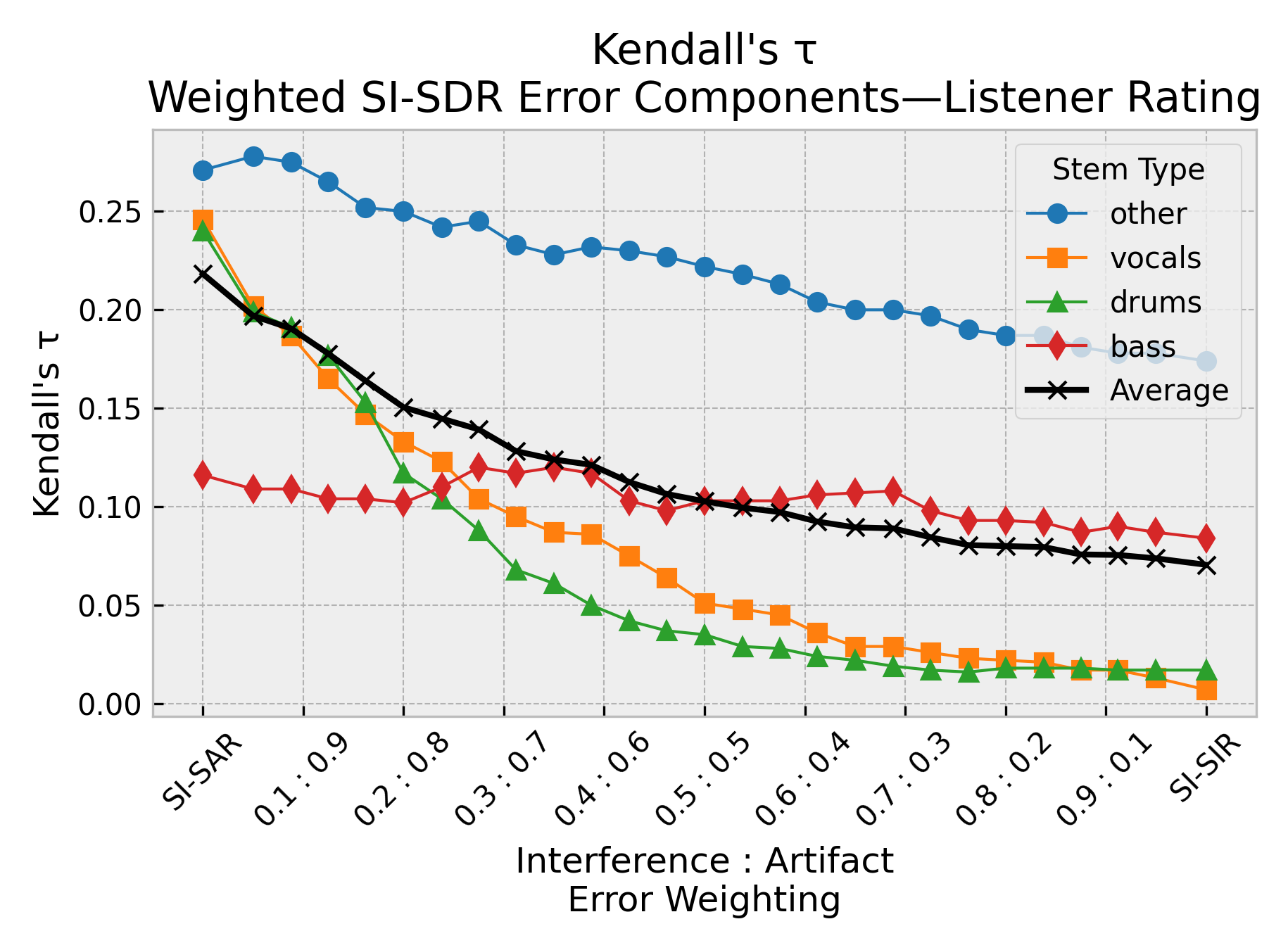
Figure 3: Reweightings of the scale-invariant SDR error terms (SI-SIR vs.\ SI-SAR). Artifact errors better predict perception across multiple stem types.
Despite SDR's dominance in vocal estimates, SI-SAR and FAD with CLAP embeddings showed potential for improved perceptual correlation, emphasizing the need for stem-specific and listener-informed metrics.
Fréchet Audio Distance Results
Interestingly, the study concluded that none of the embedding-based metrics, including those derived from speech-trained models like HuBERT and Wave2Vec2, correlated positively with human perception for vocal separation tasks, despite some success in instruments. Nevertheless, CLAP-LAION-music embeddings led to better results for instrument stems compared to other embeddings.
Conclusion
The paper identifies significant discrepancies between objective and subjective assessments of music source separation quality. It underscores the limitations of current metrics like SDR for evaluating perceptual quality and highlights the growing importance of developing perception-informed metrics such as SI-SAR and FAD for certain instruments. These findings stress the importance of comprehensive, listener-driven evaluation frameworks to guide future development in music source separation technologies. By making their raw listener data publicly available, the authors support transparency and provide a foundation for further research into improving both evaluation methodologies and separation techniques.