When few labeled target data suffice: a theory of semi-supervised domain adaptation via fine-tuning from multiple adaptive starts
Abstract: Semi-supervised domain adaptation (SSDA) aims to achieve high predictive performance in the target domain with limited labeled target data by exploiting abundant source and unlabeled target data. Despite its significance in numerous applications, theory on the effectiveness of SSDA remains largely unexplored, particularly in scenarios involving various types of source-target distributional shifts. In this work, we develop a theoretical framework based on structural causal models (SCMs) which allows us to analyze and quantify the performance of SSDA methods when labeled target data is limited. Within this framework, we introduce three SSDA methods, each having a fine-tuning strategy tailored to a distinct assumption about the source and target relationship. Under each assumption, we demonstrate how extending an unsupervised domain adaptation (UDA) method to SSDA can achieve minimax-optimal target performance with limited target labels. When the relationship between source and target data is only vaguely known -- a common practical concern -- we propose the Multi Adaptive-Start Fine-Tuning (MASFT) algorithm, which fine-tunes UDA models from multiple starting points and selects the best-performing one based on a small hold-out target validation dataset. Combined with model selection guarantees, MASFT achieves near-optimal target predictive performance across a broad range of types of distributional shifts while significantly reducing the need for labeled target data. We empirically validate the effectiveness of our proposed methods through simulations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies a practical question in machine learning: how can we make a model work well in a new situation (the “target domain”) when we only have a few labeled examples there, but lots of data from other places (the “source domains”) and many unlabeled examples from the target?
The authors build a theory showing when “a few target labels are enough.” Their main idea is to start from strong unsupervised domain adaptation (UDA) models that already learn what source and target have in common, and then fine-tune the model in just the small parts that differ. They also propose a simple, reliable way to pick the best starting point when you’re not sure how the source and target are related.
Key Objectives
The paper asks and answers three easy-to-understand questions:
- Can using a few target labels beat learning only from target data, or only from source data?
- How many target labels do we actually need to get strong performance?
- What kinds of changes between source and target can be fixed with just small adjustments?
Methods and Approach (with simple analogies)
The setup: domains, labels, and “shifts”
- Imagine training a robot to recognize objects in bright daylight (source domains), then deploying it at sunset in fog (target domain). The robot has lots of practice questions (images) without answers from the sunset fog, and only a handful with answers (the few labeled target samples).
- The problem is that the new setting changes the data in specific ways. The paper classifies these changes and shows how to correct them with minimal target labels.
Structural Causal Models (SCMs): how the data is made
- Think of SCMs as a recipe that explains how data is created: what causes what, how features connect, and how noise creeps in.
- An “intervention” is like changing an ingredient (more salt, less sugar). Interventions cause the “shift” between source and target data.
- Using SCMs helps us reason about what changed and how to fix it.
Unsupervised Domain Adaptation (UDA): learning common ground
- UDA uses source labels and unlabeled target data to learn a shared feature space that works in both places.
- Two helpful UDA ideas:
- DIP (Domain-Invariant Projection): find features that look similar across source and target (like agreeing on a shared set of landmarks in two cities).
- CIP (Conditional Invariant Penalty): align features that behave the same way for each label across multiple sources (like learning that “stop signs are red” in all neighborhoods).
- OLS (Ordinary Least Squares on source): a simple baseline that just learns from source labels.
Fine-tuning: adjusting only what changed
- After UDA learns the common parts, fine-tuning tweaks the model in the small, specific directions that differ in the target domain. Think of it as turning a few knobs instead of rebuilding the whole machine.
- The trick is to pick those knobs (directions) carefully so you need only a few target labels.
Minimax guarantees: worst-case safety
- “Minimax” is a way to say, “Even in the worst reasonable case, this method won’t do poorly.”
- The authors prove that their fine-tuning strategies can achieve near-optimal performance with very few target labels, as long as the changes between source and target are low-dimensional (only a few knobs actually changed).
Three types of shifts and matching methods
When different things change between source and target, you use different starting points and fine-tuning directions:
- Confounded Additive (CA) shifts: a hidden factor (like lighting) shifts the data in a few directions, affecting both features and labels.
