- The paper introduces a bottom-up approach where language models learn from KG-derived QA tasks, leading to superior domain-specific reasoning in the medical field.
- It employs a structured curriculum generation pipeline with diversity, complexity, and quality filtering to effectively compose simple medical primitives into complex diagnostic tasks.
- Experimental results on ICD-Bench show that curriculum-tuned models outperform state-of-the-art baselines, indicating promising advances toward efficient domain-specific superintelligence.
Bottom-up Domain-specific Superintelligence: A Reliable Knowledge Graph is What We Need
This paper introduces a method for achieving domain-specific superintelligence by training LLMs on structured knowledge derived from knowledge graphs. The authors propose a bottom-up approach, where models learn to compose simple domain concepts into complex ones by fine-tuning them on tasks generated from KG paths. The method is validated in the medical domain using the UMLS KG, and the resulting model, QwQ-Med-3, shows significant performance gains on a new benchmark, ICD-Bench, compared to state-of-the-art models.
Structured Curriculum Generation
The authors introduce a task generation pipeline that synthesizes tasks from domain-specific primitives, allowing the model to explicitly acquire and compose these primitives for reasoning. The pipeline involves traversing paths on a medical KG to generate QA pairs, along with structured thinking traces derived from diverse medical primitives.
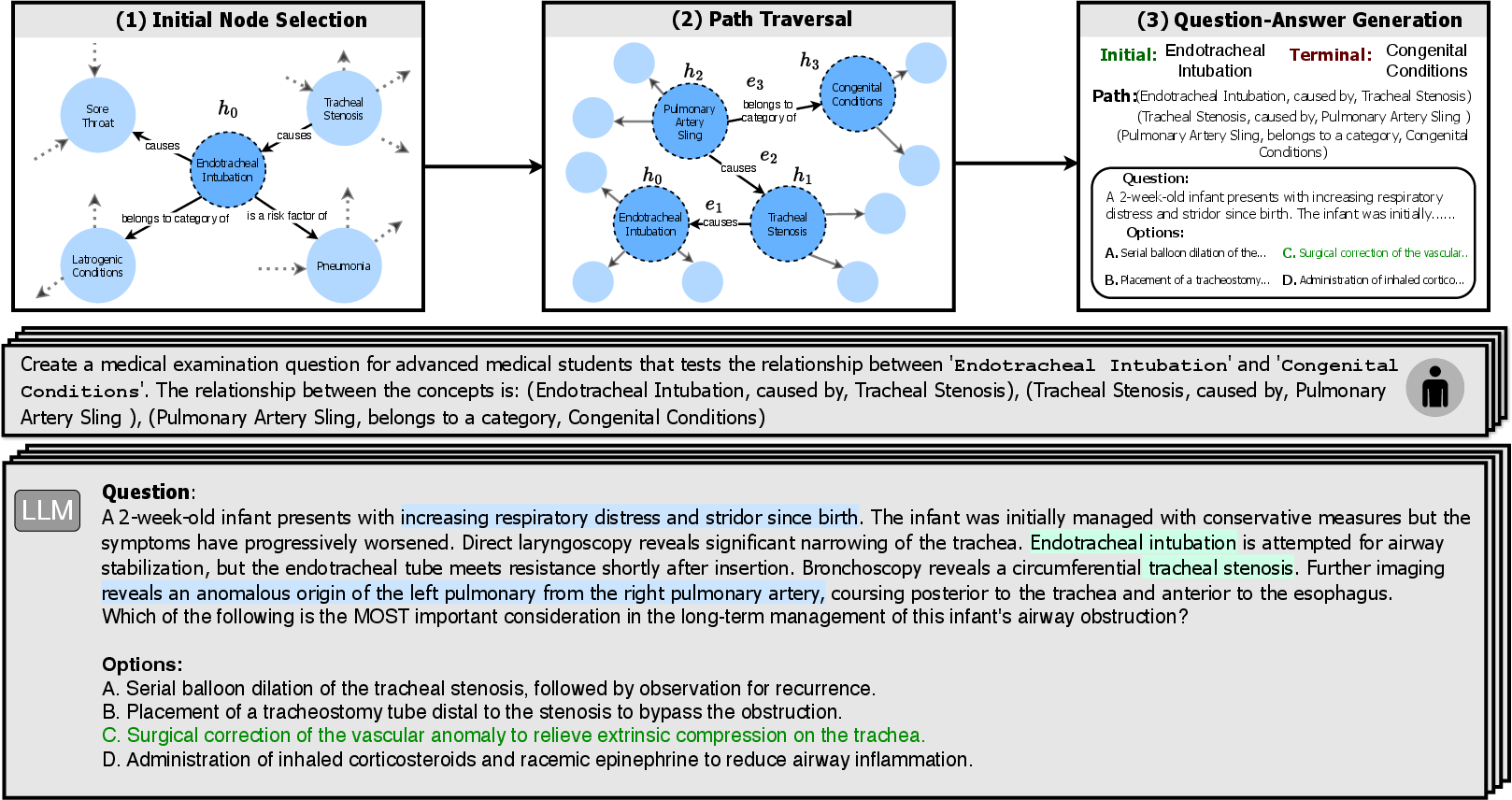
