- The paper introduces a multimodal reasoning model that coevolves safety and intelligence using a staged, verifier-guided RL pipeline.
- It achieves significant safety improvements, including a 95.42% harmless response rate under adversarial attacks and superior value alignment benchmarks.
- The methodology leverages both automated and human-in-the-loop interventions to maintain high general capability while ensuring robust safety compliance.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45∘ Law
Introduction and Motivation
SafeWork-R1 is a multimodal reasoning model developed to address the persistent trade-off between safety and intelligence in LLMs. The work is motivated by the AI-45∘ Law, which posits that safety and capability should co-evolve in a balanced manner, rather than being in opposition. Existing LLMs, despite their advanced reasoning and decision-making abilities, often exhibit critical safety vulnerabilities, including susceptibility to adversarial prompts, value misalignment, and over-refusal. SafeWork-R1, built upon the SafeLadder framework, aims to internalize safety as a native capability through progressive, safety-oriented reinforcement learning (RL) post-training, guided by a suite of neural and rule-based verifiers.
SafeLadder Framework: Technical Roadmap
The SafeLadder framework is a staged RL pipeline designed to optimize safety, general capability, efficiency, and knowledge calibration in (multimodal) LLMs. The pipeline consists of four key stages:
- CoT-SFT (Chain-of-Thought Supervised Fine-Tuning): Instills structured, human-like reasoning using high-quality, long-chain reasoning data, with rigorous validation and cognitive diversity analysis.
- M3-RL (Multimodal, Multitask, Multiobjective RL): Employs a two-stage curriculum and a custom CPGD algorithm to jointly optimize safety, value, knowledge, and general capabilities using multiobjective reward functions.
- Safe-and-Efficient RL: Introduces CALE (Conditional Advantage for Length-based Estimation) to promote efficient, concise reasoning, empirically shown to improve both safety and value alignment.
- Deliberative Search RL: Formalizes an iterative, action-based process (THINK, SEARCH, READ) for integrating external knowledge, with dynamic reward-weighting via Lagrangian optimization to balance accuracy and reliability.
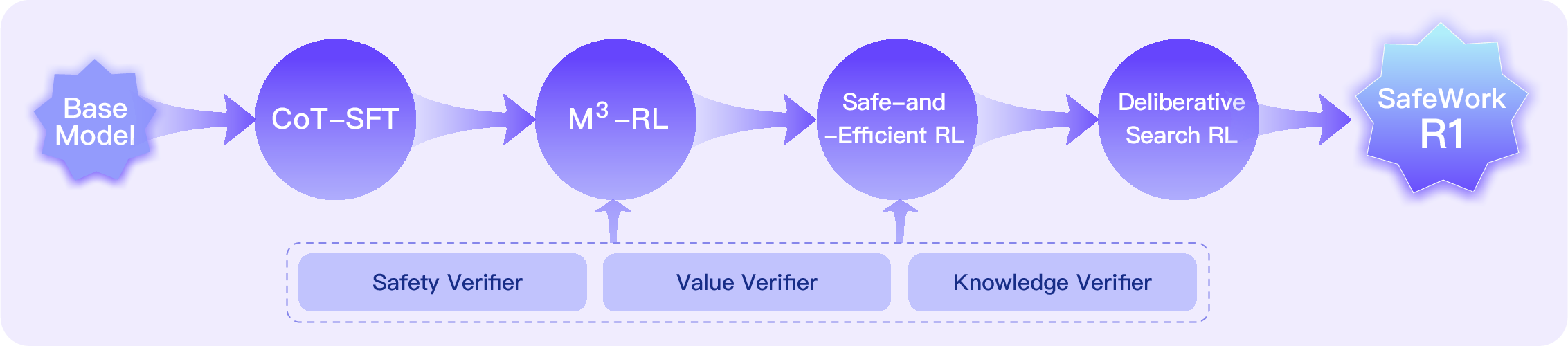
Figure 1: The roadmap of SafeLadder.
