- The paper introduces a systematic pipeline leveraging prompt engineering and semantic obfuscation to craft adversarial vishing transcripts that evade ML-based classifiers.
- It assesses four commercial LLMs using a balanced Korean vishing dataset, employing metrics like BERTScore, ROC curves, and statistical tests to gauge performance drop.
- The study underscores the urgent need for robust detection systems and tighter safeguards to counteract the scalable, economically feasible threat of LLM-driven vishing attacks.
LLM-Based Attacks on Voice Phishing Classifiers
This study investigates the potential of leveraging LLMs to generate adversarial vishing transcripts that can evade ML-based detection systems while maintaining deceptive intent. The research introduces a systematic attack pipeline that utilizes prompt engineering and semantic obfuscation to transform real-world vishing scripts using commercial LLMs. The effectiveness of these LLM-generated transcripts is evaluated against multiple ML classifiers trained on a real-world Korean vishing dataset (KorCCViD).
Threat Model and Methodology
The study defines a threat model (Figure 1) where a malicious actor (visher) uses LLMs to refine vishing scripts into adversarial transcripts, designed to bypass detection mechanisms. The attacker's goal is to construct convincing voice phishing scripts that evade ML-based detectors.
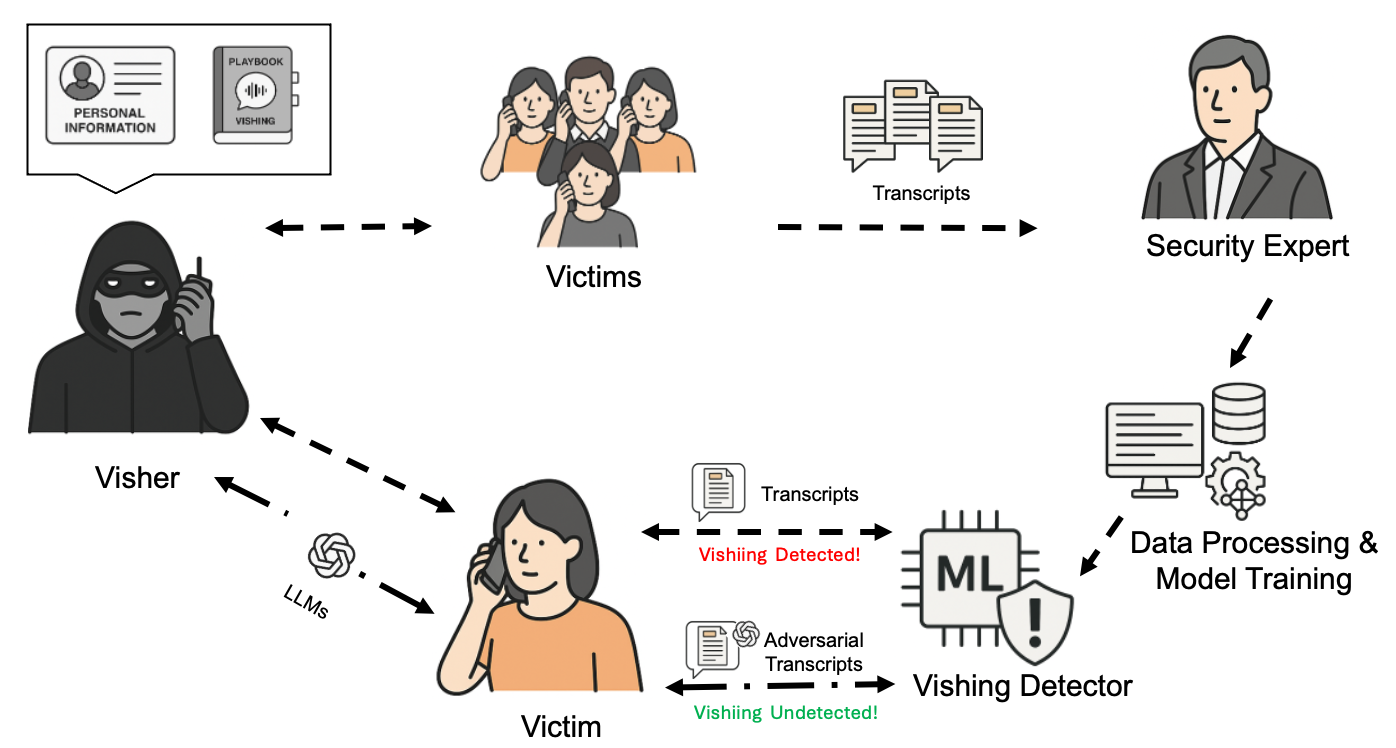
Figure 1: Threat Model Overview: LLM-Generated Adversarial Vishing Transcripts Against ML-Based Classifiers.
