- The paper presents a novel hierarchical embedding framework that integrates similarity graphs to enhance job classification.
- It leverages pre-trained language models and margin-based loss functions to capture both semantic content and hierarchical relationships.
- The model achieves high accuracy with SOC at 94.8% and Carotene at 89.3%, offering a scalable solution for complex job taxonomies.
"Hierarchical Job Classification with Similarity Graph Integration"
The paper "Hierarchical Job Classification with Similarity Graph Integration" (2507.09949) introduces a novel approach in the context of job classification leveraging both hierarchical structures and similarity graphs. This method enhances the classification accuracy of job postings by embedding them in a latent space alongside hierarchical industry categories such as SOC (Standard Occupational Classification) and an internal taxonomy named Carotene. This research incorporates graph-based relationships to improve the contextual understanding of job data.
Introduction to Hierarchical Job Classification
The accurate classification of job postings is vital for efficient job recommendation systems, search ranking, and labor market analysis. Traditional methods often struggle with capturing the hierarchical intricacies of job taxonomies. To address this, the paper proposes embedding both job postings and category hierarchies into a unified lower-dimensional space using a novel classification model. By doing so, it captures both hierarchical and similarity relationships, enhancing classification accuracy.
Methodology
Embedding Framework
Jobs are transformed using pre-trained LLMs such as BERT, and each posting is embedded into a vector space capturing semantic and syntactical information. Both SOC and Carotene categories are represented using trainable matrices, ensuring that these embeddings maintain their hierarchical and graph structures.
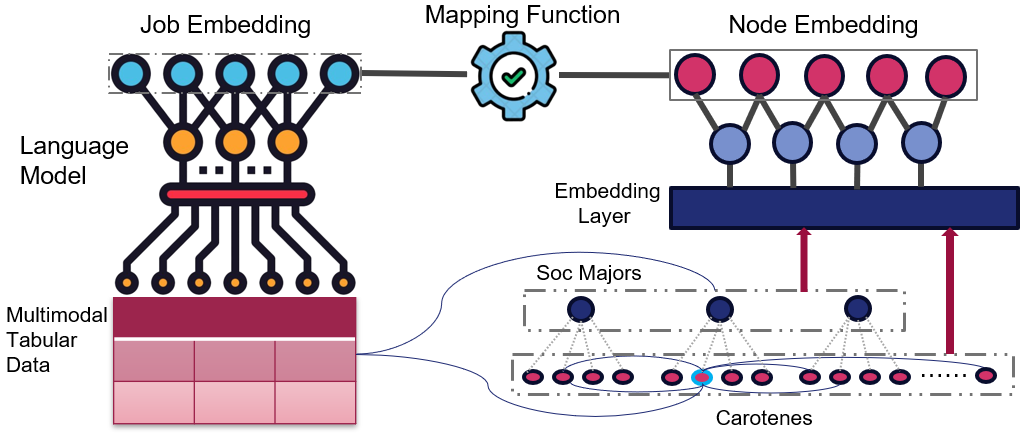
Figure 1: Framework of the Hierarchical Job Classification.
Loss Functions
The paper introduces a series of loss functions to maintain hierarchical integrity and capture similarity relations:
- Loss for SOC and Carotene Classification: Categorical cross-entropy loss functions are applied separately for SOC and Carotene classification tasks.
- Hierarchy-Aware Loss: Margin-based loss functions ensure embeddings respect hierarchical relationships between SOCs and Carotenes.
- Graph-Aware Loss: Similar margin-based losses preserve similarity relations between Carotenes in the graph structure.
Experimental Setup
Data from X Company's internal database, including 456,000 job postings, was used to train the model. Job listings were labeled with SOC and Carotene, which was used to structure a two-level hierarchical tree. The Carotene similarity graph, connecting Carotenes by similarity scores, was integrated into the embedding process.