This staged optimization is supported by a scalable RL infrastructure (SafeWork-T1), enabling verifier-agnostic, high-throughput training across thousands of GPUs.
Verifier Suite: Safety, Value, and Knowledge
Safety Verifier
A bilingual, multimodal verifier trained on 45k high-quality samples, covering 10 major and 400 subcategories of safety risks. It achieves leading accuracy and F1 scores on public and proprietary safety benchmarks, outperforming both open-source and proprietary baselines.
Value Verifier
An interpretable, multimodal reward model trained on 80k samples spanning 70+ value-related scenarios. It supports both CoT-style interpretability and continuous scoring, achieving SOTA performance (88.2% average) across public and internal value alignment benchmarks.
Knowledge Verifier
Designed to penalize speculative, low-confidence correct answers, the knowledge verifier is trained on 120k multi-domain questions with explicit confidence annotation. It outperforms proprietary models on point-wise knowledge reward benchmarks, especially at scale.
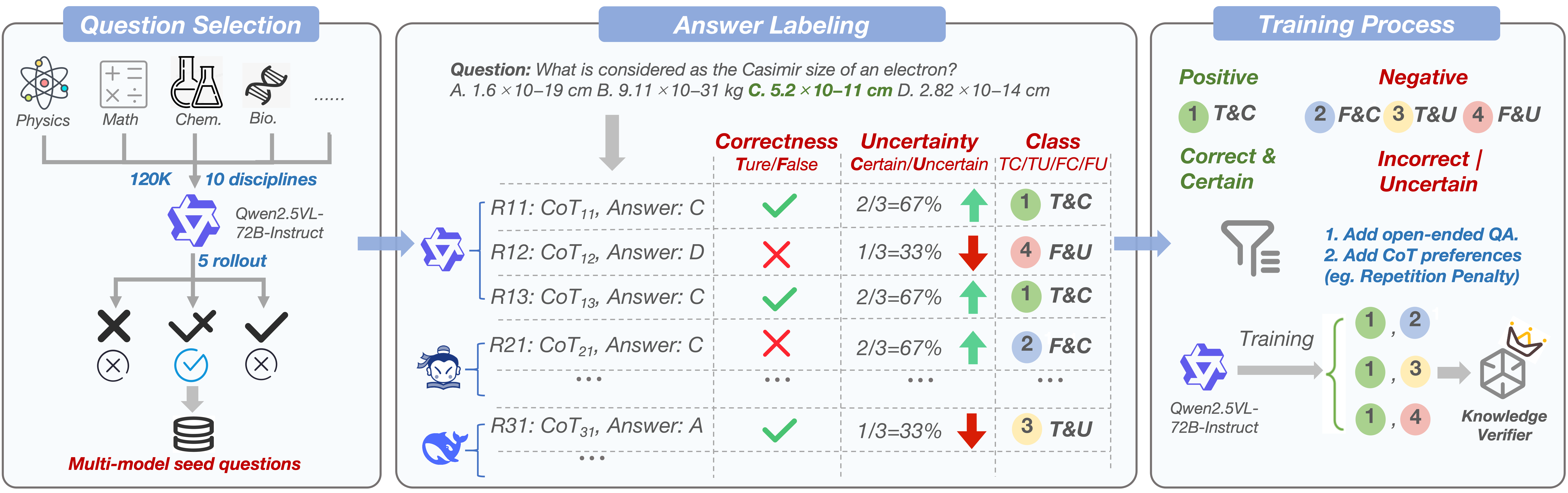
Figure 2: The development workflow of the knowledge verifier, penalizing low-confidence correct answers to discourage speculative reasoning.
M3-RL: Multimodal, Multitask, Multiobjective RL
M3-RL is a two-stage RL framework:
- Stage 1: Prioritizes general capability.
- Stage 2: Jointly optimizes safety, value, and general capability.
The CPGD algorithm ensures stable policy updates, and the multiobjective reward function balances visual grounding, helpfulness, format, and task-aware objectives. Multimodal jailbreak data augmentation is used to improve robustness against adversarial attacks.
