- The paper introduces a novel recurrent architecture with adaptive 3D spatio-temporal memory and dual-source decoding to enable efficient streaming 3D reconstruction.
- It demonstrates a 27% reduction in memory tokens and a 20% increase in inference speed through an innovative memory gating mechanism.
- Experimental results show state-of-the-art accuracy and real-time performance (∼22 FPS on RTX 3090) across diverse datasets.
LONG3R: A Framework for Long Sequence Streaming 3D Reconstruction
Introduction and Motivation
LONG3R addresses the challenge of real-time, streaming 3D reconstruction from long sequences of images, a task central to robotics, AR/VR, and autonomous navigation. While recent end-to-end neural approaches such as DUSt3R, MASt3R, and Spann3R have advanced the field, they exhibit limitations in memory efficiency, scalability to long sequences, and robustness to error accumulation. LONG3R introduces a recurrent architecture with a novel 3D spatio-temporal memory, memory gating, and a dual-source refined decoder, enabling efficient and accurate reconstruction over tens to hundreds of frames with near-constant memory requirements.
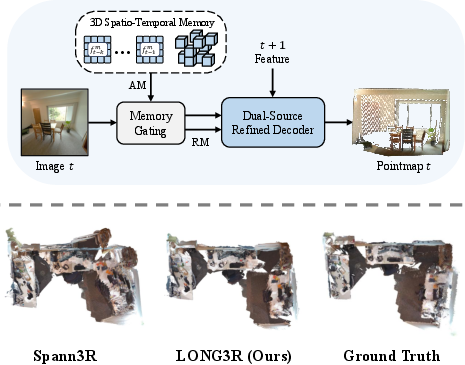
Figure 1: (Top) Overview of the LONG3R framework, integrating a 3D spatio-temporal memory module and memory gating with a dual-source refined decoder. (Bottom) Qualitative comparison of 3D reconstructions from Spann3R, LONG3R, and ground truth, highlighting improved point prediction accuracy.
Methodology
Architecture Overview
LONG3R processes streaming image sequences recurrently. Each incoming frame is encoded via a ViT-based encoder, and features are passed through a coarse decoder that interacts with the previous frame's features. The output is then filtered by an attention-based memory gating module, which selects relevant entries from a spatio-temporal memory bank. The filtered memory and the next-frame features are then processed by a dual-source refined decoder, which alternates between memory and temporal attention to produce the final 3D pointmap prediction.
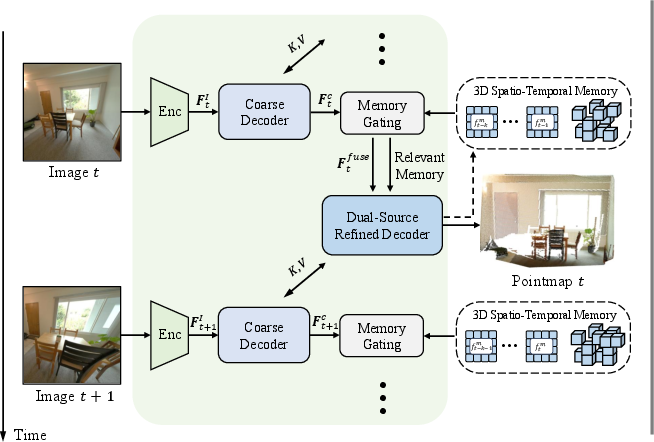
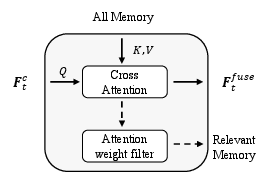
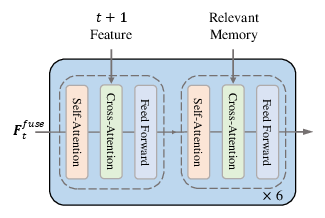
Figure 2: (a) Overall architecture: image features interact temporally and with memory; (b) Attention-based memory gating selects relevant memory; (c) Dual-source refined decoder alternates between memory and next-frame features for robust prediction.
3D Spatio-Temporal Memory and Pruning
LONG3R's memory mechanism is split into short-term temporal memory (recent frames) and long-term 3D spatial memory (historical tokens). The spatial memory is organized into adaptive voxels, with only the token having the highest accumulated attention weight retained per voxel. This dynamic pruning reduces redundancy and adapts to scene scale, maintaining a compact yet informative memory representation.
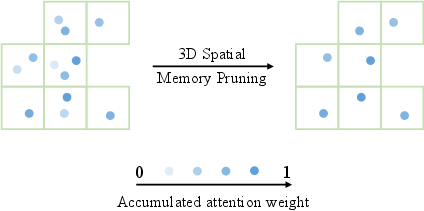
Figure 3: 3D spatial memory pruning: tokens are grouped into voxels by 3D position, retaining only the most relevant token per voxel based on attention weight.
Memory Gating
The memory gating module computes cross-attention between the current frame's features and all memory tokens. Tokens with attention weights above a threshold are retained as relevant memory, while others are discarded. This mechanism reduces computational load and focuses the decoder on pertinent context, yielding a 27% reduction in memory tokens and a 20% increase in inference speed without loss of accuracy.

