- The paper presents a resource-efficient FPGA framework that accelerates spiking neural networks on low-end devices, enabling rapid deployment in edge AI applications.
- The methodology features a novel tiling and crossbar design, using only 6358 LUTs and 40.5 BRAM, to optimize compute and minimize hardware resource usage.
- Key experiments, including MNIST inference at 0.52ms per image and 0.198 mJ energy per image, validate the framework's practical efficiency and scalability.
A Robust, Open-Source Framework for Spiking Neural Networks on Low-End FPGAs
Introduction
This work presents a resource-efficient, highly adaptable framework for the acceleration of spiking neural networks (SNNs) on low-end field-programmable gate arrays (FPGAs) ["A Robust, Open-Source Framework for Spiking Neural Networks on Low-End FPGAs", (2507.07284)]. Unlike previous approaches targeting costly high-end devices or requiring application-specific SNN topologies, the architecture achieves a significant balance between flexibility and resource utilization. Targeting fully connected and any-to-any SNNs, the framework supports 8-bit quantized weights and optimizes compute through a novel tiling and crossbar methodology that can be realized efficiently even on commodity FPGA devices.
Architectural Approach
The architecture is partitioned into three principal modules: the synaptic crossbar, leaky-integrate-and-fire (LIF) neuron units, and a centralized control unit. Trained neural networks are decomposed into "tiles," each encapsulating a block of 16 pre-synaptic and 16 post-synaptic neurons (up to 256 synapses). The FPGA architecture synchronously streams spike states, weights, and membrane potentials through BRAM-resident tiles, orchestrated by the control unit. A pipelined synaptic array processes presynaptic spikes and weights, propagating synaptic inputs to a set of IF units that implement the integrate-and-fire function in pure integer arithmetic without a leak factor, enhancing hardware simplicity.
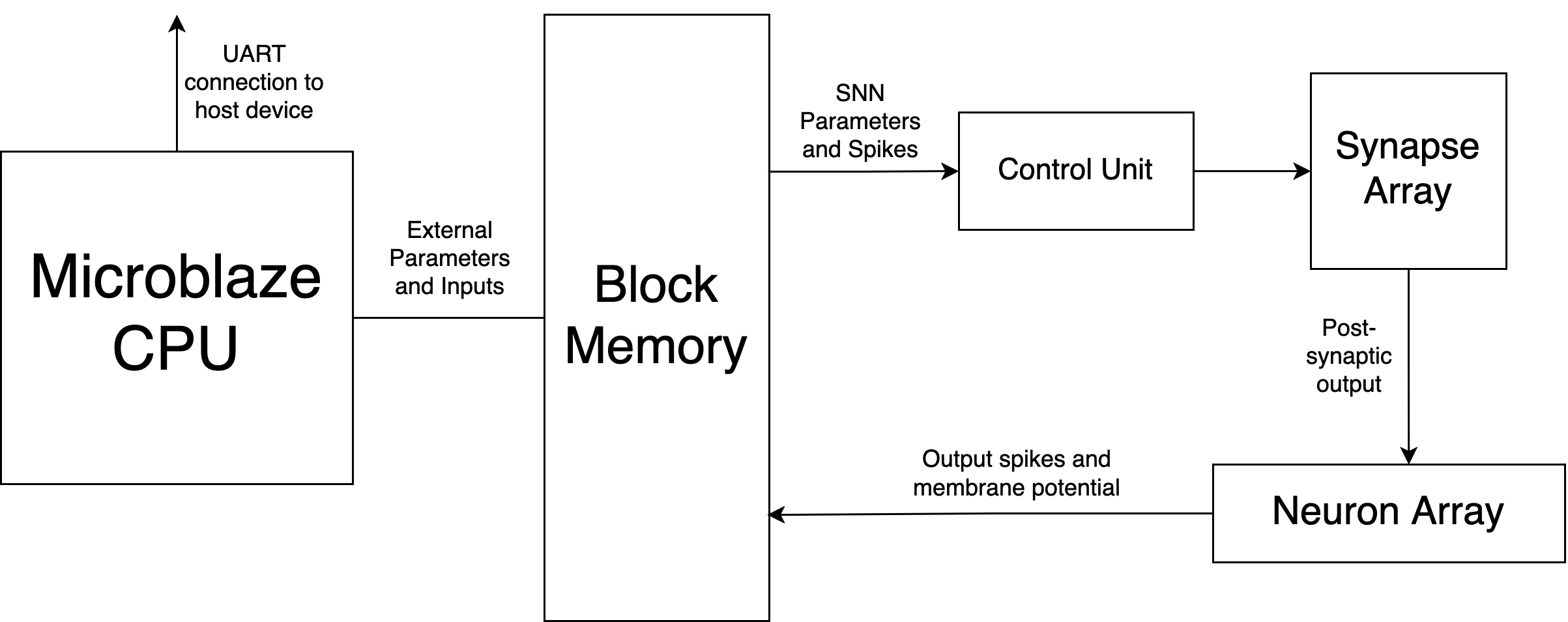
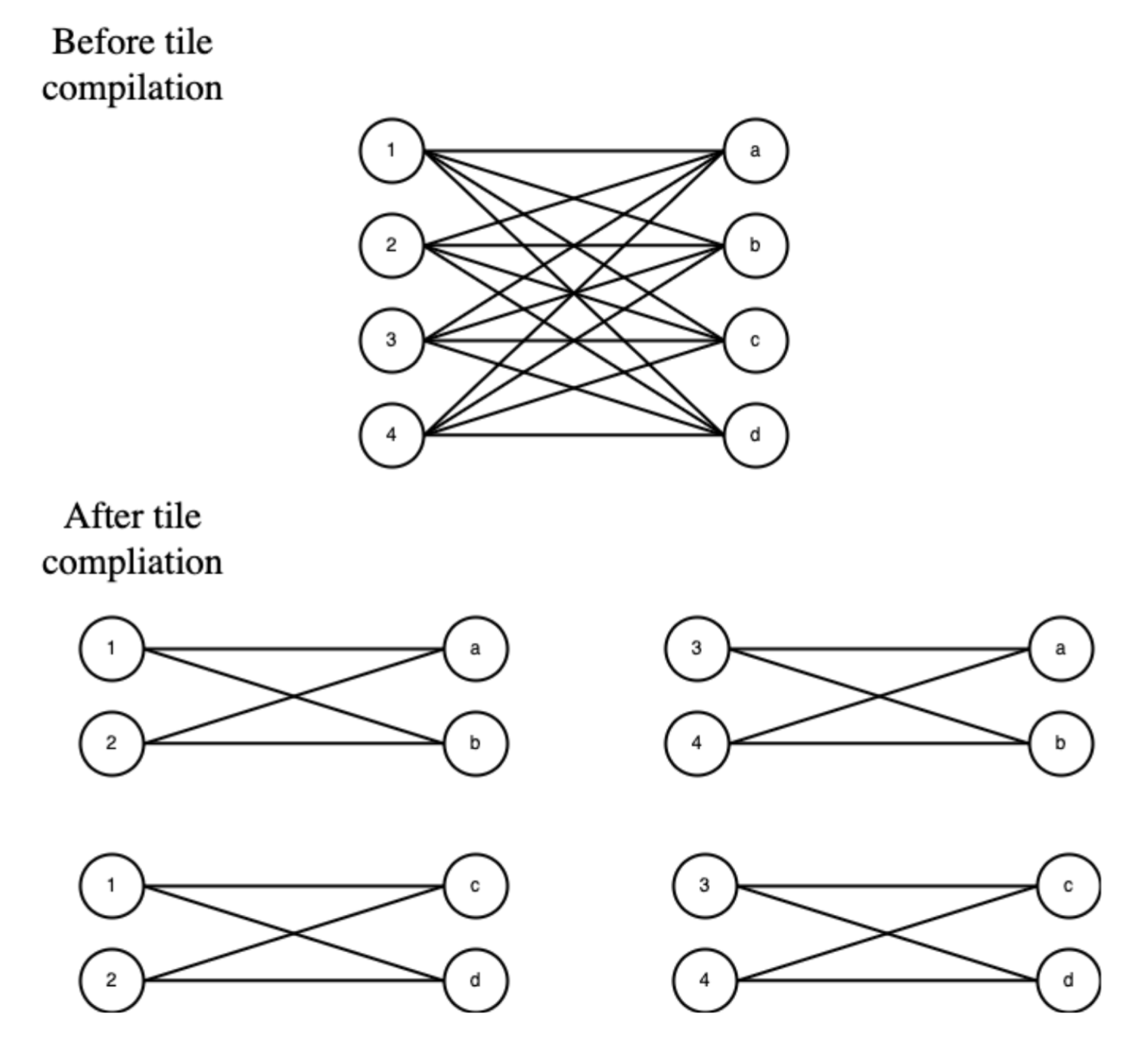
Figure 1: The SNN accelerator architecture consists of IF neuron units, a centralized control unit, and a synaptic crossbar for parallel spike-weight accumulation.
