- The paper's main contribution is DARA, a fine-tuning strategy that redistributes attention to improve visual context integration in multimodal language models.
- It reveals that current MLLMs rely excessively on textual patterns, often overlooking vital visual cues, which limits true multimodal learning.
- The TrueMICL dataset offers a rigorous evaluation framework, demonstrating significant performance gains on tasks like Operator Induction and Clock Math.
True Multimodal In-Context Learning Needs Attention to the Visual Context
The paper "True Multimodal In-Context Learning Needs Attention to the Visual Context" (2507.15807) investigates the limitations of current Multimodal LLMs (MLLMs) in effectively utilizing visual information during Multimodal In-Context Learning (MICL). Despite advancements in standard vision-language datasets, MLLMs primarily rely on textual patterns, often neglecting visual cues which hampers true multimodal adaptation.
Limitations of Current MLLMs
Research has illustrated that MLLMs struggle to integrate visual information, leading to unimodal responses that mimic text patterns. This is often misinterpreted as improved task performance because existing benchmarks don't adequately differentiate between unimodal text imitation and true multimodal learning. For example, image captioning can yield comparable results even when context images are omitted [chen2023understanding].
Dynamic Attention ReAllocation (DARA)
To address these issues, the paper introduces Dynamic Attention ReAllocation (DARA), a fine-tuning strategy that redistributes attention across visual and textual tokens in MLLMs. DARA employs learnable parameters to enhance the model’s focus on visual tokens within attention scores, promoting genuine multimodal adaptation without significant parameter overhead. The effectiveness of DARA is exemplified in quantitative improvements on various MICL tasks.
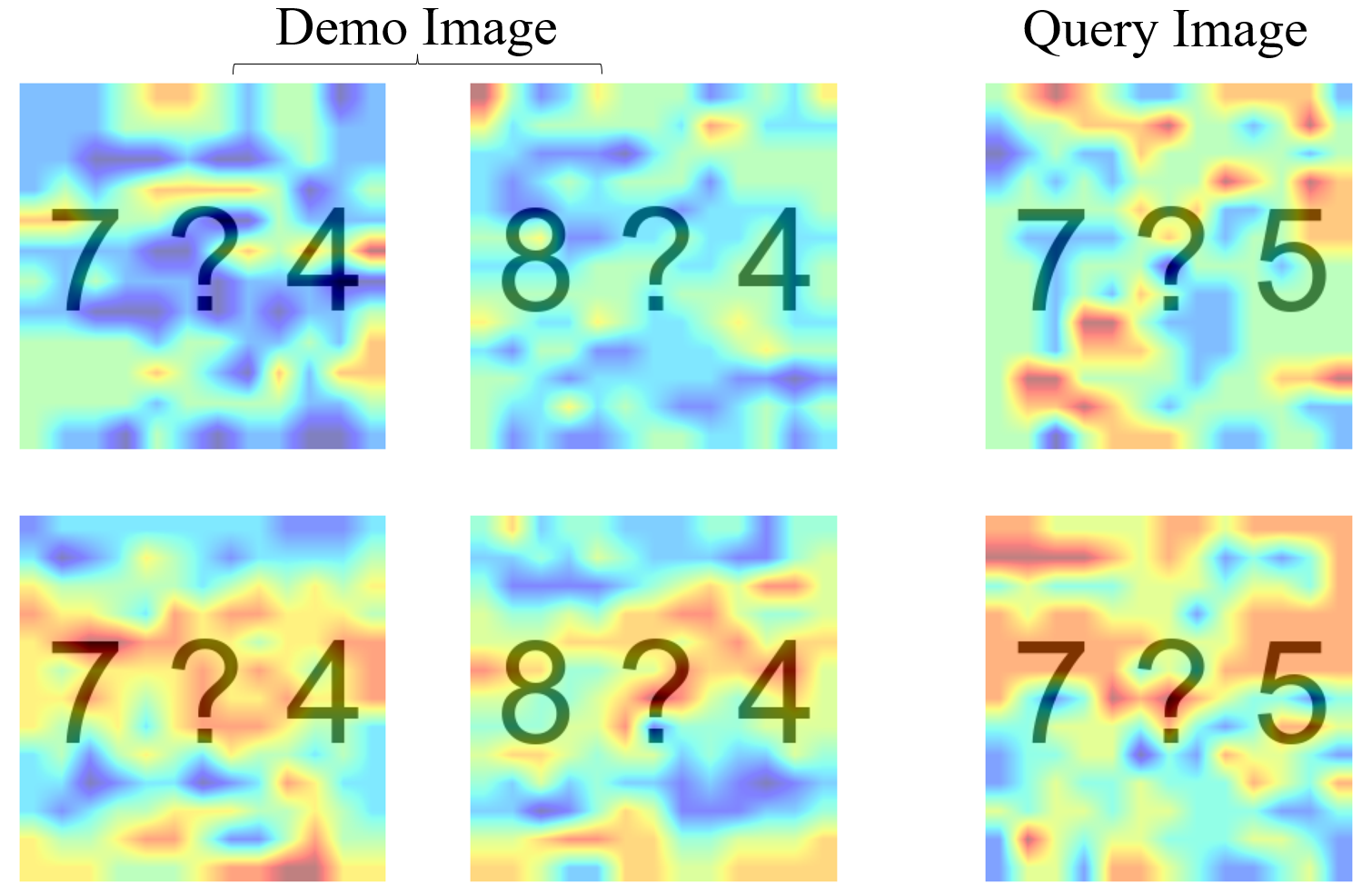
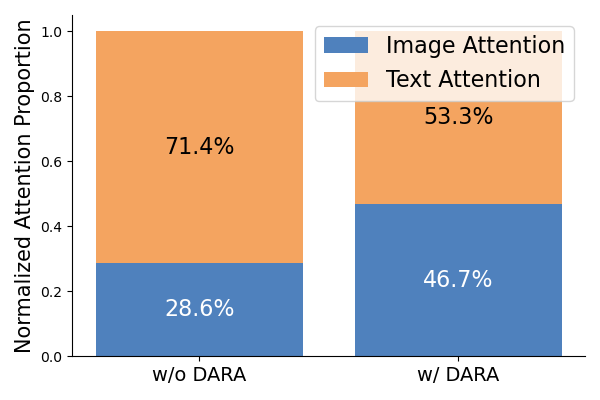
Figure 1: Attention heatmaps over input images without (top) and with (bottom) applying DARA.