Figure 4: Number of memory tokens before (all memory) and after (relevant memory) memory gating, demonstrating significant reduction.
Dual-Source Refined Decoder
The dual-source refined decoder alternates between pairwise attention with the next frame and memory attention with the relevant memory tokens. An ablation study demonstrates that this interleaved design outperforms simple concatenation, both in accuracy and computational efficiency, by progressively aligning feature spaces and mitigating information loss.
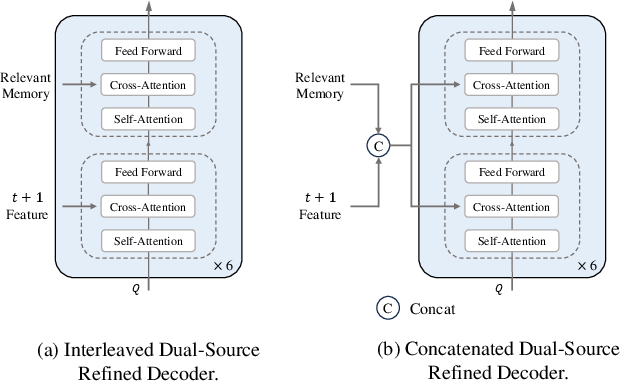
Figure 5: Comparison of interleaved and concatenated dual-source decoder architectures, with interleaved attention yielding superior results.
Training Strategy
A two-stage curriculum training strategy is employed. The first stage samples short sequences (5 frames) to pretrain the encoder and decoder. The second stage freezes the encoder and fine-tunes the rest of the network on longer sequences (10 and then 32 frames), enabling the model to adapt to complex memory interactions and long-term dependencies.
Experimental Results
LONG3R is evaluated on 7Scenes, NRGBD, and Replica datasets, using accuracy, completeness, and normal consistency metrics. It achieves the highest reconstruction accuracy among streaming methods and matches or exceeds the performance of post-optimization and offline methods, while maintaining real-time inference (∼22 FPS on RTX 3090). Notably, LONG3R avoids the catastrophic degradation observed in other streaming methods as sequence length increases.

Figure 6: Qualitative comparison on 7Scenes, showing superior spatial consistency and real-time performance compared to Spann3R and CUT3R.

Figure 7: Qualitative comparison on Replica, demonstrating LONG3R's robustness to error accumulation and maintenance of spatial consistency over long sequences.
Camera Pose Estimation
LONG3R outperforms Spann3R and CUT3R in absolute and relative pose estimation on static scene datasets (7Scenes, ScanNet), and remains competitive on dynamic scenes (TUM), despite being trained only on static data.
Ablation Studies
- Memory Gating: Reduces memory size and increases FPS with negligible impact on accuracy.
- Dual-Source Decoder: Interleaved attention blocks outperform concatenation, especially for long sequences.
- 3D Spatio-Temporal Memory: Removing long-term spatial memory or reverting to Spann3R's memory design significantly degrades performance, confirming the necessity of adaptive spatial memory and pruning.
Implementation Considerations
- Hardware: Training requires 16 A100 GPUs for 28 hours (stage 1) and 20 hours (stage 2); inference is real-time on a single RTX 3090.
- Memory: Adaptive voxelization and memory gating ensure near-constant memory usage, even for hundreds of frames.
- Scalability: The architecture is robust to sequence length and scene scale, but performance may degrade if the viewpoint deviates significantly from the initial frame or in highly dynamic scenes.
- Deployment: The model is suitable for real-time applications in robotics and AR/VR, where streaming, low-latency 3D reconstruction is required.
Implications and Future Directions
LONG3R demonstrates that efficient, accurate, and real-time 3D reconstruction from long image sequences is achievable with a carefully designed memory architecture and training strategy. The integration of adaptive 3D spatial memory and memory gating sets a new standard for streaming methods, narrowing the gap with offline and post-optimization approaches. The framework's modularity suggests potential for extension to dynamic scenes, integration with SLAM backends, or adaptation to other sequential vision tasks.
Conclusion
LONG3R introduces a principled approach to long-sequence streaming 3D reconstruction, combining memory gating, dual-source decoding, and adaptive 3D spatio-temporal memory. It achieves state-of-the-art accuracy and real-time performance, with strong empirical results and ablation studies validating each component. Limitations include reduced robustness to large viewpoint changes and dynamic scenes, indicating directions for future research, such as dynamic memory adaptation and training on dynamic datasets.