Figure 1: Generating QA tasks from a KG path involves exploring KG paths to derive QA pairs, mapping a sampled path to a natural language QA task, and highlighting entities to require recalling latent entities and reasoning along the KG path.
The task generation pipeline (Figure 2) aims to curate reasoning tasks using KGs, guided by three core design principles: closed-endedness, steerable complexity, and diversity. The pipeline comprises steps such as diversity sampling, complexity sampling, quality filtering, thinking trace generation, and correctness filtering.
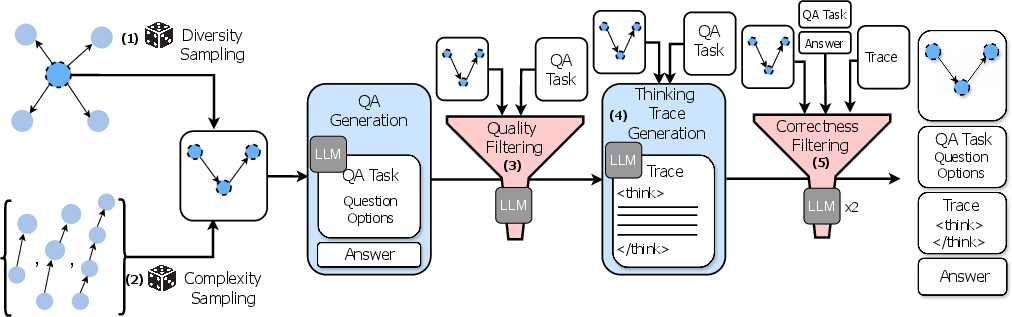
Figure 2: The curriculum curation pipeline starts from KG-derived paths, samples for diversity and complexity, filters for quality, generates thinking traces, and performs correctness filtering to ensure factual alignment and answer validity.
ICD-Bench: A Diagnostic Benchmark
To quantify domain-specific capabilities of models on reasoning tasks across medical domains, the authors introduce an evaluation suite, ICD-Bench, comprising medical QA tasks stratified across 15 categories of the ICD taxonomy (Figure 3).

Figure 3: The ICD-Bench evaluation suite consists of 15 medical sub-specialties derived from the ICD-10 taxonomy, with sample QA items illustrating the benchmark's diversity in medical reasoning tasks.
The distributional statistics of the curated training curriculum are shown in Figure 4, which highlight the breakdown of entities across ICD categories, the distribution of relation types, and the hop-wise distribution of thinking trace lengths.