TrueMICL Dataset
To reliably evaluate MICL capabilities, the paper presents TrueMICL, a dataset specifically designed to necessitate the integration of visual context for task completion. Unlike traditional benchmarks, TrueMICL emphasizes visual context dependency, novel image-text mapping, and comprehensive task learning. Through tasks like Operator Induction and Clock Math, TrueMICL challenges models to derive answers from visual information, ensuring that the capability to learn from multimodal context is measured.
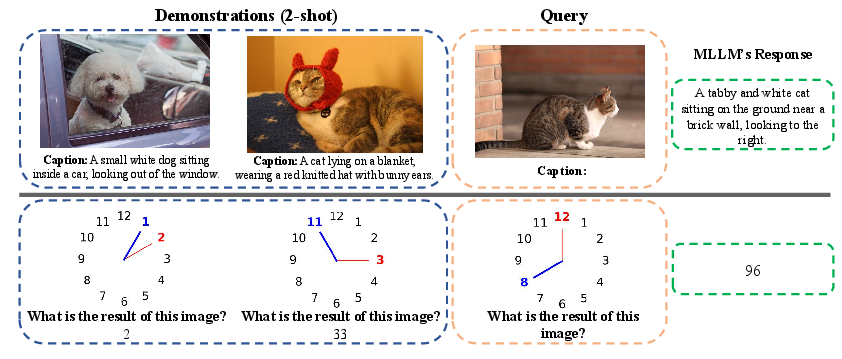
Figure 2: Examples of using MICL to solve image captioning from MSCOCO and Clock Math from TrueMICL.
Experimental Insights
The paper's empirical results highlight the effectiveness of DARA and TrueMICL in fostering multimodal learning. Models fine-tuned with DARA show substantial improvements on TrueMICL benchmarks compared to baseline methods like Random or LoRA, which require significantly more parameters to reach similar performance levels. DARA’s lightweight nature and parameter efficiency provide a viable route for enhancing MICL without extensive computational resources.
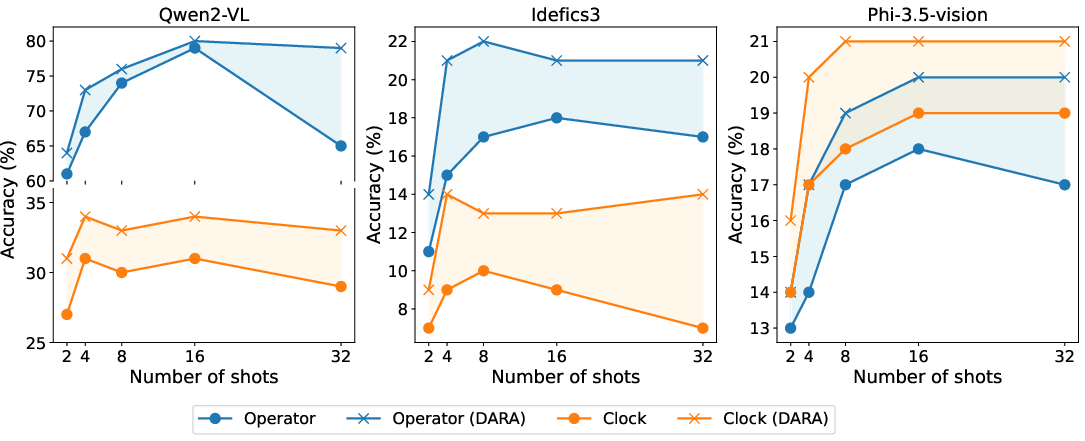
Figure 3: Performance comparison on Operator and Clock tasks across three models with different numbers of shots, showing consistent improvements with DARA.
Implications and Future Directions
This research offers critical insights into advancing MICL capabilities. By leveraging DARA and TrueMICL, models can improve in visual context understanding, paving the way for more efficient multimodal learning systems. Future work may focus on refining these approaches, extending the dataset to cover broader tasks, and exploring synergistic integrations with other parameter-efficient fine-tuning methods.
Conclusion
The paper introduces pivotal strategies for addressing the unimodal limitations in current MLLMs, promoting true multimodal in-context learning. DARA's efficient attention reallocation and TrueMICL’s rigorous benchmarks collectively propose a framework for evaluating and enhancing MICL, presenting practical advancements in the development of multimodal AI systems.