- Use DIP with a covariance-matching idea to find the stable subspace, then fine-tune only along the small set of changed directions.
- Sparse Connectivity (SC) shifts: only a few connections among features change (like rewiring a handful of cables).
- Start from OLS on source and fine-tune only the coefficients tied to those changed connections.
- Anticausal Weight (AW) shifts: the way labels influence features changes (like the rule generating features from labels gets tweaked).
- Use CIP to find feature parts that stay consistent across sources, then fine-tune the small part that changed.
MASFT: Multi Adaptive-Start Fine-Tuning
- If you don’t know which type of shift you’re facing, MASFT tries several smart starting points (from different UDA methods), fine-tunes each a little, and picks the best one using a tiny validation set of target labels.
- This simple “try a few, choose the winner” strategy comes with guarantees that it will be close to the best possible choice.
Main Findings and Why They Matter
- Unlabeled target data alone isn’t enough to guarantee good performance. You need at least a few target labels to safely adjust the model.
- If the differences between source and target are low-dimensional (only a few things changed), then:
- You don’t need many target labels. You need roughly “one label per changed thing,” not “one per feature.”
- Fine-tuning from a good UDA start (DIP, CIP, or OLS) in just those few directions reaches near the best possible performance in theory (minimax-optimal or near-optimal).
- MASFT works well when you’re unsure about the type of shift. It selects the best starting point with a small validation set and achieves near-optimal performance across many kinds of shifts.
- The authors back up these claims with mathematical proofs and simulations.
Simple Implications and Impact
- Practical guidance: When you have very few target labels, don’t retrain everything. First learn the common parts with UDA, then fine-tune only the small set of changed parts.
- Less labeling, lower cost: You can get strong performance with far fewer labeled target samples, which is valuable in expensive settings like medical imaging or rare environments.
- Safer adaptation: The minimax guarantees mean your performance won’t collapse even in tough cases, making these methods more reliable in the real world.
- Easy-to-use fallback: MASFT helps when you don’t know what changed. Try multiple adaptive starts, fine-tune each a bit, and pick the best with a tiny validation set.
In short, the paper shows that smart fine-tuning—guided by how the source and target differ—can make a model adapt well with very few target labels, and it gives both the theory and practical tools to do so.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves uncertain or unexplored.
- Scope of structural assumptions: All guarantees hinge on linear, anticausal SCMs with invertible I−B; it remains open how the methods and minimax rates extend to nonlinear SCMs, mixed causal/anticausal graphs, cyclic/near-cyclic structures, or more general latent confounding beyond the specified additive form.
- Loss function and task generality: The theory is developed for squared loss in regression; extensions to classification (e.g., cross-entropy, 0–1 risk), structured prediction, and other losses are not provided.
- High-dimensional regimes: Many results assume invertible ΣX and do not address p ≫ n settings; developing regularized variants (e.g., ridge/Lasso-style) with guarantees under sparsity/low-rank or structured shifts is an open direction.
- Robustness to model misspecification: Performance and guarantees under misspecified shift types (e.g., mixtures of CA/SC/AW shifts, or partially valid assumptions) are not analyzed; precise degradation rates and robust variants are lacking.
- Identifiability and required heterogeneity: For CIP-based methods, the minimal number and diversity of source domains M needed to identify CICs that transfer to the target are not quantified beyond prior UDA results; practical diagnostics to verify CIC validity in the target are missing.
- Dependence on unlabeled target sample size: The paper relies on accurate estimation of subspaces/eigendecompositions (e.g., V from covariance differences) using unlabeled target data; explicit finite-sample requirements (sample complexity vs. spectral gaps) and the impact of mis-estimated subspaces on FT risk are not fully characterized.
- Dimension selection for low-dimensional shifts: The procedures assume knowledge (or accurate estimation) of the low-dimensional structure (e.g., rank r of the confounded additive shift, sparsity level for connectivity shifts); how to consistently estimate r/sparsity and how sensitive the methods are to over/under-estimation remain open.
- Lower bounds with unlabeled target data: For some settings (e.g., AW in the table, marked with *), minimax lower bounds explicitly accounting for unlabeled target data are not provided; whether unlabeled data can provably improve the lower bounds in those cases remains unresolved.