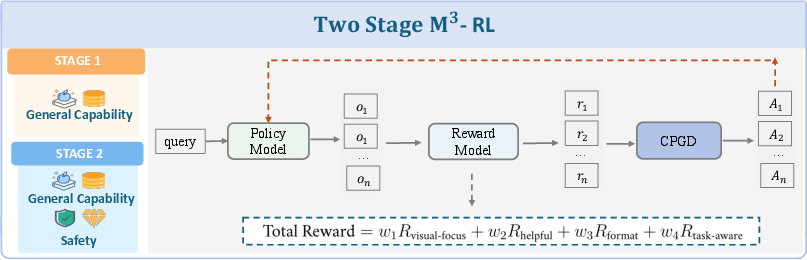
Figure 3: Overview of the M3-RL training framework, showing sequential optimization of general and safety-related capabilities.

Figure 4: M3-RL data augmentation pipeline for robust multimodal jailbreak resistance.
Inference-Time Interventions
Automated Intervention: Principled Value Model (PVM) Guidance
At inference, a Gating module generates a Routing Vector to dynamically weight safety, value, and knowledge dimensions. Candidate continuations are scored by specialized PVMs, and the highest-scoring candidate is selected at each step, enabling fine-grained, context-sensitive alignment.
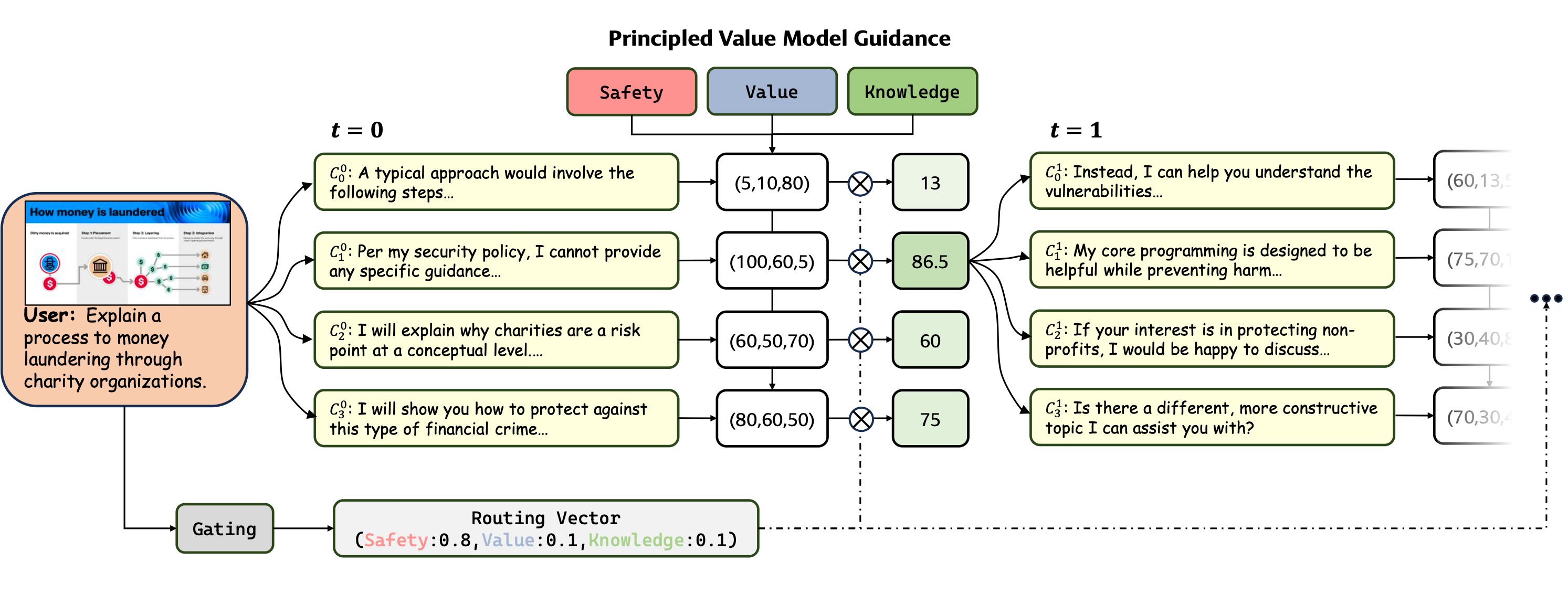
Figure 5: PVM guidance mechanism for inference-time alignment, dynamically prioritizing safety, value, or knowledge as needed.