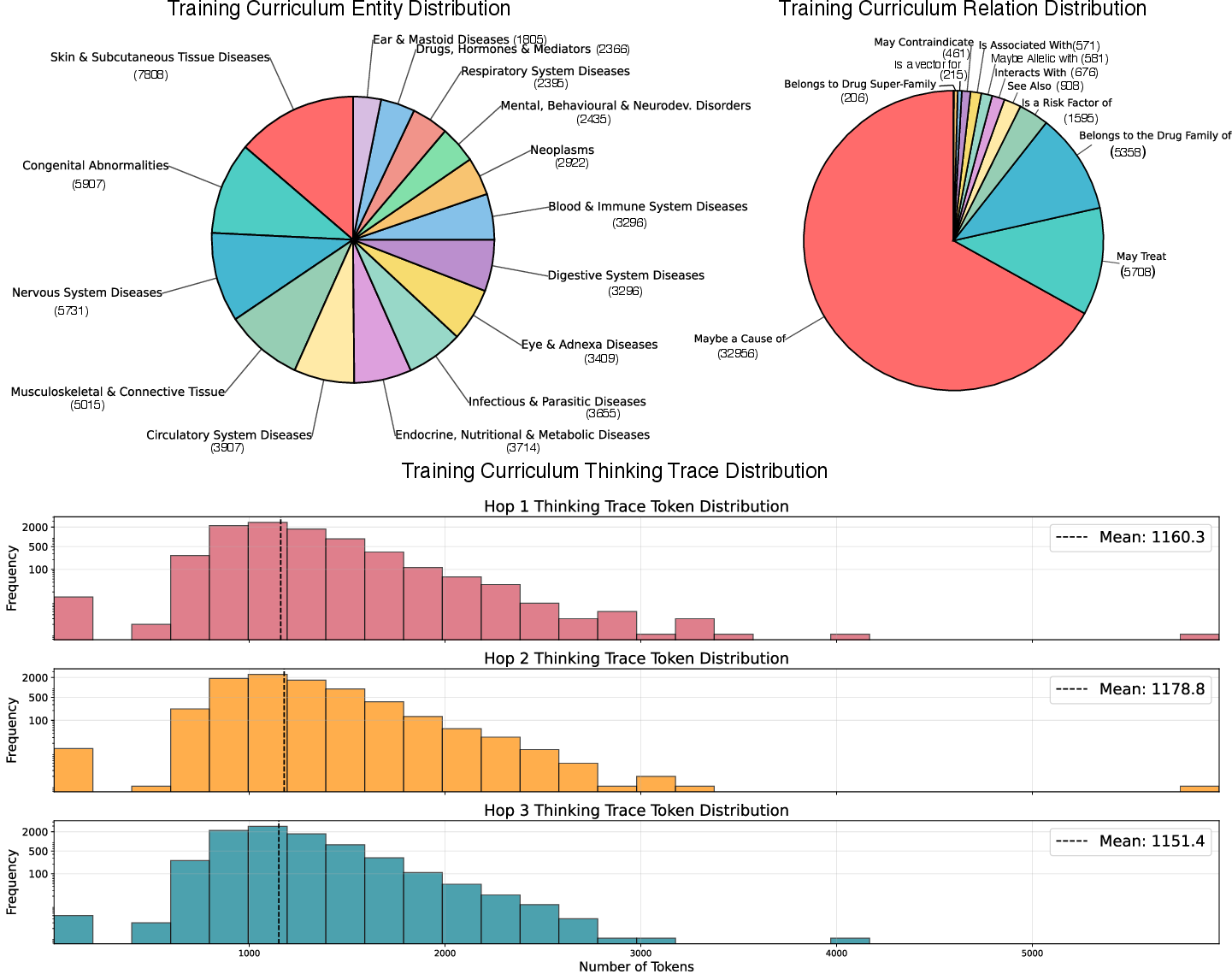
Figure 4: The curated training curriculum spans 24,000 QA items grounded in UMLS KG paths, with breakdowns of entities, relation types, and hop-wise distribution of thinking trace lengths.
Experimental Results and Analysis
Experiments on ICD-Bench reveal that curriculum-tuned models significantly outperform strong baselines, including proprietary and open-source reasoning models, across all 15 categories. Furthermore, performance improves with deeper and more diverse KG curricula, with curriculum depth proving especially crucial for the most challenging reasoning tasks. Scaling curves (Figure 5) demonstrate that deeper curriculum models benefit more from parallel scaling, while shallower models remain amenable to refinement.