- MASFT selection under scarce labels: The reliability of model selection with a very small labeled target validation set is not analyzed (e.g., required validation size, selection bias, stability); alternatives without a hold-out (e.g., cross-validation, information criteria) and their guarantees are open questions.
- Negative transfer detection: Procedures to detect and avoid harmful starting points in MASFT when none is well-aligned with the true shift are not provided; statistical tests or stopping rules to prevent negative transfer would be valuable.
- Divergence choices in DIP/CIP: The theoretical guarantees are tied to moment-based divergences; whether adversarial divergences, MMD with specific kernels, or learned metrics can yield comparable or better guarantees is not established.
- Heavy-tailed/noisy labels: Assumptions require sub-Gaussian noise and clean labels; robustness to heavy-tailed distributions, outliers, or label noise in the small target set (and robust covariance/subspace estimation) is unaddressed.
- Finite-source-sample effects: Many results implicitly assume abundant source (and unlabeled target) data; excess risk bounds that explicitly track finite source sample sizes and their bias–variance trade-offs are missing.
- Practical computation beyond linear models: How to implement the proposed constrained FT subspaces in deep networks (mapping feature- or parameter-space subspaces like col(Σ−1V) to practical layers/parameter groups) is not discussed; convergence and optimization issues are open.
- Generalization to parameter-space FT: The paper motivates FT happening in low-dimensional parameter subspaces (e.g., adapters/LoRA) but does not formalize how to construct these subspaces from UDA starts in nonlinear models with theory-backed guarantees.
- Shift types beyond those considered: Label shift, covariate shift, and conditional shift outside the CA/SC/AW taxonomy are not treated; a unifying characterization of when each start (DIP/OLS-Src/CIP) is provably beneficial is lacking.
- Mixed/interacting interventions: Scenarios where interventions simultaneously affect B, b, and noise (and not in a strictly low-dimensional manner) are not theoretically covered; adaptivity and rates in such mixtures are open.
- Multiple/continual target domains: Extensions to multiple targets, sequential/continual adaptation, and interaction between adaptation order and performance are not analyzed.
- Hyperparameter selection: Methods introduce regularization parameters (e.g., FT constraint radii) with no data-driven selection strategies or sensitivity analysis; guidance on tuning under label scarcity is missing.
- Condition-number dependence: Excess risk bounds depend on condition numbers (e.g., κ, κσ); the practical implications under ill-conditioning and potential preconditioning strategies are not explored.
- Diagnostics for assumption validity: There are no procedures to test CA/SC/AW assumptions from source + unlabeled target data (or minimal labels), nor to quantify confidence in the chosen start.
- Guarantee coverage of MASFT: The paper does not specify how many starting points are needed for near-optimality across a family of shifts, nor how to design a set of starts with provable coverage (e.g., covering numbers over plausible shift models).
- Absence of real-data validation: Empirical evidence is limited to simulations; validation on standard SSDA benchmarks and ablations (e.g., sensitivity to r/M/label budget) are needed to substantiate practical impact.
- Privacy/federation constraints: The framework assumes access to raw source and target data; how to adapt the methods to settings with only pretrained source models (or federated restrictions) remains unaddressed.
- Uncertainty quantification: Post-adaptation uncertainty (e.g., prediction intervals, calibration) and its dependence on the small labeled target set are not discussed.
- Heterogeneous source weighting: How to weight heterogeneous sources with varying relevance/size, and the impact of misweighting on FT performance and CIP invariance, is not analyzed.
- Causal direction uncertainty: The approach assumes anticausal direction (Y → X); procedures to infer or hedge against incorrect causal direction (and its effect on adaptation strategies) are not proposed.