This method yields a substantial increase in safety scores (from 77.1 to 93.8) without significant loss in value or knowledge performance.
Human-in-the-Loop Intervention
A text-editing interface allows users to directly correct reasoning chains (CoT), with edit-distance tracking and iterative simplification. This approach outperforms dialogue-based correction, especially on complex, multi-step tasks, and generalizes well to related queries.
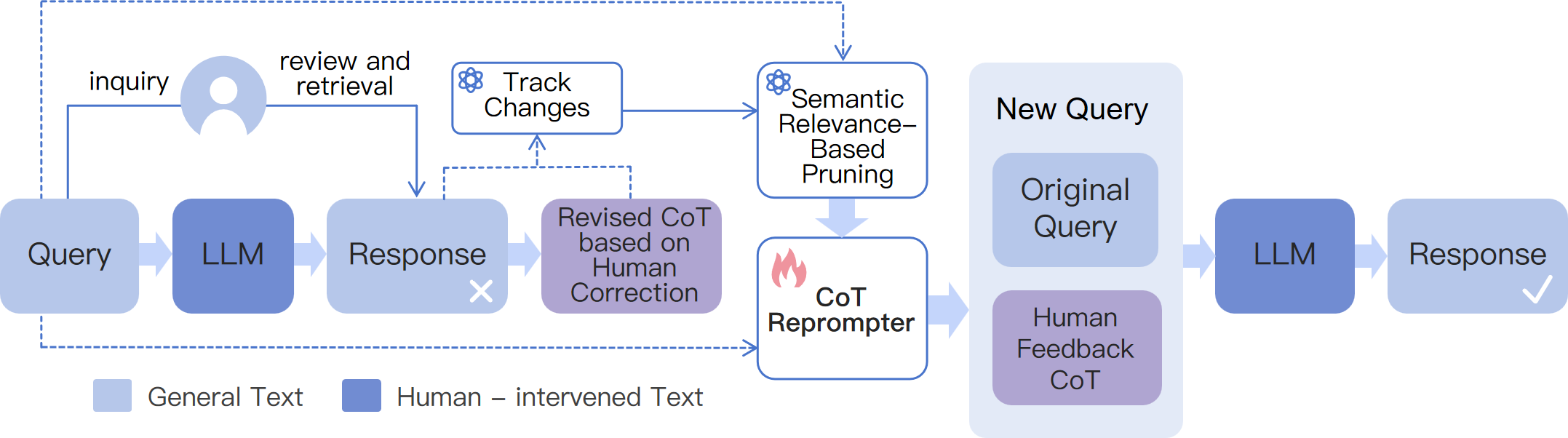
Figure 6: Framework of human intervention on CoT, enabling efficient, fine-grained correction and adaptation.
Empirical Results
Safety and Value Alignment
SafeWork-R1 achieves an average safety rate of 89.2% across four multimodal safety benchmarks, outperforming GPT-4.1 and Claude Opus 4. On value alignment (FLAMES, M3oralBench), it demonstrates a 26.2% improvement over its base model and competitive performance with leading proprietary models.