The methodology consists of five phases: adversarial prompt construction, LLM generation, data processing, classifier evaluation, and semantic preservation measurement. The adversarial prompt construction phase involves rephrasing and noise injection to obfuscate the original scammer speech. The LLM generation phase uses the crafted prompt and original transcript to generate adversarial transcripts. Data processing involves cleaning and tokenizing the generated transcripts. Classifier evaluation assesses the performance of ML classifiers against the adversarial transcripts. Semantic preservation is quantified using BERTScore metrics.
Experimental Setup
The experiments use a balanced subset of the KorCCViD v1.3 dataset, with 609 vishing and 609 non-vishing transcripts. The study employs four commercial LLMs: GPT-4o, GPT-4o mini, Gemini 2.0, and Qwen2.5. ML classifiers, including linear and ensemble-based models, are trained on the dataset. Performance is evaluated using classifier performance metrics, statistical testing metrics, and semantic similarity metrics.
Results and Analysis
The results indicate that LLM-generated transcripts are effective against ML-based classifiers. Qwen2.5 exhibits the highest average accuracy drop (33.83%), while GPT-4o achieves a 16.16% drop. Statistical tests confirm that the adversarial attacks lead to a statistically significant reduction in classifier performance (Figure 2). While Qwen2.5 demonstrates the strongest evasion performance, its semantic fidelity is relatively poor. GPT-4o achieves a strong balance between adversarial effectiveness and semantic preservation.
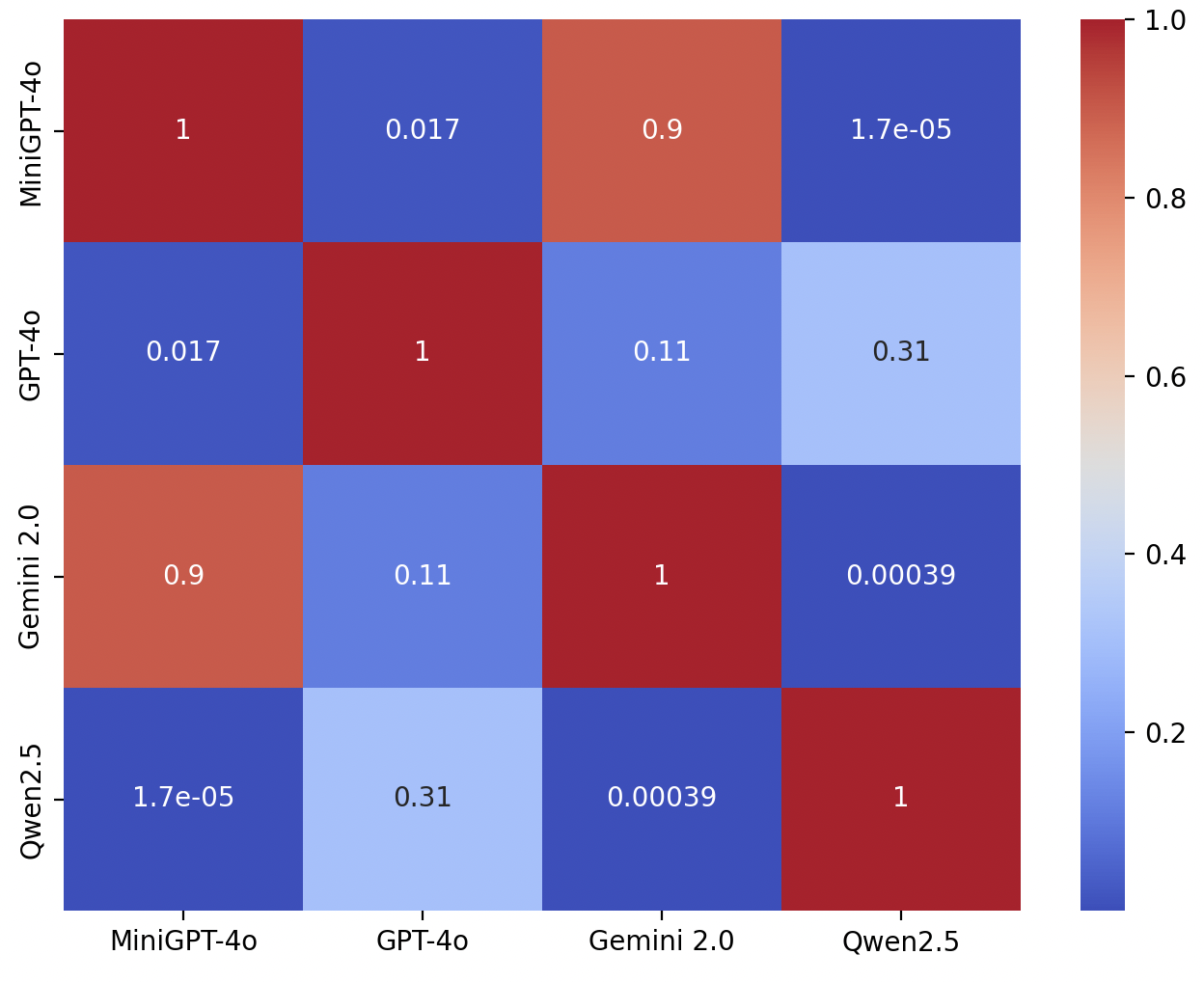
Figure 2: Nemenyi post-hoc test results comparing adversarial effectiveness of four LLMs based on classifier accuracy rankings. Each cell displays the p-value of the pairwise comparison between two LLMs. Statistically significant differences (p<0.05) are observed between Qwen2.5 and all other models, as well as between GPT-4o and MiniGPT-4o. Darker blue regions indicate stronger statistical significance.
Evaluation on the full vishing dataset using GPT-4o shows that the average classification accuracy across all models drops significantly. ROC curves also indicate a decline in AUC values after applying GPT-4o-based obfuscation (Figure 3). An analysis of original vs. adversarial transcripts validates that the adversarial text generated by GPT-4o preserves the meaning while deceiving the ML classifiers. The average cost to generate a single adversarial transcript using GPT-4o is approximately \$0.00685, with an average generation time of 8.595 seconds.