Glossary
- Adversarial-based domain classifier: A discriminator trained adversarially to measure or reduce distribution differences between domains. "adversarial-based domain classifier"
- Anticausal linear SCMs: A subclass of structural causal models where labels cause covariates and relationships are linear. "Anticausal linear SCMs"
- Anticausal weights: The vector of coefficients linking labels to covariates in an anticausal SCM. "anticausal weights"
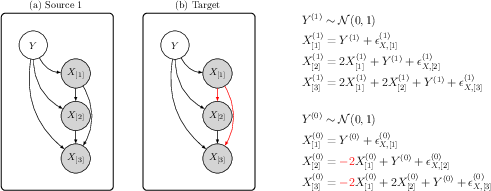
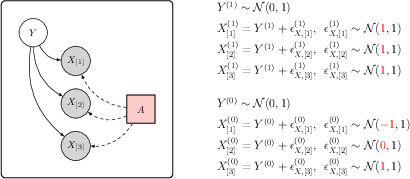
- Causal diagrams: Graphical representations of cause-effect relationships in the variables of a structural causal model. "The causal diagrams and structural equations illustrating Example 3."
- Conditional invariant penalty (CIP): A training constraint that enforces alignment of conditional feature distributions across domains given labels. "conditional invariant penalty (CIP)"
- Condition number: A quantity (often the ratio of maximum to minimum eigenvalues) indicating numerical stability or sensitivity of a matrix or problem. "condition number"
- Confounded additive (CA) shift interventions: Distribution shifts caused by hidden confounders that add low-dimensional perturbations to both covariates and labels. "confounded additive (CA) shift interventions"
- Connectivity matrices: Matrices encoding causal relations among covariates in an SCM. "connectivity matrices encoding the causal relations among the covariates"
- Distributionally robust optimization framework: An optimization approach that seeks solutions performing well under worst-case distributional variations. "distributionally robust optimization framework"
- Domain adaptation (DA): Methods that transfer knowledge from a source domain to a different but related target domain. "domain adaptation (DA) methods"
- Domain generalization (DG): Training strategies that aim to perform well under distribution shifts without access to target data. "domain generalization (DG)"
- Domain invariant projection (DIP): An approach to learn feature representations shared across domains by matching distributions while optimizing source performance. "domain invariant projection (DIP)"
- Domain invariant representation learning: Learning representations that are invariant across domains to improve transferability. "also known as domain invariant representation learning"
- Empirical Bayes methods: Bayesian techniques that estimate priors from data to improve inference or prediction. "Empirical Bayes methods"
- Empirical risk minimization (ERM): The principle of minimizing average loss over training data to learn a model. "empirical risk minimization (ERM)"
- Excess risk: The gap between a model’s risk and the optimal risk achievable within a function class. "excess risk, defined as"
- Gaussian width: A geometric complexity measure used to quantify the size of a set, relevant to sample complexity bounds. "measured by Gaussian width"
- Hold-out target validation dataset: A small labeled target subset used to select or validate models during adaptation. "a small hold-out target validation dataset"
- Maximum mean discrepancy (MMD): A kernel-based statistical distance between distributions used for alignment. "maximum mean discrepancy (MMD)"
- Minimax excess risk: The worst-case expected excess risk over a class of distributions, minimized over estimators. "The classical minimax excess risk is defined as"
- Multi Adaptive-Start Fine-Tuning (MASFT) algorithm: A method that fine-tunes multiple UDA-initialized models and selects the best using limited target validation labels. "Multi Adaptive-Start Fine-Tuning (MASFT) algorithm"
- Oracle estimator: The ideal estimator achieving minimal population risk on the target distribution. "Oracle estimator: the population OLS estimator, or oracle estimator"
- Ordinary least squares (OLS): A linear regression technique minimizing squared errors, used as a baseline estimator. "Ordinary least squares (OLS) on individual source datasets is the most basic estimator in UDA"
- Population target risk: The expected loss of a predictor on the target domain’s true distribution. "population target risk"
- Projection operator: A linear operator that maps vectors onto a specified subspace. "projection operator onto col{V}"
- Structural causal models (SCMs): Formal models specifying causal mechanisms that generate observed data. "structural causal models (SCMs)"
- Structural equation: An equation defining relationships among variables in an SCM. "specified by the structural equation"
- Sub-Gaussian: A class of random variables with tails no heavier than Gaussian, implying strong concentration properties. "sub-Gaussian"
- Transductive transfer learning: A transfer learning paradigm leveraging target domain data (often unlabeled) during training. "also known as transductive transfer learning"
- Unsupervised domain adaptation (UDA): A DA setting with labeled source and only unlabeled target data. "unsupervised domain adaptation (UDA)"
Practical Applications
Immediate Applications
The items below highlight concrete ways to deploy the paper’s findings and methods now, across sectors, with small labeled target sets, leveraging abundant source and unlabeled target data. Each entry notes practical workflows, potential tools/products, and critical assumptions or dependencies.