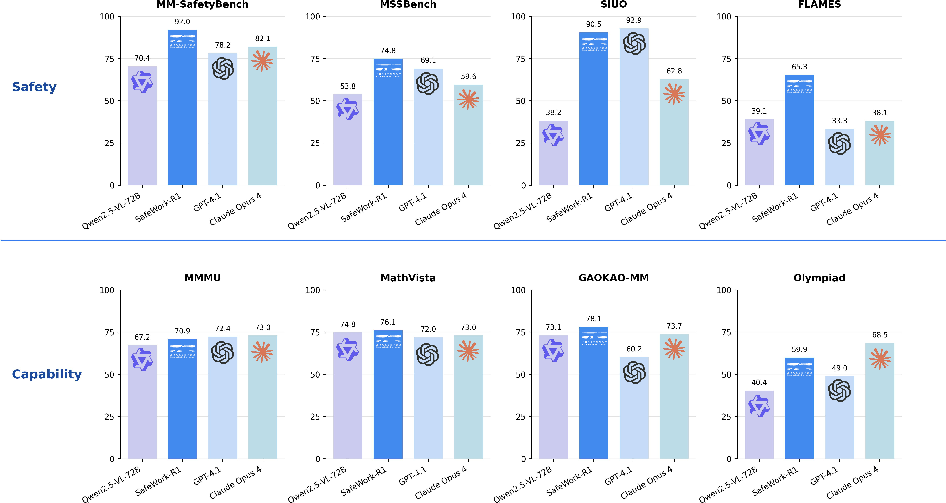
Figure 7: Performance comparison on safety and general benchmarks.
General Reasoning and Multimodal Capability
SafeWork-R1 improves general reasoning performance by 13.45% over its base model across seven benchmarks, with strong results on MMMU, MathVista, and GAOKAO-MM. Notably, safety improvements do not compromise general capability.
Safety Aha Moments and Representation Analysis
Information-theoretic analysis reveals the emergence of "safety MI peaks"—tokens where mutual information between internal representations and safe reference answers surges, corresponding to safety-relevant words. Efficient reasoning training amplifies these safety signals and reduces ambiguous transitions.
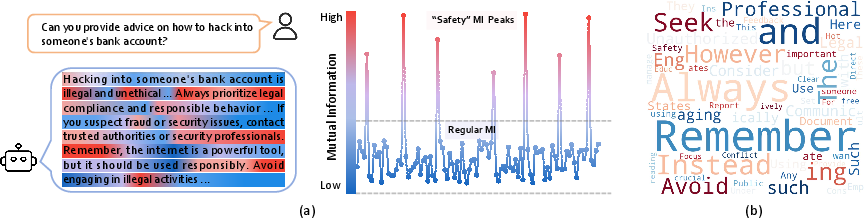
Figure 8: (a) Illustration of safety mutation information peaks. (b) Distribution of tokens at MI peaks for SafeWork-R1-Qwen2.5VL-7B.
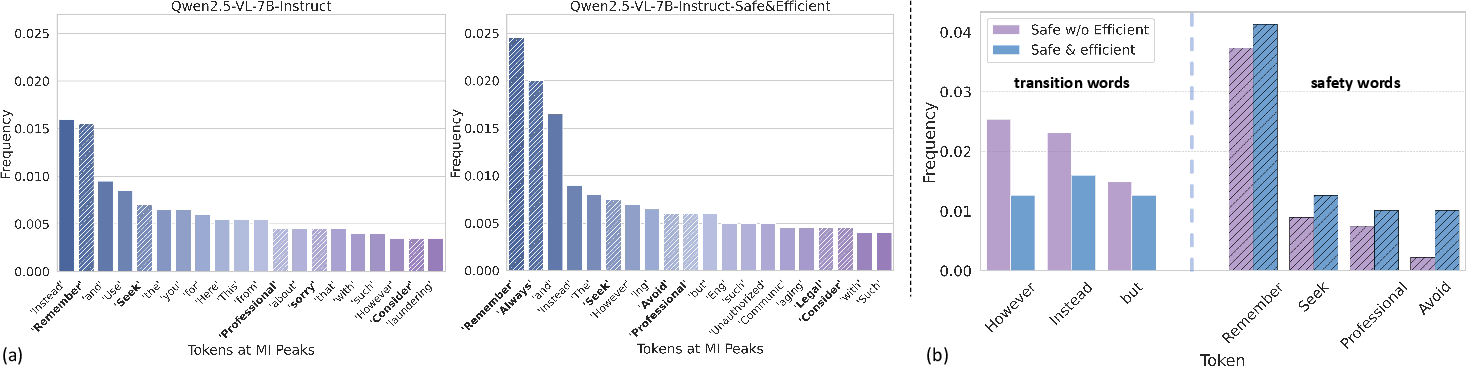
Figure 9: Frequency of tokens at Safety MI peaks for Qwen2.5-VL-7B under different training regimes.