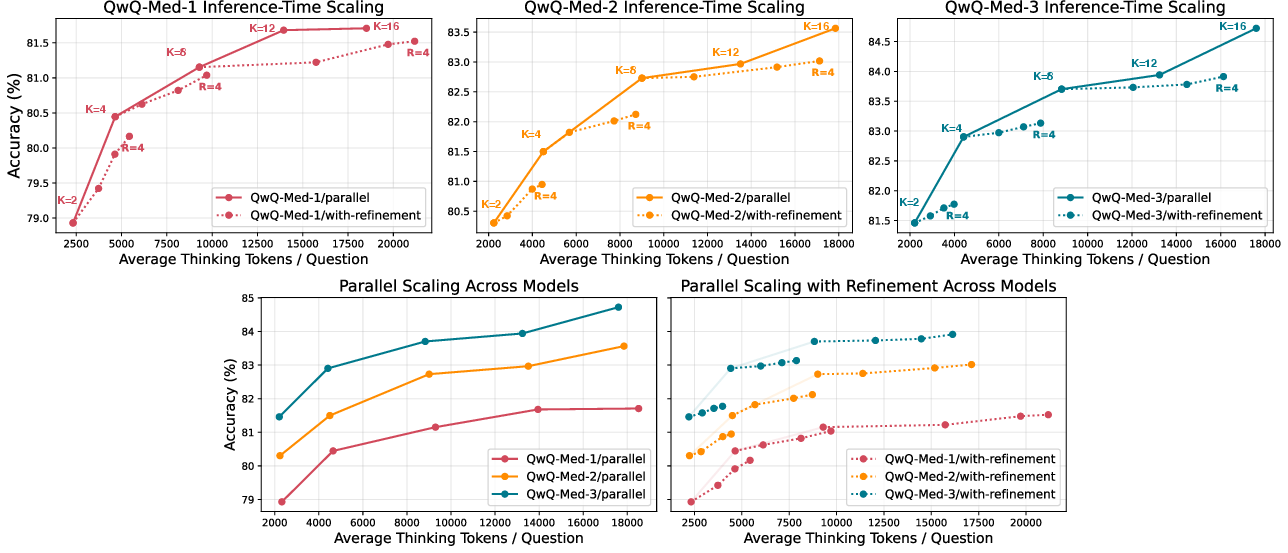
Figure 5: Inference-time scaling curves for curriculum-tuned models on ICD-Bench show per-model curves for parallel scaling and iterative refinement, as well as a comparison of per-scaling technique curves.
Ablation studies disentangle the contributions of path length, diversity, and complexity sampling, revealing that compute-optimal curricula depth distribution should adapt to task difficulty (Figure 6). Curriculum-tuned models also demonstrate higher recall and effective reasoning across all hop levels, indicating successful use of KG primitives for reasoning (Figure 7). The impact of task difficulty on model performance is further illustrated in Figure 8, which highlights that gains from curriculum tuning widen on increasingly challenging tasks.