- Semi-automated model porting across hospitals and scanners (healthcare imaging)
- Use case: Adapt radiology or pathology classifiers to a new site/scanner/protocol with 5–100 labeled target images, leveraging existing labeled source datasets and unlabeled target scans.
- Workflow: Train UDA base models (
DIP,CIP, OLS-Src) on source + unlabeled target; fine-tune viaFT-DIP(for confounded mean/covariance shift),FT-OLS-Src(for sparse connectivity shifts), orFT-CIP(for anticausal weight shifts) on a few labeled target images; select viaMASFTusing a tiny target validation set. - Tools/products: A “few-label domain porting kit” for PyTorch/TensorFlow; subspace-estimation utilities; MASFT selection module; shift diagnostics that suggest a starting estimator and constraint.
- Assumptions/dependencies: Label space unchanged; low-dimensional shift structure; adequate unlabeled target data for stable moment estimates; data-sharing compliant with privacy regulations; small validation set representative of target.
- Factory-to-factory vision classifier transfer (manufacturing/quality control)
- Use case: Adapt surface defect detection models when cameras, lighting, or background change between production lines with minimal relabeling.
- Workflow: Estimate covariance differences for
FT-DIPunder confounded additive shifts (lighting/background); fine-tune in the identified low-dimensional subspace; compare multiple adaptive starts withMASFT. - Tools/products: On-prem MASFT service for rapid line startup; MMD/adversarial divergence plugins; monitoring to detect negative transfer.
- Assumptions/dependencies: Unlabeled target frames available; variance/conditional invariance penalties align with shift type; class prior reasonably stable.
- Accent and environment adaptation for speech recognition (software/AI)
- Use case: Adapt ASR models to new accents or microphone profiles with a small set of labeled utterances.
- Workflow: Use
DIP-style representation alignment across source accents and unlabeled target audio;FT-DIPto adjust for confounded additive shifts; MASFT chooses best start. - Tools/products: Audio-specific divergence estimation; adapter layers implementing low-rank constrained fine-tuning consistent with the paper’s subspace constraints (e.g., LoRA-like adapters).
- Assumptions/dependencies: Same phoneme/word inventory; abundant unlabeled target audio; shift approximately low-dimensional.
- Cross-font and handwriting OCR deployment (software/education)
- Use case: Re-deploy OCR models to new fonts, scanners, or handwriting styles with few labeled pages from the new domain.
- Workflow:
FT-DIPfor mean/covariance changes (scanning artifacts);FT-OLS-Srcwhen a subset of features (e.g., strokes) changes connectivity; MASFT for model selection under uncertainty. - Tools/products: OCR domain-adaptation SDK; covariate shift analyzer; validation subset sampling tools.
- Assumptions/dependencies: Same label set (characters); unlabeled pages plentiful; low-dimensional perturbations.
- Fraud detection model transfer across regions (finance)
- Use case: Adapt fraud or risk models to a new geography or merchant cohort using few labeled target transactions.
- Workflow: Multi-source
CIPto learn conditionally invariant components;FT-CIPwhen anticausal weights shift; MASFT to select among starts; incorporate unlabeled target transactions. - Tools/products: Financial DA toolkit with conditional invariance penalties; governance-friendly audit trails of model selection; sample-size calculators using minimax rates.
- Assumptions/dependencies: Labeling cost constraints; cross-region differences not purely label-shift; multiple heterogeneous source environments for
CIP.
- Satellite imagery model rollout to new sensors/regions (energy/agriculture/earth observation)
- Use case: Adapt land cover or crop type classifiers to a new satellite sensor or region with limited labeled polygons.
