- The paper introduces a novel grid-based LoRA framework that personalizes text-to-video synthesis without test-time fine-tuning.
- It employs Multi DC LoRA, Grid LoRA, and Grid-Fill LoRA to structure dynamic concept variations and achieve seamless inpainting.
- Experiments demonstrate superior motion fidelity, semantic alignment, and identity preservation across diverse dynamic scenarios.
Zero-Shot Dynamic Concept Personalization with Grid-Based LoRA
Overview
The paper "Zero-Shot Dynamic Concept Personalization with Grid-Based LoRA" introduces a feedforward framework designed to personalize dynamic concepts within text-to-video generation models without requiring test-time fine-tuning. The system comprises three core modules: Multi Dynamic Concept (DC) LoRA, Grid LoRA, and Grid-Fill LoRA. This framework achieves scalable, zero-shot dynamic concept personalization, demonstrated across various subjects and compositions.
Framework Design
Multi Dynamic Concept (DC) LoRA
The Multi DC LoRA component captures dynamic concepts—specifically, subject-specific appearance and motion—by consolidating multiple dynamic scenarios into a unified adapter. It employs dual low-rank updates to encode both appearance (A1B1) and motion (A1B2) for different subjects within a video, allowing for effective generalization across unseen scenarios:
ΔWapp=A1B1,ΔWmot=A1B2
This strategy ensures the model maintains consistency across different subjects and motions without needing individual fine-tuning.
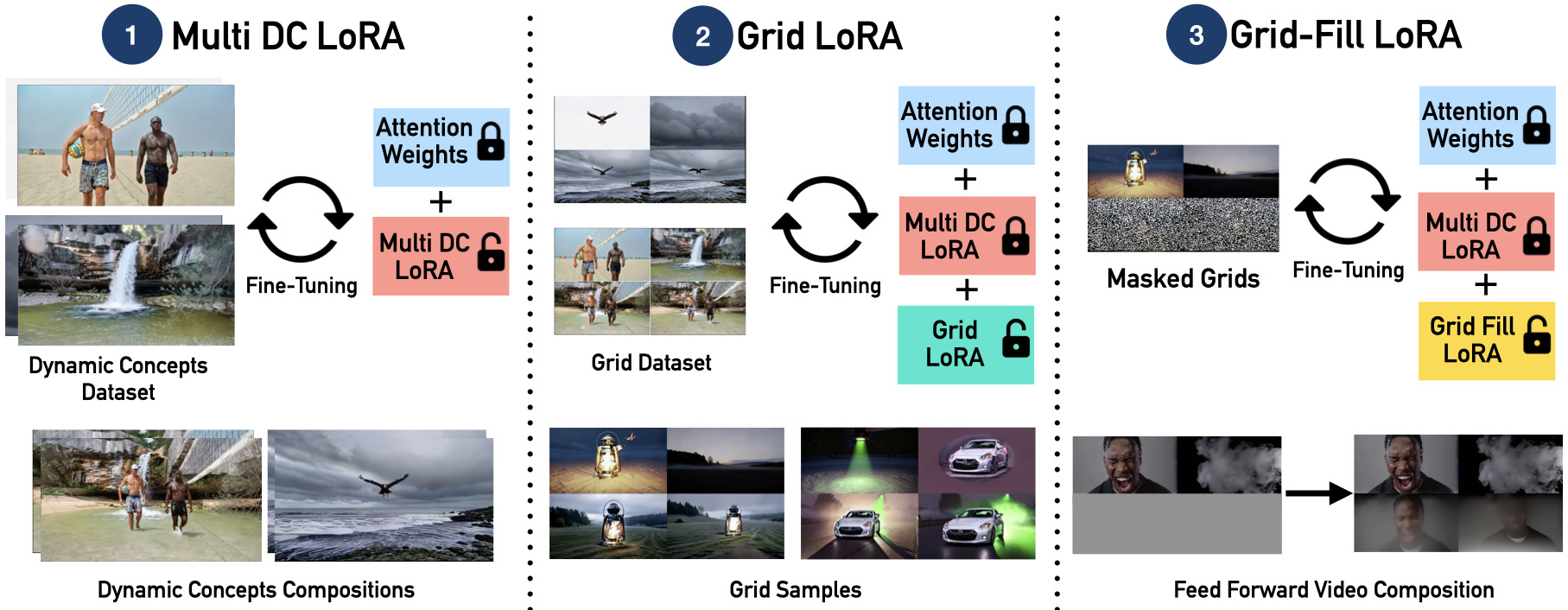
Figure 1: Overview of our feedforward framework for dynamic concept personalization in text-to-video generation, eliminating the need for test-time fine-tuning. The system comprises three core modules: (i) Multi DC LoRA, (ii) Grid LoRA, and (iii) Grid-Fill LoRA.
Grid LoRA
Grid LoRA is trained on structured 2×2 grids that spatially organize dynamic concept variations. During this process, distinct dynamic concepts populate the grid's top row (e.g., smoke or light) with their compositions in the lower row. This method enables structured attention masking, crucial for preventing concept leakage across grid cells:
Dynamic Concepts Personalization
Grid-Fill LoRA
The Grid-Fill LoRA component performs non-autoregressive, feedforward inpainting, seamlessly filling unobserved grid sections while preserving temporal coherence and identity fidelity. This module relies on pre-learned Multi-DC LoRA weights, enhancing model consistency.

Figure 3: Ablation of Design Choices. We ablate against two design choices i.e. augmenting the training set and removing Multi-DC LoRA during inference.
Inference Process
The inference involves sampling dynamic concepts to populate grid cells, using Grid-Fill LoRA to complete the grids. This enables the generation of high-fidelity, personalized video sequences that do not require optimization or adaptation during runtime.
Experimental Evaluation
The paper's extensive experiments validate this framework's efficacy, showing consistent performance in motion fidelity and identity preservation across diverse subjects. Comparisons with baselines demonstrate superior semantic alignment (C-T), identity preservation (ID), and temporal coherence (TC).

Figure 4: Grid LoRA Sampling results showing consistent dynamic concepts (left) and composition tasks (right).
Conclusion
The proposed grid-based LoRA framework enhances the scalability and personalization of text-to-video models through zero-shot generalization. It circumvents the limitations of existing techniques that require computationally intensive test-time optimization. Future endeavors may focus on long-sequence dynamics and multimodal conditioning to further refine and expand the capabilities of this framework.
In summary, this research represents a notable advancement in text-to-video synthesis, providing an efficient and robust method for real-time, personalized video content generation without the typical constraints of large-scale data and significant computational resources.