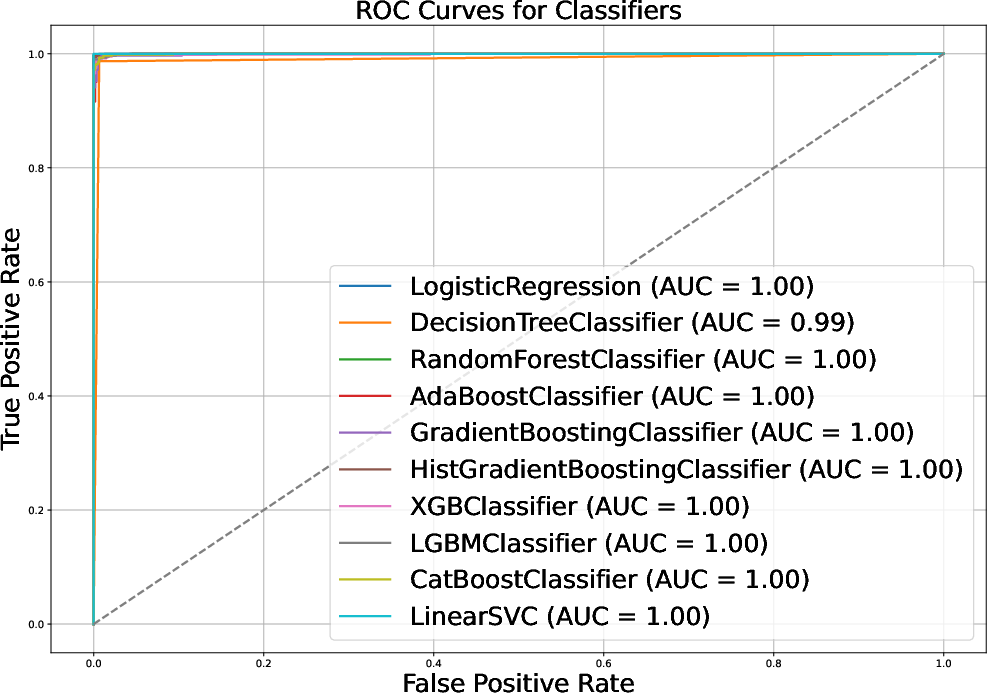
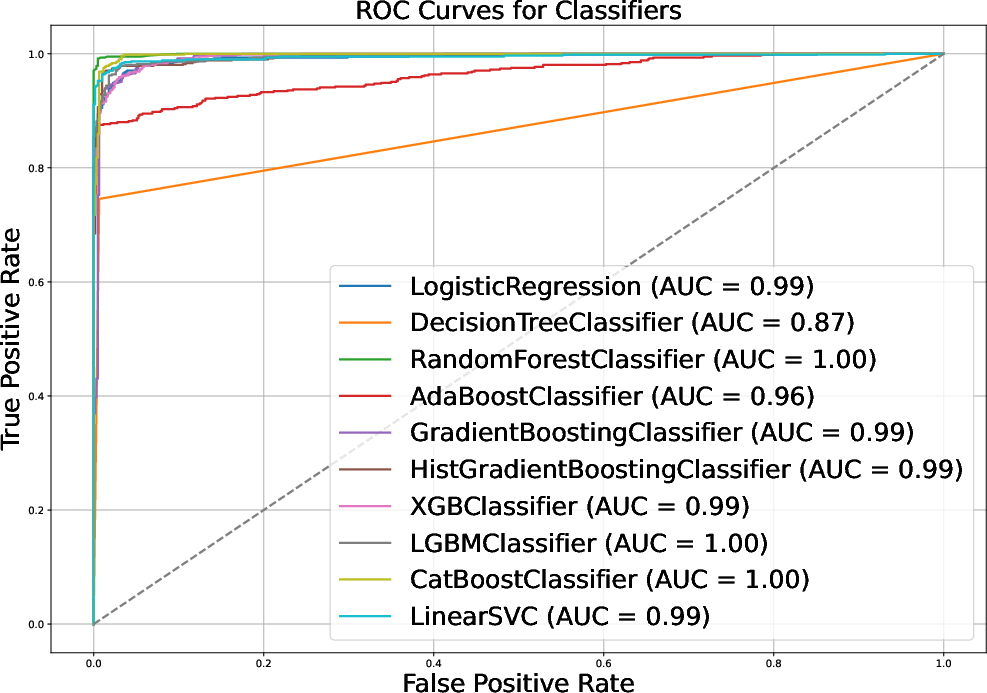
Figure 3: ROC curves for original and adversarial vishing transcripts.
Implications and Conclusion
The study underscores the threat of LLMs in generating evasive vishing transcripts. The findings highlight the need for more robust vishing detection systems and the implementation of safeguards by commercial LLM providers to prevent prompt misuse for malicious purposes. The economic feasibility and scalability of LLM-based attacks make this threat vector particularly concerning. Future research should focus on developing defenses against these attacks and exploring the ethical implications of using LLMs in adversarial social engineering contexts.