- Workflow: Use
FT-DIPwhere sensor-induced shifts are confounded additive (spectral/atmospheric changes); MASFT performs robust selection with tiny validation labels. - Tools/products: Remote-sensing DA pipeline; subspace constraints estimated from unlabeled target imagery; MMD/covariance alignment plugins.
- Assumptions/dependencies: Sufficient unlabeled tiles; stable semantic classes; low-dimensional confounding (e.g., sensor response changes).
- Personalized NLP for customer support (software)
- Use case: Tailor intent classification or response selection to a new client vertical with small labeled conversations.
- Workflow: Domain-invariant representation via
DIP; constrained fine-tuning (FT-DIP) with subspace selection; MASFT to pick best adaptive start. - Tools/products: Adapter-based fine-tuning aligned with low-dimensional shift; automated validation-set construction.
- Assumptions/dependencies: Same intent taxonomy; unlabeled transcripts accessible; model respects privacy.
- Robot perception transfer across environments (robotics)
- Use case: Adapt object detection/segmentation to a new facility with different lighting/background from minimal labeled frames.
- Workflow:
FT-DIPfor scene-confounded shifts; MASFT to mitigate bad starts in ambiguous settings; degrade gracefully to target-only ERM if needed. - Tools/products: Robotics DA utilities; shift diagnostics and early stopping; performance monitoring on hold-out target frames.
- Assumptions/dependencies: On-device unlabeled data collection; stable object categories; limited compute for rapid fine-tuning.
- Short-horizon energy demand forecasting to new regions (energy)
- Use case: Transfer models to regions with different but related consumption patterns using few labeled target periods.
- Workflow: Estimate conditionally invariant components via
CIPacross multiple source regions;FT-CIPto adjust; MASFT chooses best. - Tools/products: Time-series DA library; conditional invariance estimators; governance-friendly risk analysis.
- Assumptions/dependencies: Access to multiple source regions; label space and task fixed; shift not dominated by label imbalance.
- Cross-campus deployment of grading or tutor models (education)
- Use case: Adapt automated grading/tutor feedback models to a new institution/course with few labeled assignments.
- Workflow:
DIPorCIPdepending on available multi-source data; constrained fine-tuning with small target labels; MASFT selection. - Tools/products: Education DA tools; lightweight adapters for LMS integration; transparent validation protocols.
- Assumptions/dependencies: Same rubric/skills; unlabeled data on new course; small but representative validation set.
- Operational guidance for data-efficient validation and labeling (policy/ML governance)
- Use case: Establish procedures for minimal target labeling and validation to safely deploy models across sites.
- Workflow: Use the paper’s minimax rates to set target label budgets; adopt MASFT-based selection; monitor excess risk versus target-only baselines; escalate labeling if subspace constraints fail.
- Tools/products: Policy templates for cross-site deployment; sample-size calculators; dashboards for model selection evidence.
- Assumptions/dependencies: Organizational capacity for collecting few labels; agreement on shift diagnostics and acceptance criteria.
Long-Term Applications
The following opportunities require further research, scaling, or development to generalize beyond linear SCMs, automate shift-type inference, or integrate into foundation-model ecosystems.
- Auto-adaptation services that infer shift type and subspace constraints (software/AI platforms)
- Vision: A service that detects whether the target shift is confounded additive, sparse connectivity, or anticausal weight, then automatically chooses among
FT-DIP,FT-OLS-Src,FT-CIPand configures MASFT. - Dependencies: Robust shift-type inference; causal structure estimation at scale; non-linear extensions; uncertainty quantification.
- Vision: A service that detects whether the target shift is confounded additive, sparse connectivity, or anticausal weight, then automatically chooses among
- Foundation model adapters guided by causal shift diagnostics (software/AI)
- Vision: Adapter/LoRA modules that enforce the paper’s low-dimensional fine-tuning constraints inside large vision/NLP models, informed by SCM-based shift tests.
- Dependencies: Theory for non-linear architectures; reliable divergence/conditional invariance estimators; scalable adapter training.
- Cross-site healthcare deployments with standardized few-label protocols (healthcare/policy)
- Vision: Regulatory-aligned guidance that formalizes minimal labeled target data requirements using minimax rates, endorses MASFT-style model selection, and mandates shift diagnostics.