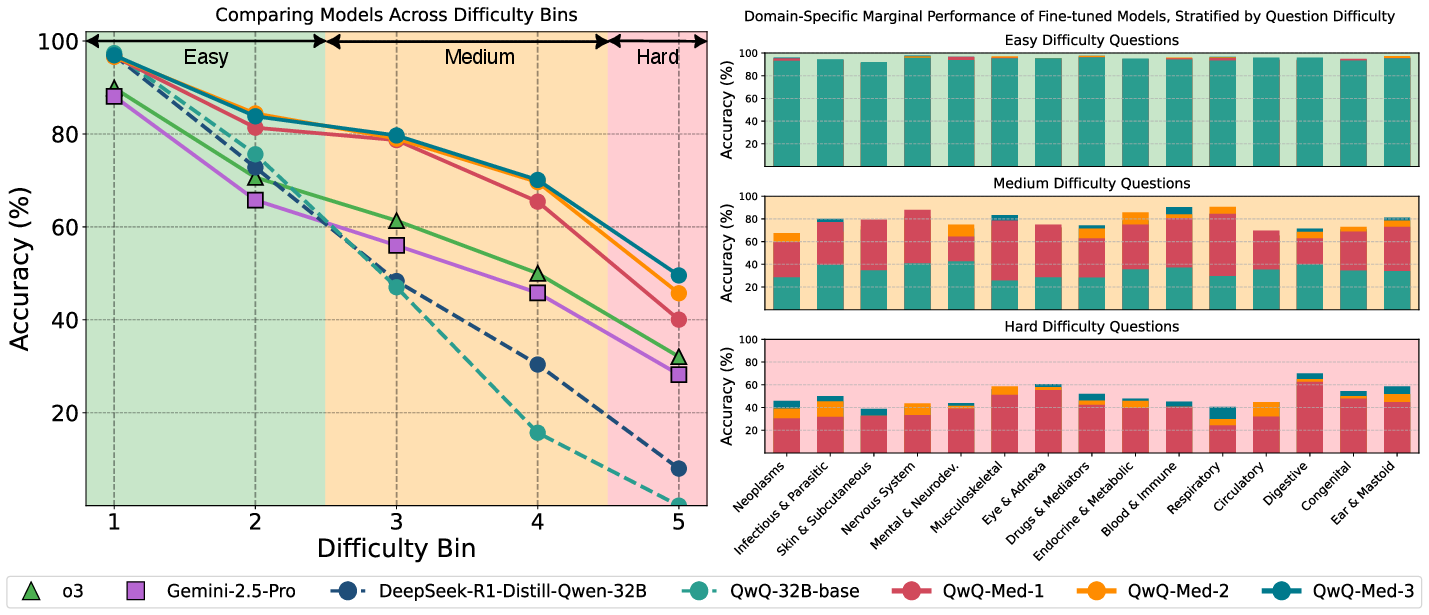
Figure 8: Performance across task difficulty bins on ICD-Bench shows declining accuracy with increasing difficulty, with curriculum-tuned models exhibiting improved robustness and widening gains on challenging tasks.
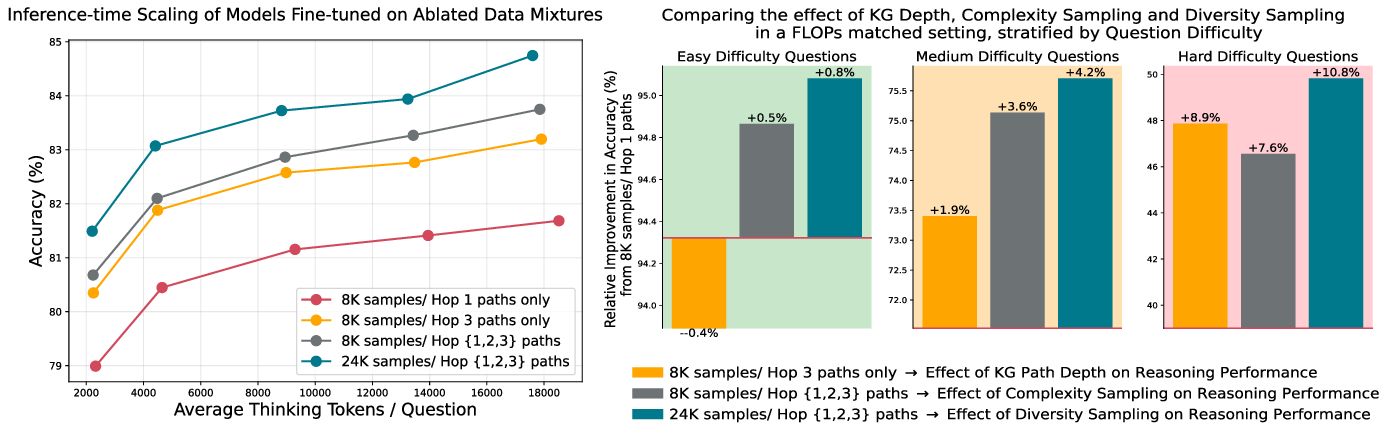
Figure 6: The effects of KG path depth, complexity sampling, and diversity sampling on performance show that performance improves with deeper paths, balanced path-length sampling, and greater diversity.