The crossbar employs a 16×16 weight matrix and processes binary spike activations through adder trees, yielding 16 summed currents each timestep. Input values are injected directly into neuron membrane potentials. Synchronization of data movement is maintained using FIFOs to ensure proper sequencing, especially for tile index transitions.
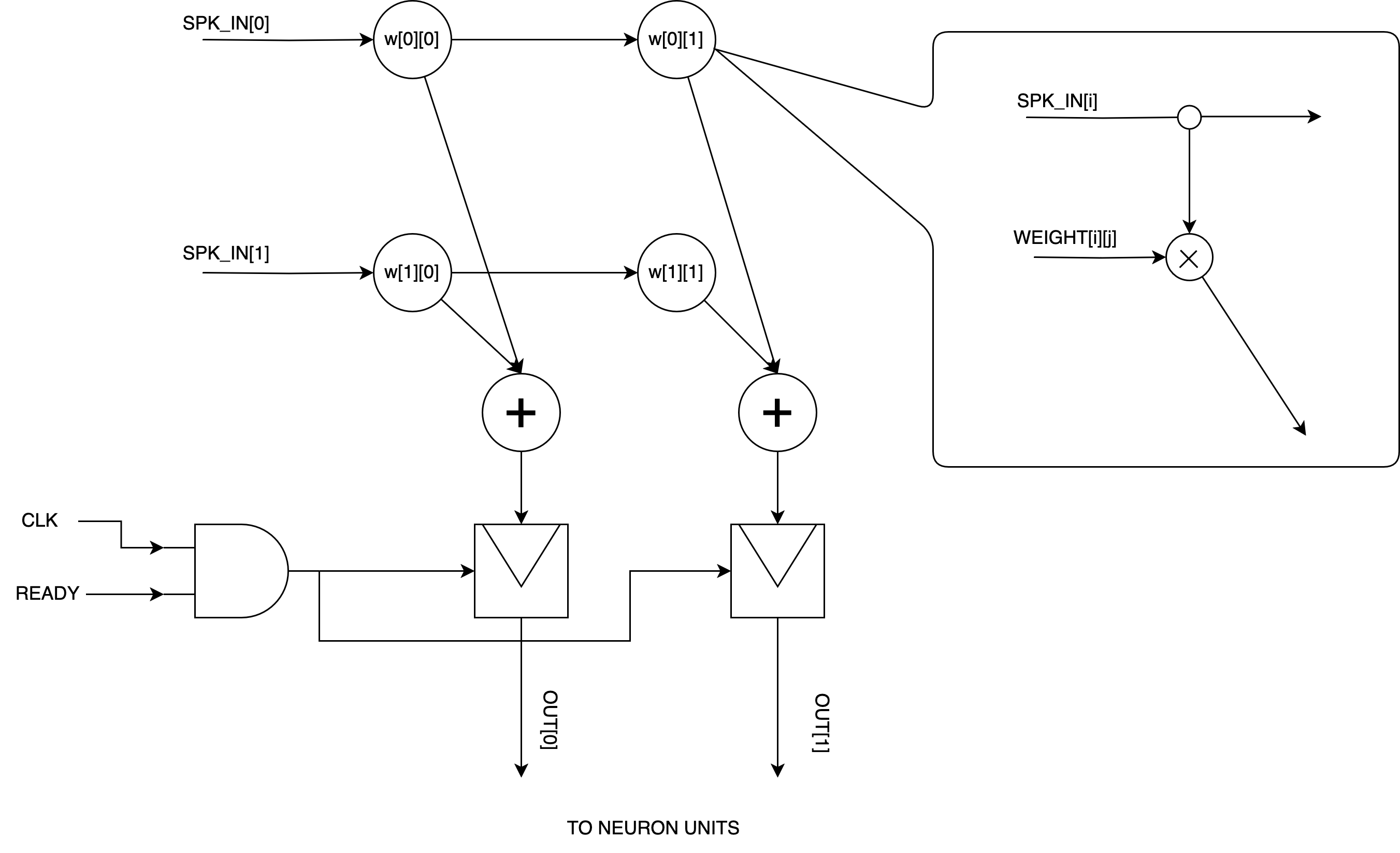
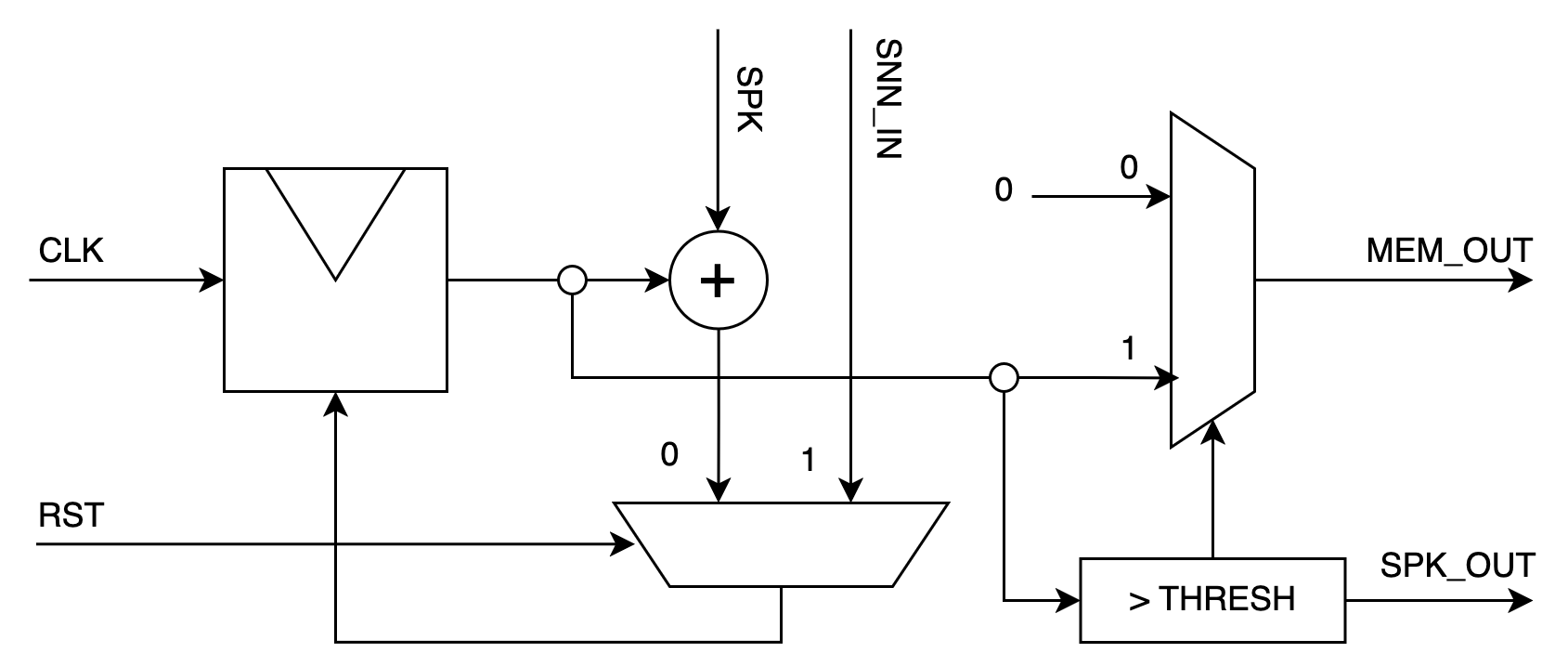
Figure 2: The synaptic array computes weighted accumulations for 0/1 spike activations using minimal delay and resource overhead.
Unlike prior work (e.g., "FireFly" [FireFly, IEEE TVLSI 2023] and "SyncNN" [SyncNN, FPL 2021]) focused on large FPGAs or convolutional SNNs with high resource budgets, this design requires only 6358 LUTs and 40.5 BRAMs for SNN logic, enabling deployment on resource-constrained FPGAs like the Xilinx Artix-7.
Software and Compilation Pipeline
A PyTorch-based training interface is provided via the SNNTorch library, employing surrogate gradient learning and backpropagation through time with no-leak IF neurons and a synaptic delay of one. Trained models are quantized to int8 and compiled into hardware-ready tiles. The compilation output supports direct deployment via C arrays or FPGA memory initialization files, allowing seamless integration with the on-chip processor.
