- The paper presents a self-guided masking strategy that leverages early patch clustering in MAEs to enhance learning efficiency.
- It pioneers an informed masking approach based on intrinsic patch similarity, accelerating convergence for image representation.
- Empirical results on tasks like object detection and semantic segmentation demonstrate improved performance over traditional random masking.
Analysis of "Self-Guided Masked Autoencoder" (2507.19773)
This essay explores the "Self-Guided Masked Autoencoder" paper, focusing on its core innovations, empirical results, and potential implications. The study introduces a novel self-supervised learning paradigm within computer vision, leveraging Masked Autoencoder (MAE) architectured around Vision Transformers (ViT). Notably, the research identifies intrinsic mechanisms in MAE that enable early-stage pattern-based patch clustering, leading to the development of a new informed masking strategy.
Introduction and Methodology
The proposed self-guided masked autoencoder method capitalizes on the inherent ability of MAEs to cluster image patches based on visual patterns from early pre-training stages. Traditional MAE, which uses random masking, is juxtaposed by a self-guided variant that generates informed masks. The process involves internally estimating patch clustering progress and substituting random masking with informed clustering-driven masking. This approach facilitates faster convergence and enhances learning efficacy without reliance on external resources or models.
The architecture operates on splitting input images into patches, which are then masked randomly or informedly. This asymmetrical encoder-decoder framework processes visible patches to learn robust feature representations. The decoder targets reconstruction of masked patches, drawing on encoder outputs to infer and fill occluded information. This intrinsic clustering ability found in MAE is extensively studied, revealing that meaningful token relations are established early in training.

Figure 1: Illustration of our self-guided MAE.
Empirical Evaluation
Empirical validation on downstream tasks such as image classification, object detection, and semantic segmentation substantiates the efficacy of the self-guided approach. Improvements in learning speed and model performance are consistently observed across varied datasets. This confirms that the newly proposed masking strategy significantly benefits learning representation quality, demonstrated by superior metrics on tasks like COCO for object detection and ADE20K for semantic segmentation.