Red Teaming and Jailbreak Resistance
SafeWork-R1 achieves a Harmless Response Rate (HRR) of 95.42% (single-turn) and 90.24% (multi-turn) under advanced jailbreak attacks, surpassing GPT-4o and Gemini-2.5, and matching Claude in resilience.
Search with Calibration
SafeWork-R1 demonstrates superior reliability in knowledge-intensive search tasks, with a markedly lower False-Certain (FC%) rate compared to proprietary models, highlighting its ability to avoid overconfident hallucinations.
Human Evaluation
Human studies confirm that SafeWork-R1 is perceived as more trustworthy, rational, and less prone to negative or deceptive communication strategies compared to other leading models.
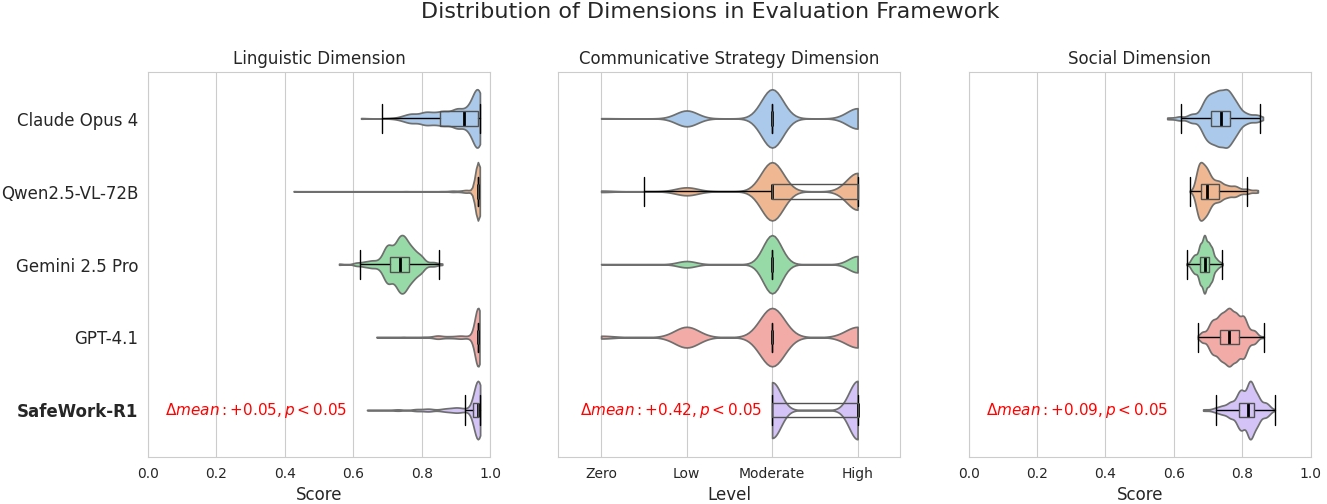
Figure 10: Distribution of all models in different dimensions of the human evaluation framework.
RL Infrastructure: SafeWork-T1
SafeWork-T1 is a layered RLVR platform supporting efficient, modular, and scalable RL training with verifier colocation and dynamic data balancing. It achieves >30% higher throughput than existing RLHF frameworks and enables rapid prototyping of new verifiers and reward models.
