- The paper introduces a confidence-aware mechanism that optimizes probabilistic encoding for improved classification accuracy.
- It replaces KL divergence with L2 regularization to better control variance and align feature distributions with real-world data uncertainty.
- Empirical results on NLP benchmarks using BERT and RoBERTa demonstrate enhanced generalization and robustness over traditional methods.
Confidence Optimization for Probabilistic Encoding
Introduction
The paper "Confidence Optimization for Probabilistic Encoding" (2507.16881) introduces an innovative approach to enhancing probabilistic encoding methods used in neural networks. Probabilistic encoding has demonstrated considerable potential in capturing data uncertainty by generating representations as distributions rather than deterministic point data. While useful for generalization, it introduces randomness that can distort point-based distance measurements critical for classification tasks. The proposed method, Confidence Optimization for Probabilistic Encoding (CPE), seeks to overcome these limitations by optimizing confidence levels within probabilistic models, thereby improving representation learning and classification performance.
Probabilistic Encoding Framework
Probabilistic encoding, as detailed in the paper, represents data points as Gaussian distributions in the latent space, allowing for a richer representation by incorporating uncertainty. This contrasts with deterministic methods that map every input to a fixed point, ignoring the variability inherent in real-world data. The paper exemplifies this using an offense evaluation task, illustrating how deterministic encoding maps data to distinct points, whereas probabilistic encoding distributes data into Gaussian-feature spaces.
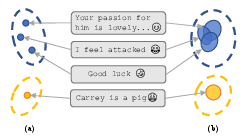
Figure 1: Taking the offense eval task as an example, deterministic encoding maps data to a single point like (a); probabilistic encoding maps data to a distribution. The same category will share the same feature space.
Applications in computer vision, notably Variational Autoencoders (VAEs), leverage probabilistic encoding to enhance generative models. By incorporating Gaussian noise into the learning process, VAEs enable the modeling of latent spaces as distributions, facilitating the generation of diverse and unseen data samples. Despite the advantages, challenges remain, particularly in ensuring accurate classification performance, as traditional methods use single sampled points for measurement, risking unreliable distance assessments.
Methodology
The core contribution of this paper is a confidence-aware mechanism designed to refine distance calculations within probabilistic frameworks. The proposed model introduces a novel confidence metric, transitioning from reliance on KL divergence-based regularization—which often assumes inaccurate priors—towards an L2 regularization approach.
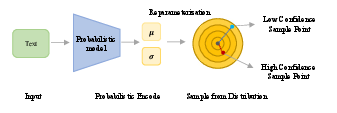
Figure 2: Encoding process of probabilistic models. Text input data is encoded as mean μi and variance σi embeddings. The sampling process from the reparameterized distribution is stochastic, and the distance to the center point can be large or small.
The CPE mechanism comprises:
- Confidence Metric Integration: Confidence levels are calculated using a refined Gaussian Error Function, optimizing feature distribution reliability. This approach ensures that the model not only captures inherent data uncertainty but maintains robust classification effectiveness.
- Regularization Strategy: The replacement of KL divergence with L2 regularization provides more flexible variance control, aligning with the actual feature distribution and avoiding assumptions about standard normal priors.
- Downstream Task Performance: Extensive experiments demonstrate CPE’s effectiveness across various natural language classification tasks, significantly improving BERT and RoBERTa models. The method's model-agnostic nature allows seamless integration with existing frameworks.
Experimental Results
The empirical evaluation conducted across seven NLP classification benchmarks highlights CPE's superior performance. Utilizing both BERT and RoBERTa backbones, the method presented consistently better generalization and classification accuracy compared to traditional probabilistic and deterministic approaches.
Table \ref{tab:nlp result} presents the performance comparison across standard benchmark datasets, emphasizing CPE's robust contributions in enhancing classification metrics while maintaining computational efficiency. This underscores the approach's viability for real-world applications requiring reliable uncertainty estimation.
Furthermore, ablation studies reinforce CPE’s critical design choices, investigating L2 versus KL divergence regularization effects. Results affirm the benefits of confidence integration within probabilistic models, showcasing performance improvements and enhanced stability across diverse tasks.
Conclusion
The paper offers a systematic enhancement for probabilistic encoding, addressing key challenges in distance reliability and variance constraints. By optimizing stochastic process features with confidence metrics and improved regularization, CPE significantly enhances representation fidelity, laying groundwork for further research in model-aware optimization strategies. The proposed method not only advances probabilistic encoding frameworks but broadens applicability across different architectures, paving the way for future developments in AI-driven uncertainty modeling.