An extensive analysis of token relationships uncovers that MAE produces distinct, pattern-based patch clustering, which emerges prominently from early epochs. By tracing token relation convergence and examining intra-cluster similarity (using metrics like μintra and μinter), the study evidences strong cluster separation in patch embeddings.


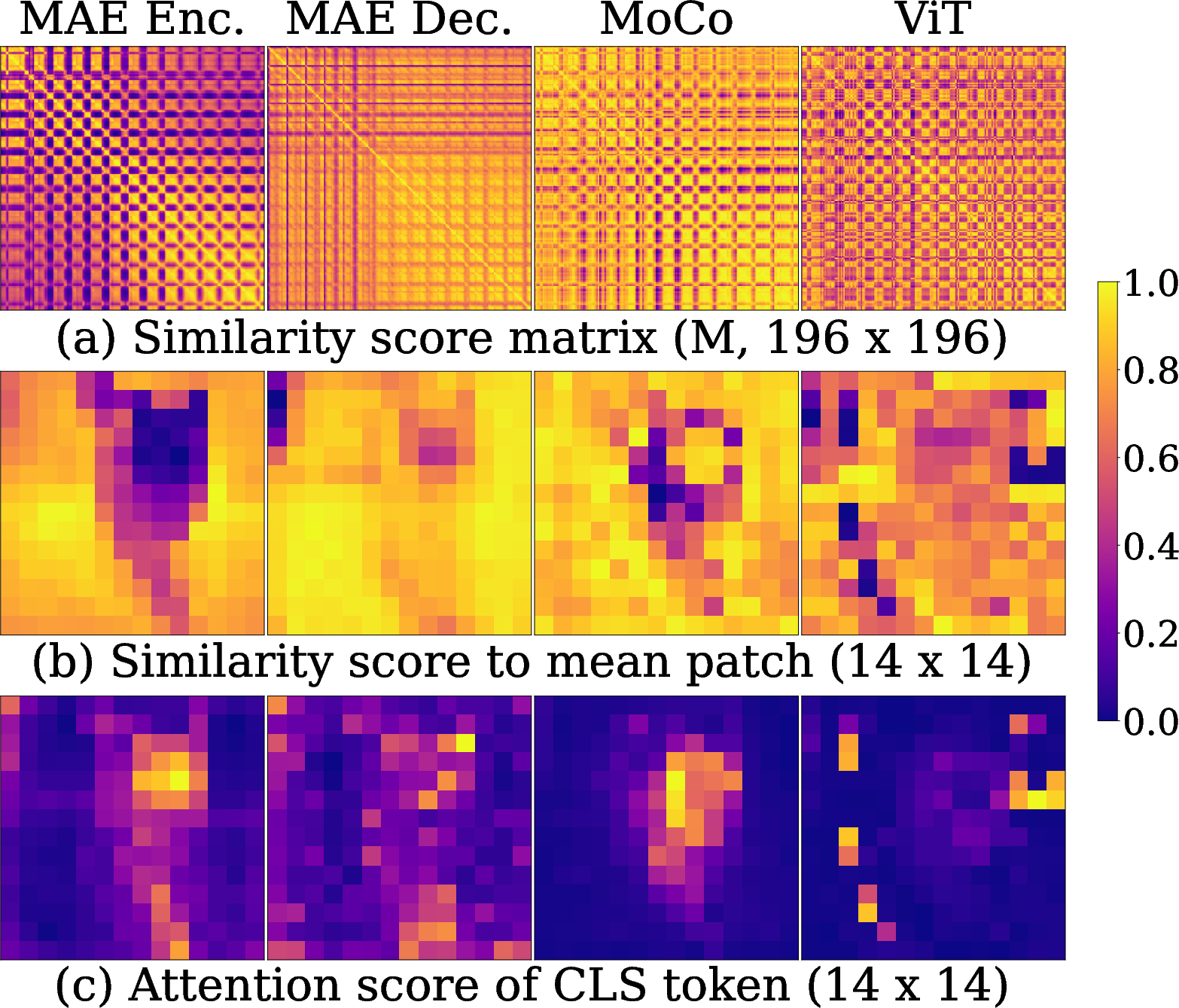
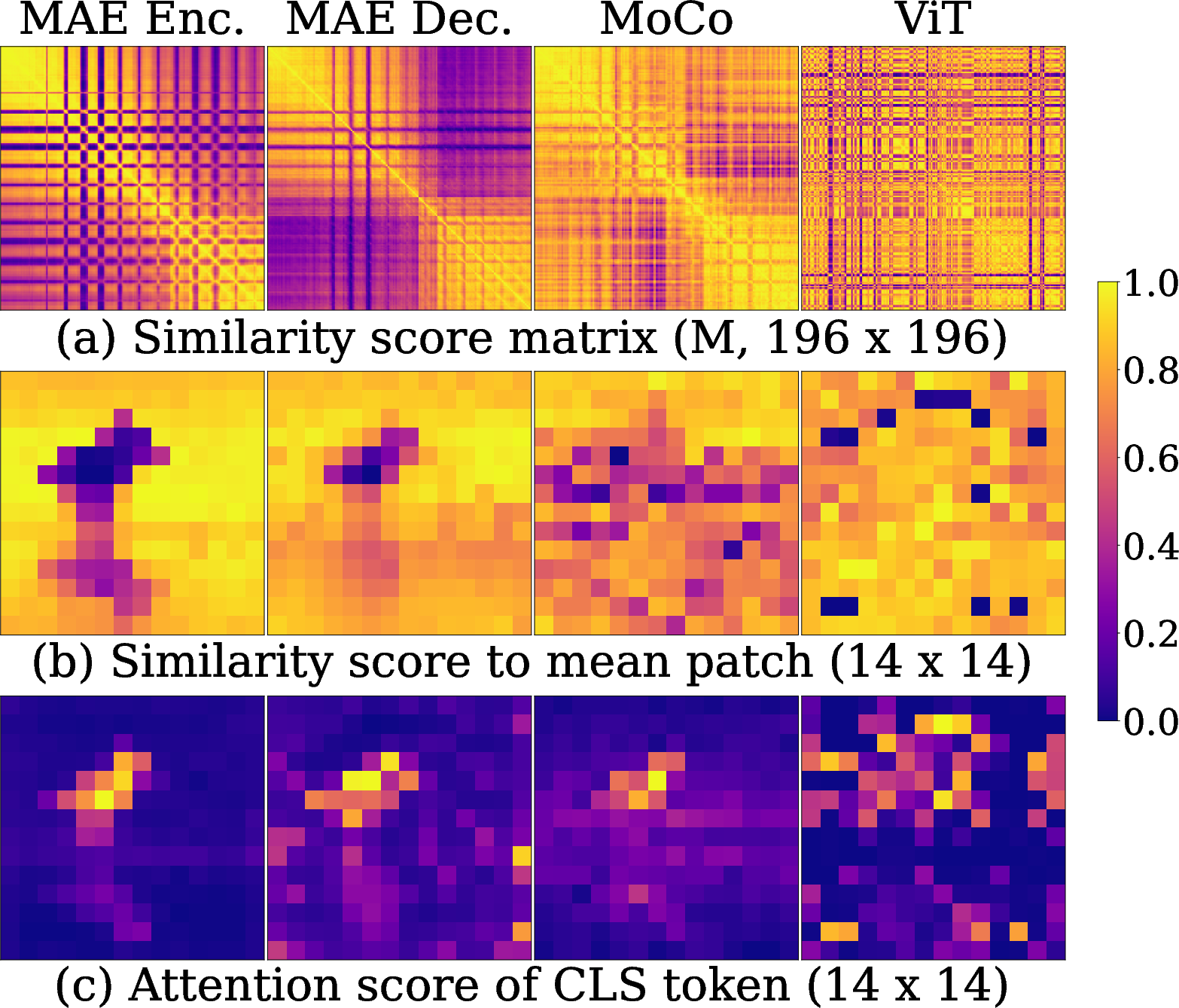
Figure 2: Relationships among the patch embeddings. (a) Pairwise similarity matrix for all 196 × 196 pairs of patches. (b) Similarity between the mean patch and all individual patches. (c) Attention score of the class token.
Implications and Future Work
The implications of this research extend computational efficiency and self-supervised learning dynamics. Exploration of patch similarity and object-centric masking presents new avenues for enhancing visual learning models. The self-guided MAE demonstrates potential to refine unsupervised learning’s robustness by minimizing dependency on vast labeled datasets.
The research introduces a metric, the exploitation rate, which tracks the utility of shared information in mask tokens during decoder operations. This rate identifies early convergence and leverages emergent cluster patterns effectively by facilitating model adaptation to uncover finer-grained features dynamically.
Future research can investigate scaling the self-guided masking strategy across diverse transformer architectures and more expansive unlabeled datasets. Additionally, integrating systematic patch relevance quantifiers and adaptively evolving masking strategies could further optimize learning outcomes.
Conclusion
The "Self-Guided Masked Autoencoder" ushers in a transformative methodology within the field of self-supervised vision models. Its formulation of an intrinsic, adaptive informed masking protocol without external dependencies represents a significant advancement. This paradigm not only accelerates learning processes but paves the way for developing even more efficient and autonomous machine learning systems. The presented results and methodologies lay a robust foundation for future exploration into self-supervised image processing techniques.