- The paper introduces a modular PyG 2.0 framework emphasizing scalability through a tensor-centric API and optimized C++/CUDA kernels.
- The neural framework enhances GNN efficiency with the EdgeIndex tensor for sparse operations, kernel fusion, and robust heterogeneous support.
- The framework integrates advanced explainability tools, temporal subgraph sampling, and LLM support to address diverse real-world applications.
PyG 2.0: Advancing Scalable Graph Learning
The paper "PyG 2.0: Scalable Learning on Real World Graphs" (2507.16991) introduces significant advancements in the PyG framework, focusing on scalability, heterogeneity, and explainability for graph neural networks. The update addresses the evolving demands of graph learning, facilitating efficient handling of large-scale, complex graphs in diverse real-world applications.
Core Architectural Enhancements
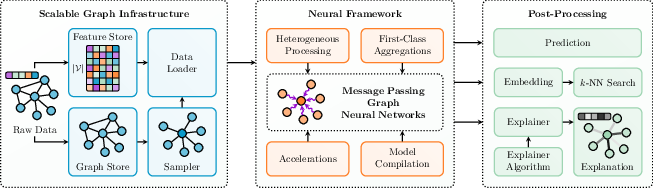
Figure 1: Architectural overview of PyG~2 highlighting the modular and plug-and-play design.
PyG 2.0 presents a modular architecture comprising three main components: graph infrastructure, a neural framework, and post-processing routines. This design allows for independent swapping of components, such as transitioning from in-memory storage to databases or modifying sampling strategies, without disrupting other parts of the system. The framework leverages a tensor-centric API, ensuring seamless integration with the PyTorch ecosystem and supporting advanced features like nested tensors and JIT compilation. Vectorized operations are used throughout the pipeline, with specialized C++ and CUDA kernels in the pyg-lib package for performance-critical tasks like graph sampling.
Neural Framework Innovations
The neural framework in PyG 2.0 focuses on enhancing the efficiency and flexibility of message passing graph neural networks. It introduces the EdgeIndex tensor, which facilitates optimized message passing via sparse matrix multiplications and segmented aggregations. This approach reduces memory requirements and enhances parallelism on GPUs. Aggregations are treated as first-class principles, allowing users to easily incorporate various aggregation functions, from simple statistical measures to learnable and unconventional methods. Heterogeneous graph support is enhanced through custom torch.fx transformations, enabling bipartite message passing over different edge types and efficient handling of varying node type distributions. Furthermore, the framework supports kernel fusion via torch.compile, providing 2-3x speedup in runtime by minimizing memory access and kernel launch overheads. The integration of state-of-the-art Graph Transformer architectures broadens the applicability of PyG for both small and large graph datasets.
Scalable Graph Infrastructure
To address the challenges of large-scale graphs, PyG 2.0 introduces new FeatureStore and GraphStore remote backend interfaces. These interfaces enable seamless interoperability with custom storage solutions, allowing mini-batch GNN training directly on external storage platforms. The data loading loop is segmented into feature store, graph store, and graph sampler components, providing a clear separation of concerns. Efficient subgraph sampling techniques, including multi-threaded C++ implementations, are employed to reduce memory and computational costs. Temporal subgraph sampling is also supported, enabling the extraction of time-respecting subgraphs for dynamic graph analysis. Integration with cuGraph further accelerates PyG workflows, leveraging GPUs for graph analytics, sampling, and distributed tensor storage, achieving linear scaling with additional GPUs.
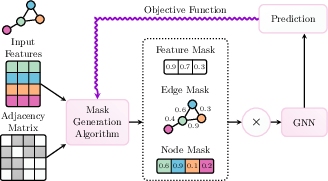
Figure 2: Illustration of a GNN explainer in PyG, showcasing the generation of node-level and edge-level masks to weigh node features and message passing edges.
Explainability is addressed through a universal Explainer interface, generating attributions that signify the importance of nodes, edges, and features in the model's decision-making process. The Explainer module temporarily alters the internal message passing process through a callback mechanism, allowing for perturbations, edge-level masks, or attention coefficients to be applied. The framework also provides a direct connection to Captum, a general-purpose explainability library for PyTorch, enabling the explanation of both feature information and structural properties via gradient-based explainer modules.
Applications in Relational Deep Learning
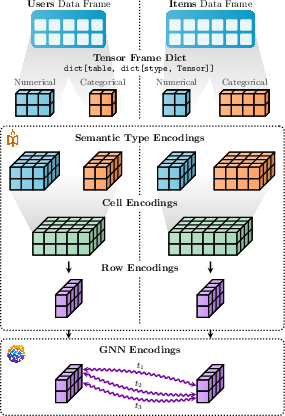
Figure 3: End-to-end Relational Deep Learning (RDL) showcasing multi-modal and multi-table data integration with PyTorch Frame and PyG.
PyG's support for heterogeneous temporal graphs facilitates Relational Deep Learning (RDL), offering an alternative to feature-based approaches for learning on relational databases. The RDL blueprint covers handling multi-modal data via integration with PyTorch Frame, querying historical subgraphs, and recommender system support. The framework enables subgraph samplers to iterate over externally specified seed nodes and timestamps, attaching ground-truth labels and metadata through transforms. Additionally, PyG 2.0 supports GNN-based recommender systems, including efficient Maximum Inner Product Search (MIPS) and mini-batch-compatible retrieval metrics.
Integration with LLMs
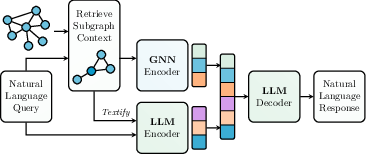
Figure 4: The GraphRAG pipeline in PyG, illustrating the retrieval of contextual subgraphs and their encoding via a GNN to enhance LLM encoder-decoder flows.
PyG contributes to the LLM domain by enabling the use of LLM embeddings in text-attributed graphs and supporting Retrieval Augmented Generation (RAG). GraphRAG, which uses GNNs and Graph Transformers to enhance LLMs' reasoning over relational information, is facilitated through extensions to PyG's FeatureStore and GraphStore abstractions. The G-Retriever model allows any combination of a PyG GNN with a HuggingFace LLM, demonstrating a 2x increase in accuracy over pure LLM baselines. Furthermore, the TXT2KG class provides an interface to convert unstructured text datasets into knowledge graphs via parsing and prompt engineering.
Conclusion
PyG 2.0 significantly advances graph learning by providing scalable solutions for real-world applications while maintaining ease of use and flexibility. Its modular design, enhanced neural framework, scalable infrastructure, and explainability tools make it a comprehensive platform for graph-based machine learning. The application of PyG in relational deep learning and RAG systems highlights its potential for further significant developments in the near future.