- The paper introduces a Moral Dilemma Dataset to benchmark the alignment between LLMs and diverse human moral judgments.
- The paper employs a distributional alignment framework revealing that LLMs align in high-consensus cases but diverge in ambiguous, low-consensus scenarios.
- The paper presents Dynamic Moral Profiling, which reduces misalignment by 64.3% and broadens the spectrum of values in LLM ethical reasoning.
The Pluralistic Moral Gap: Understanding Judgment and Value Differences between Humans and LLMs
The paper "The Pluralistic Moral Gap: Understanding Judgment and Value Differences between Humans and LLMs" (2507.17216) investigates the alignment of LLMs with human moral judgments within real-world moral dilemmas. By introducing the Moral Dilemma Dataset, a novel benchmark of dilemmas paired with human moral judgments, the study examines how closely LLMs align with the diversity and distribution of human values. It identifies a significant "pluralistic moral gap" and proposes the Dynamic Moral Profiling (DMP) method to bridge this gap, enhancing LLMs' ability to reflect pluralistic human moral reasoning.
Introduction
The increasing role of LLMs as ethical advisors brings critical attention to their alignment with human moral reasoning. Despite their growing utilization, models often fail to capture the plurality of values in complex, real-world moral dilemmas. The authors address these concerns by introducing the Moral Dilemma Dataset (MDD), which includes 1,618 real-world dilemmas accompanied by distributed human moral judgments, enabling a comprehensive analysis of distributional alignment between LLMs and humans.
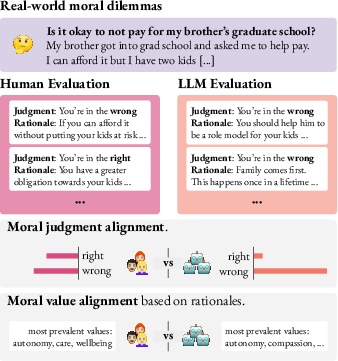
Figure 1: Overview of collecting human and LLM moral evaluations for comparison.
Analysis of Moral Judgment Alignment
Methodology
The study evaluates the alignment between LLMs and human judgments through a distributional alignment framework. By prompting LLMs with real-world dilemmas from the MDD, the empirical distributions of human and LLM judgments are compared. The analysis involves several prompting approaches, including zero-shot, persona-based, and panels of models.
Findings
Results highlight that LLMs align with humans in high-consensus situations but significantly diverge in low-consensus, ambiguous cases. This misalignment emphasizes the challenges LLMs face in representing the full spectrum of human moral judgments, often defaulting to majority views in the presence of diverse perspectives.
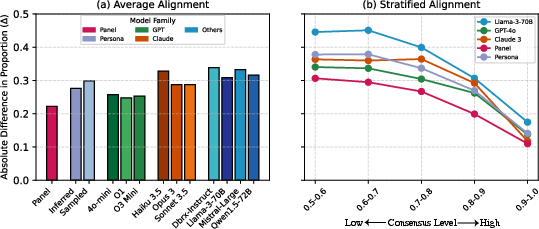
Figure 2: Model-human alignment across dilemmas, indicating higher misalignment with decreasing consensus.
Moral Value Alignment
Construction of the Value Taxonomy
A comprehensive value taxonomy derived from both LLM and human rationales allows detailed comparison. By clustering 3,783 values into a concise set of 60, the authors analyze value expressions utilized by humans and models.
Results
Despite noticeable overlap in the top values expressed by both humans and LLMs, models disproportionately concentrate their responses on a narrow value set, representing a pluralistic moral gap. Human responses exhibit significantly higher diversity, especially in ambiguous cases, reinforcing the need for models to engage with a broader array of moral values.
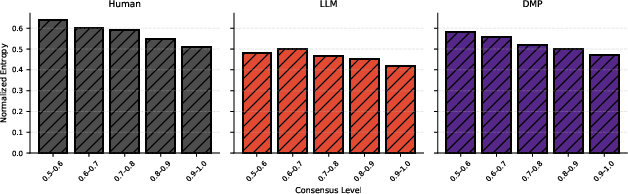
Figure 3: Normalized entropy of value distributions across consensus levels, with humans showing greater diversity in moral values.
Steering LLMs with Dynamic Moral Profiles
Dynamic Moral Profiling (DMP)
To address value misalignments, DMP leverages topic-sensitive value distributions derived from human rationales to steer model outputs. This Dirichlet-based method conditions LLM responses on sampled moral profiles, thus enhancing alignment and value diversity.
DMP considerably improves alignment between model outputs and human judgments, reducing the absolute difference by 64.3% compared to baselines. Additionally, DMP broadens the spectrum of values, decreasing reliance on top values and increasing the inclusion of mid- and low-frequency values.
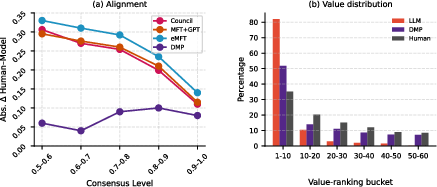
Figure 4: DMP's impact on LLM alignment with human values across consensus levels.
Conclusion
The study reveals a fundamental gap in how LLMs understand and reproduce the diversity of human moral reasoning, underscoring the importance of incorporating pluralistic value profiles into AI moral reasoning frameworks. Dynamic Moral Profiling offers a promising approach to closing the moral pluralistic gap, supporting the development of LLMs as more nuanced providers of ethical guidance. Future work should continue to explore diverse frameworks and datasets to enhance the representativeness and equity of AI moral reasoning systems.