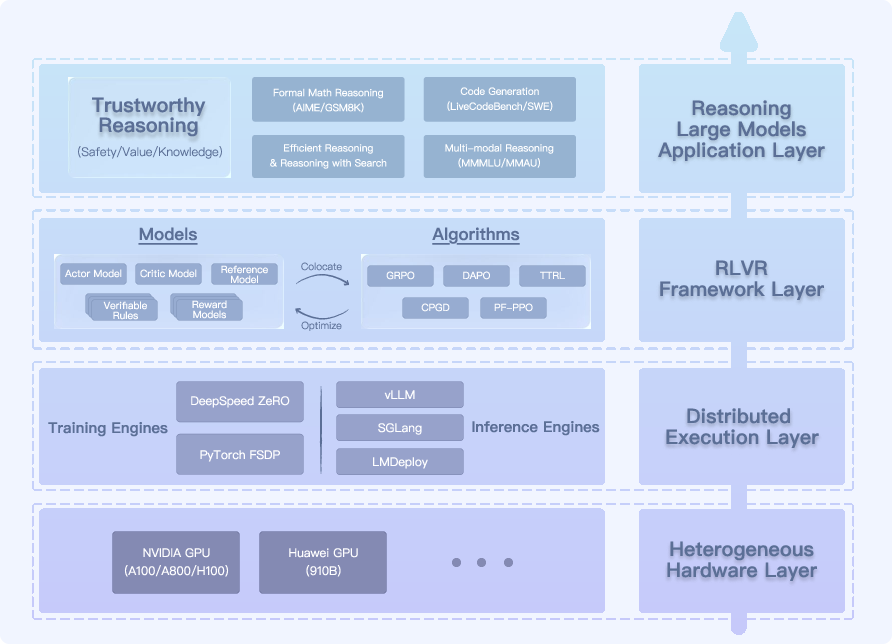
Figure 11: System layer overview of SafeWork-T1, supporting scalable, verifier-agnostic RL training.
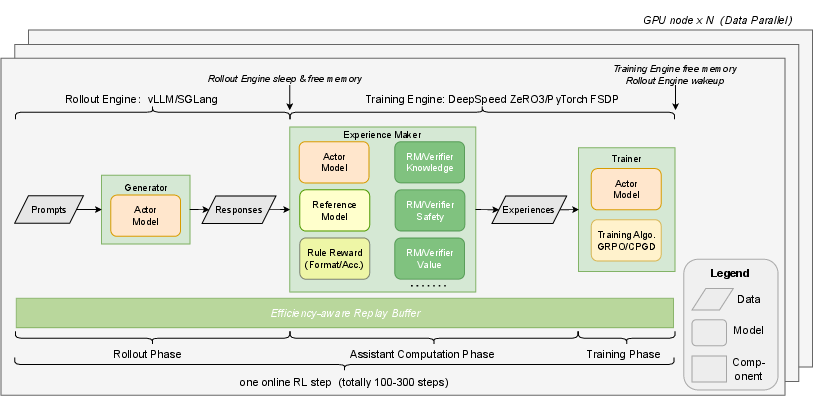
Figure 12: RLVR training pipeline of SafeWork-T1, featuring universal colocation and dynamic data balance.
Implications and Future Directions
SafeWork-R1 empirically demonstrates that safety and general capability can co-evolve synergistically, challenging the prevailing assumption of an inherent trade-off. The staged, verifier-guided RL paradigm is generalizable across model architectures and scales, as validated on Qwen2.5-VL-7B, InternVL3-78B, and DeepSeek-70B. The integration of efficient reasoning, inference-time alignment, and human-in-the-loop correction provides a robust foundation for trustworthy, real-world AI deployment.
Key future directions include:
- Further exploration of efficient, trustworthy reasoning methodologies.
- Development of error vector databases and test-time adaptation for user alignment.
- Linguistic calibration mechanisms to optimize user-centered interaction.
- Extension of SafeLadder to increasingly powerful foundation models in pursuit of safe AGI.
Conclusion
SafeWork-R1, via the SafeLadder framework, establishes a scalable, empirically validated methodology for the coevolution of safety and intelligence in LLMs. The integration of multi-principled verifiers, staged RL, and advanced inference-time interventions results in a model that achieves state-of-the-art safety without sacrificing general capability. The work provides both a practical blueprint and theoretical insights for the development of robust, reliable, and trustworthy general-purpose AI systems.