- The paper presents ScenethesisLang, a DSL that unifies scene description and constraint specification to bridge the gap between NL requirements and executable 3D software.
- The paper details a modular pipeline that leverages hybrid asset synthesis and an iterative spatial constraint solver, achieving over 93% constraint satisfaction.
- The paper demonstrates enhanced traceability, maintainability, and scalability in 3D software synthesis compared to monolithic, end-to-end approaches.
Introduction and Motivation
The synthesis of 3D software from natural language (NL) requirements presents unique challenges not encountered in 2D UI code generation. The spatial, physical, and semantic complexity of 3D environments, coupled with the need for fine-grained control and verifiability, renders monolithic, end-to-end neural approaches insufficient for practical software engineering (SE) applications. Existing methods, such as scene graph-based approaches, are fundamentally limited by categorical expressiveness and lack the ability to encode continuous, multi-relational, and domain-specific constraints. Furthermore, the absence of an interpretable, constraint-aware intermediate representation (IR) impedes traceability, maintainability, and targeted modification—core SE principles.
Scenethesis addresses these limitations by introducing a modular, four-stage synthesis pipeline underpinned by ScenethesisLang, a domain-specific language (DSL) that unifies scene description and constraint specification. This approach enables the systematic translation of NL requirements into executable 3D software, supporting independent verification, targeted modification, and robust constraint satisfaction.
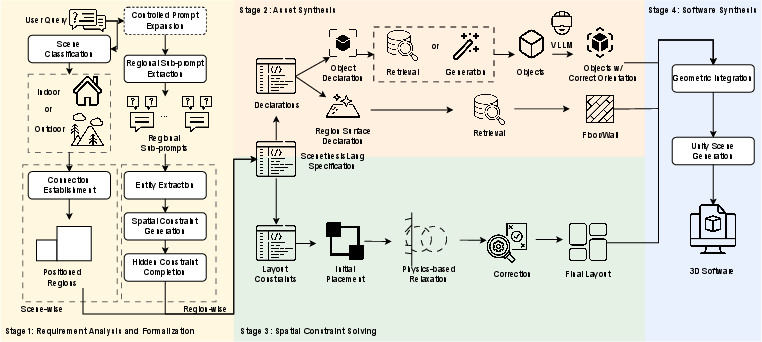
Figure 2: Overview of Scenethesis, illustrating the modular pipeline from NL requirements to executable 3D software via a constraint-expressive IR.
ScenethesisLang is a DSL designed to bridge the semantic gap between high-level user requirements and low-level 3D software artifacts. It supports:
- Object and region declarations with explicit properties (color, material, features, category, dimensions).
- Constraint statements capable of expressing arbitrary spatial, physical, and semantic relationships using a rich algebra of operations and predicates.
- Continuous and multi-relational constraints, overcoming the categorical limitations of scene graphs.
- Logical composition (conjunction, disjunction, negation) for complex constraint specification.
This formalization enables both human and machine interpretability, systematic verification, and round-trip engineering.
Modular Synthesis Pipeline
NL requirements are parsed and expanded using LLMs to extract explicit and implicit constraints. The process involves:
- Scene context classification (indoor/outdoor) to determine applicable constraint templates.
- Entity extraction and property assignment for all objects and regions.
- Constraint generation for both explicit spatial relationships and inferred physical laws (e.g., collision avoidance, gravity).
- Redundancy and contradiction elimination via iterative LLM-based validation.
The output is a ScenethesisLang program that serves as the single source of truth for subsequent stages.
Stage II: Asset Synthesis
Each object is synthesized independently using a hybrid strategy:
- Retrieval-based acquisition from curated 3D model databases, leveraging CLIP and Sentence-BERT for visual and semantic similarity scoring.
- Generative acquisition via text-to-3D models (e.g., Shap-E) when retrieval fails.
- Canonical orientation verification using VLMs to ensure consistent object alignment.
This modular approach supports parallelization and facilitates targeted asset replacement.