- Dependencies: Clinical validation; harmonized data-sharing; fairness audits; domain-specific robustness guarantees.
- Privacy-preserving SSDA with federated unlabeled target data (privacy/ML systems)
- Vision: Federated or decentralized SSDA pipelines that estimate subspaces/divergences without centralizing target data; fine-tune on-site with small labels.
- Dependencies: Secure aggregation for covariance/conditional invariance; reliable local validation; privacy constraints.
- Active learning integrated with SSDA to optimize the few labels (software/operations)
- Vision: Joint selection of target examples that maximize MASFT’s model selection power and fine-tuning efficacy under subspace constraints.
- Dependencies: Acquisition functions tailored to DIP/CIP/OLS-Src starts; theoretical guarantees for combined SSDA–active learning; operational tooling.
- Robust robotics domain adaptation across tasks and sensors (robotics)
- Vision: End-to-end systems that continuously adapt perception and control models to new sensors/environments, with causal diagnostics determining adaptation strategy.
- Dependencies: Real-time subspace estimation; multimodal divergences; safety-certified adaptation protocols.
- Finance and energy risk transfer with conditional invariance analytics (finance/energy)
- Vision: Enterprise tools that quantify conditionally invariant components across many environments, guide
FT-CIP, and provide governance for cross-market deployments. - Dependencies: Large multi-source datasets; interpretable invariance explanations; resilient to label-shift and regime changes.
- Vision: Enterprise tools that quantify conditionally invariant components across many environments, guide
- Domain adaptation benchmarking and leaderboards for few-label SSDA (academia/industry)
- Vision: Public benchmarks that categorize shift types (CA/SC/AW), evaluate MASFT and fine-tuning strategies, and standardize few-label protocols.
- Dependencies: Curated datasets with known causal mechanisms; agreed-upon divergences; reproducible pipelines.
- Causal discovery integrated with SSDA for connectivity shifts (research/software)
- Vision: Methods that estimate sparse changes in feature connectivity (SC scenario), then constrain
FT-OLS-Srcaccordingly for non-linear/high-dimensional models. - Dependencies: Scalable causal discovery under weak supervision; robustness to hidden confounders.
- Vision: Methods that estimate sparse changes in feature connectivity (SC scenario), then constrain
- On-device MASFT for personal devices (consumer software)
- Vision: Local adaptation of ASR, keyboard, camera models using small labeled interactions, with MASFT selecting best start under resource constraints.
- Dependencies: Efficient on-device moment estimation; privacy-preserving validation; energy-efficient fine-tuning.
- Governance dashboards for excess risk and negative transfer monitoring (policy/ML ops)
- Vision: Continuous monitoring of target excess risk against target-only baselines; alerts when MASFT selections underperform or violate constraints.
- Dependencies: Reliable excess risk estimation with small validation sets; standardized alert criteria; integration into MLOps.
- Educational tooling to teach SSDA and causal shift handling (academia/education)
- Vision: Courses and interactive modules illustrating SCM-based SSDA, minimax rates, and MASFT selection, with hands-on sector-specific labs.
- Dependencies: Pedagogical datasets; accessible libraries; visualization of subspace constraints.
Cross-cutting assumptions and dependencies
Across applications, feasibility depends on:
- Low-dimensional shift structure: The gains rely on shifts (confounded additive, sparse connectivity, anticausal weight) being low-dimensional relative to model capacity.
- Availability of unlabeled target data: Essential for estimating divergences/covariances/subspaces used by
DIP,CIP, and MASFT. - Consistent task/label space: Source and target must share the same labels; large label shift may require additional correction.
- Representative small target validation set: MASFT’s selection guarantees assume the validation subset reflects the target distribution.
- Multi-source diversity for
CIP: Conditional invariance estimation benefits from heterogeneous source environments. - Model class and architecture: The theory centers on linear SCMs; practical non-linear models should implement constrained fine-tuning (e.g., adapter/LoRA subspaces) and validate empirically.
- Operational constraints: Privacy/compliance for data sharing, compute budgets for repeated adaptive starts, and robust monitoring to prevent negative transfer.
Collections
Sign up for free to add this paper to one or more collections.