- The paper introduces LibLMFuzz, which leverages LLMs to autonomously generate fuzz targets for closed-source libraries, achieving 75.52% nominal correctness on first execution.
- The methodology employs a staged prompting strategy and a sandboxed middleware to iteratively refine fuzz driver synthesis using compiler feedback and runtime diagnostics.
- Experimental results demonstrated complete API coverage across 558 functions, underscoring the framework's potential to streamline binary library security testing.
LLM-Augmented Fuzz Target Generation for Black-box Libraries
LibLMFuzz, as documented in "LibLMFuzz: LLM-Augmented Fuzz Target Generation for Black-box Libraries" (2507.15058), presents a novel framework utilizing LLMs to automate the generation of fuzz targets for closed-source library binaries. This work builds upon existing fuzzing techniques while addressing the specific challenges posed by proprietary, binary-only components typically inaccessible to traditional fuzzing methodologies reliant on source code.
Introduction to Fuzzing and LibLMFuzz
Fuzzing serves as a robust technique for discovering security vulnerabilities by executing code paths that lead to software failure through random inputs. While effective, fuzzing frameworks often require significant initial and ongoing configuration, particularly when dealing with closed-source libraries. LibLMFuzz innovates by harnessing LLM's capabilities to autonomously analyze binary libraries, synthesizing drivers, and iteratively correcting errors without human intervention. The system promises reduced costs and barrier-to-entry, making it feasible for broader adoption among security researchers facing restrictions due to proprietary code.
LibLMFuzz was tested on four widely-used Linux libraries, achieving remarkable API coverage with syntactically correct drivers for all 558 fuzz-able functions. The framework's autonomous generation of 75.52% nominally correct fuzz drivers upon first execution stands as a testament to the potential efficiency gains from LLM integration in security testing workflows. This substantial success underscores the possibility of expanding fuzz target generation across diverse platforms and components.
Mechanisms of LibLMFuzz
Middleware Infrastructure
LibLMFuzz's operational backbone is a middleware suite interfacing between the user, the LLM, and the auxiliary tools. The infrastructure is staged in a sandbox to safely execute disassembly, compilation, and fuzzing, ensuring robust execution while limiting risk. The middleware manages a phased prompting strategy that guides the LLM through initial analysis and target generation, while a sandboxed Linux environment hosts the necessary development tools (Figure 1).
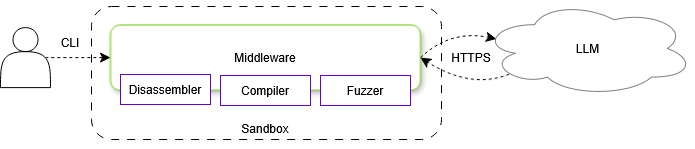
Figure 1: Middleware Infrastructure Architecture.
Workflow Implementation
The LibLMFuzz workflow orchestrates the generation of fuzz targets by dividing tasks across multiple execution phases. Initially, the middleware identifies fuzz-able functions within binary libraries, filtering non-relevant API exports. The LLM is prompted to analyze each function iteratively, with direct access to disassembly data, hence facilitating refined target generation (Figure 2).
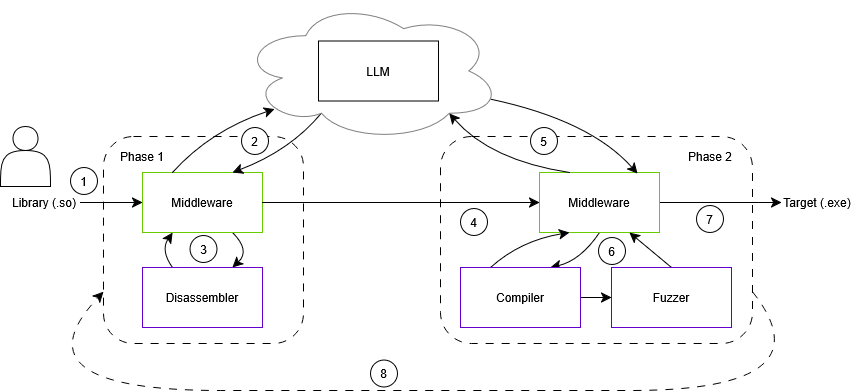
Figure 2: Workflow of Library Fuzz Target Generation.
When synthesizing fuzz drivers, the model undergoes multiple feedback loops for error correction and validation, leveraging compiler output and runtime diagnostics to refine its outputs. This systematic prompting and feedback-based refinement significantly increase the likelihood of generating functional and semantically correct fuzz targets.
Evaluation and Findings
LibLMFuzz underwent empirical testing across several popular open-source libraries compiled into binary form. The framework demonstrated a flawless rate of API coverage with 558 fuzz-able functions yielding over 1601 synthesized fuzz targets, 75.52% of which were nominally correct upon first execution. While LibLMFuzz robustly addressed API coverage, it reveals shortcomings in fully understanding program semantics, an area ripe for future research endeavors.
Implications and Future Directions
The successful demonstration of LibLMFuzz suggests promising directions for research and application enhancement—including improving LLM contextual awareness and middleware integration to augment fuzz driver quality. Two viable paths include Human-in-the-Loop (HITL) methodologies to enhance the context provided to LLMs, and expanded tooling strategies granting LLMs greater operational agency. These strategies could significantly improve the fidelity of fuzz targets concerning branch coverage and semantic appropriateness.
Additionally, comprehensive prompt engineering and ablation studies could dissect the mechanisms behind successful fuzz target generate and fine-tune LLM interaction for maximal efficiency.
Conclusion
LibLMFuzz marks a significant advance in automated fuzz target generation for closed-source binaries, demonstrating efficacy in achieving comprehensive API coverage. While the framework shows potential in reducing the complexity of fuzzing proprietary libraries, future research will ideally address context extraction and semantic understanding challenges. These improvements could cement LLMs as an invaluable asset in modern cybersecurity arsenals.