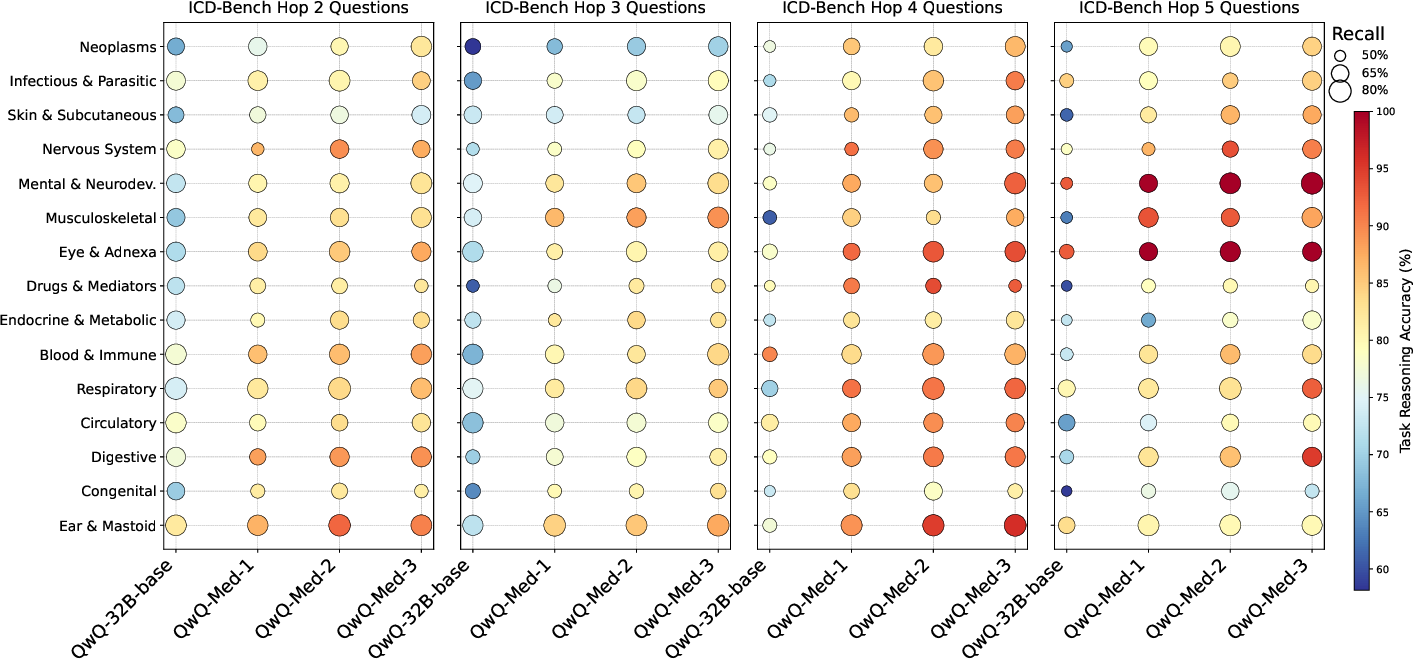
Figure 7: Recall and reasoning performance across ICD-Bench tasks stratified by KG path length indicate that curriculum-tuned models demonstrate higher recall and effective reasoning across all hop levels.
Implications and Future Directions
The results suggest a promising direction for achieving domain-specific superintelligence by explicitly training LMs on structured domain knowledge. The authors envision a future in which a compositional model of AGI emerges from interacting superintelligent agents, much like how the human society hierarchically acquires ever deeper expertise. Since LLMs that are fine-tuned for superintelligence can be relatively small (e.g., 32B parameters), this bottom-up approach may also significantly cut down on training/inference energy costs. One area for future work involves exploring the generalizability of this method to other domains, such as law or banking, that lack canonical KGs or standardized abstractions.