The proposed hierarchical classification model outperformed traditional methods in both SOC and Carotene accuracy. The Hierarchical Sim Classification (Hard) model achieved best-in-class results, with SOC and Carotene accuracy reaching 94.8% and 89.3%, respectively. The model's effectiveness is further validated through t-SNE visualization, clearly showing embeddings clustering according to hierarchical and similarity-based relationships.
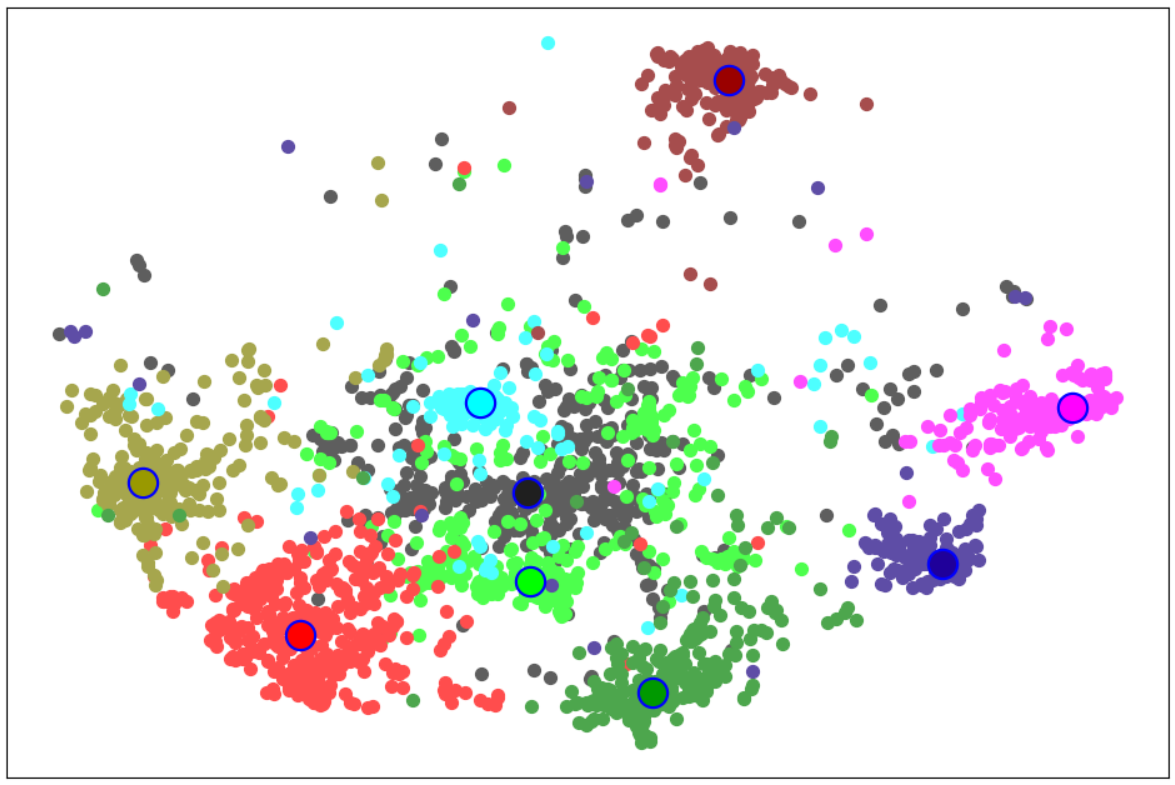
Figure 2: t-SNE Plot of SOCs and Their Corresponding Carotene Embeddings from Hierarchical-Sim-Classification (Hard).
Implications and Future Work
This research presents a robust framework for hierarchical job classification, significantly enhancing the efficacy of job data handling processes. Future work may explore extending this framework to multi-level taxonomies and investigating additional graph-based relationships to further improve classification performance.
Conclusion
The integration of similarity graphs and hierarchical relationships into the model presents a significant advancement in job classification methodologies, providing a more nuanced understanding of job data. This framework not only improves classification accuracy but also offers a scalable solution that can be adapted to various hierarchical classification tasks across different domains.