Stage III: Spatial Constraint Solving
Object placement is formulated as a constraint satisfaction problem (CSP) over continuous 3D space. The Rubik Spatial Constraint Solver employs an iterative, local-to-global refinement strategy:
This approach avoids the exponential complexity of traditional CSP solvers and scales to scenarios with 100+ simultaneous constraints.
Stage IV: Software Synthesis
The final stage integrates solved object layouts and synthesized assets into executable Unity-compatible scenes:
- Geometric integration ensures correct alignment, scaling, and material application.
- Physics and interaction components are configured for realistic simulation.
- Metadata embedding preserves the ScenethesisLang specification for traceability and post-generation modification.
The output is a fully functional 3D software artifact, ready for deployment or further refinement.
Empirical Evaluation
Dataset Construction
A comprehensive dataset of 50 indoor scenes (75 rooms, 2032 objects, 1837 spatial relations) was constructed using a structured LLM-driven pipeline. Each scene is described by both detailed (average 508.4 words) and concise (average 28.5 words) NL queries, enabling robust evaluation of requirement capture and constraint satisfaction.
- Requirement Formalization: Scenethesis achieves F1 > 0.94 for object constraints and >0.86 for layout constraints at standard thresholds, with performance degrading at stricter thresholds due to the inherent difficulty of precise spatial formalization.
- Object Synthesis: The hybrid retrieval-generation strategy outperforms pure approaches, achieving a mean object-query coherence of 39.3% (BLIP-2/CLIP).
- Constraint Solving: The Rubik solver achieves >93% constraint satisfaction within 5 iterations, demonstrating both efficiency and scalability.
Scenethesis outperforms state-of-the-art baselines (end-to-end LLM, Holodeck) across all visual and semantic coherence metrics:
| Method |
BLIP-2 (O) |
BLIP-2 (S) |
CLIP (O) |
CLIP (S) |
VQA (O) |
VQA (S) |
| Scenethesis (Best) |
74.3 |
75.1 |
26.2 |
25.8 |
29.8 |
48.6 |
| End-to-end LLM |
71.6 |
73.2 |
25.6 |
25.3 |
27.1 |
41.1 |
| Holodeck |
67.0 |
66.5 |
24.2 |
23.5 |
26.0 |
42.1 |
Scenethesis achieves a 42.8% improvement in BLIP-2 visual evaluation scores over Holodeck, and consistently higher VQA scores, indicating superior alignment with user requirements and scene realism.
User Study
Human evaluators rated Scenethesis-generated scenes higher in layout coherence (4.12/5), spatial realism (3.89/5), and overall consistency (4.05/5) compared to baselines, confirming the practical benefits of the modular, constraint-driven approach.
Implementation and Extensibility
Scenethesis is implemented as a modular Python framework with pluggable components for each pipeline stage. The DSL grammar, asset synthesis strategies, constraint solvers, and output drivers are all extensible, supporting domain-specific adaptation (e.g., accessibility, safety, industrial simulation). The architecture is agnostic to LLM backbone and 3D asset sources, ensuring future-proofing as models and databases evolve.
Implications and Future Directions
The introduction of a constraint-expressive IR and modular synthesis pipeline marks a significant advance in the practical generation of 3D software. The approach enables:
- Fine-grained control and maintainability: Targeted modification and verification at each synthesis stage.
- Formal traceability: End-to-end mapping from requirements to software artifacts.
- Scalability: Efficient handling of complex, large-scale constraint sets.
Future research directions include:
- Extension to outdoor and specialized domains (e.g., industrial, artistic, or scientific 3D environments).
- Integration with physics-based simulation and continuous optimization solvers for enhanced realism.
- Automated repair and incremental update mechanisms leveraging the IR for live software maintenance.
- Broader human evaluation studies to further validate semantic and perceptual quality.
Conclusion
Scenethesis demonstrates that the application of SE principles—modularity, formal specification, and constraint-driven synthesis—enables the generation of high-quality, verifiable, and maintainable 3D software from NL requirements. The empirical results establish the superiority of this approach over monolithic, black-box generative methods, providing a robust foundation for future advances in automated 3D software engineering.