Experimental Results
Fully-Connected SNN on MNIST
The framework was evaluated by training and deploying a 784-128-10 SNN on the MNIST dataset, quantized to 8-bit weights and executed at 100 MHz on a Digilent Basys3 FPGA. The design achieves 0.52 ms per image inference, consuming 0.381 W, corresponding to 0.198 mJ per image or 1.95 nJ per synaptic operation. Notably, these results are achieved using only 6358 LUTs and 40.5 BRAM for SNN logic—demonstrating competitive efficiency in resource-constrained environments.
Any-to-Any SNN and General Logic
To verify architectural generality, hand-coded any-to-any SNNs were deployed for temporal pattern problems, such as spike interval parity encoding. The recurrent architecture operating over multiple tiles correctly computes the required logical function, confirming robust support for arbitrary connectivity.
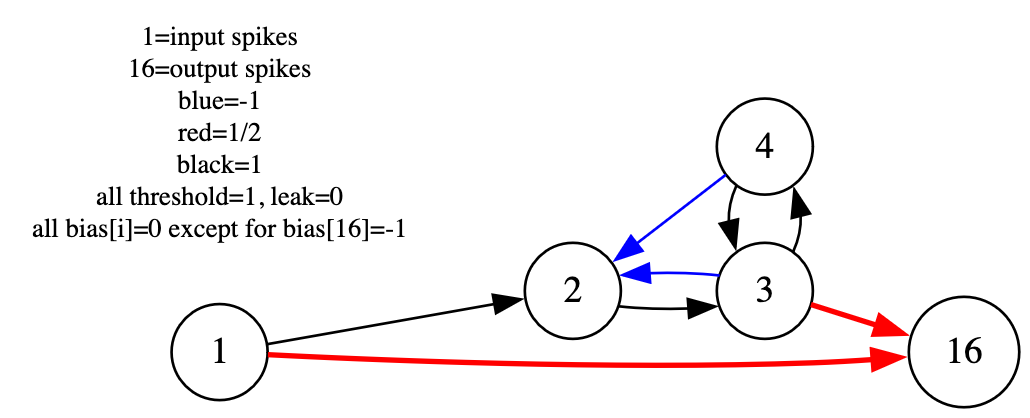
Figure 3: The RSNN architecture implements parity computation by chaining neuron and logic gate motifs across tiles, utilizing the tiling strategy to support non-standard connectivity patterns.
Implications and Limitations
This work directly addresses accessibility in neuromorphic computing, providing an open-source pipeline deployable on low-cost, low-power hardware. The architecture fundamentally broadens the class of SNNs deployable on edge devices, embedded robotics, and IoT applications, circumventing the cost and inflexibility of ASIC-based offerings (e.g., Loihi [Loihi, IEEE Micro 2018], TrueNorth [TrueNorth, IEEE TCAD 2015]).
By decoupling SNN deployment from architectural rigidness and high resource requirements, the framework facilitates:
- Experimentation with novel network topologies—including hand-designed logic circuits and bio-inspired architectures
- Rapid deployment of quantized, PyTorch-trained SNNs with minimal platform porting overhead
- Scalability to larger SNNs on platforms with more BRAM and logic, or adaptation to unconstrained embedded FPGAs
A core constraint is synchronous operation; the pipeline does not exploit idle time during non-spiking activity, which diminishes energy efficiency at large scale relative to event-driven accelerators. Furthermore, support for automatic training of arbitrary any-to-any SNNs is limited by the lack of robust training algorithms for highly recurrent or irregular architectures—though hand-crafted solutions are supported.
Future Directions
Potential enhancements include asynchronous event-driven computation to exploit input sparsity, improved training support for arbitrary connectivity (including convolutional structures), and scaling to higher-end or alternative embedded FPGAs with expanded RAM and logic resources. Integrating advanced coding schemes or compressed dataflows could yield further efficiency gains for large SNN deployments.
Conclusion
This framework represents a significant contribution toward democratizing spiking deep learning architectures on budget- and power-constrained hardware. By fusing a minimal FPGA architecture with open-source training and compilation tools, it lowers barriers for advanced neuromorphic and edge inference research. The demonstrated flexibility and low resource footprint position this approach as an effective platform for future SNN algorithmic exploration, hardware/software codesign, and real-world low-power AI tasks.