SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
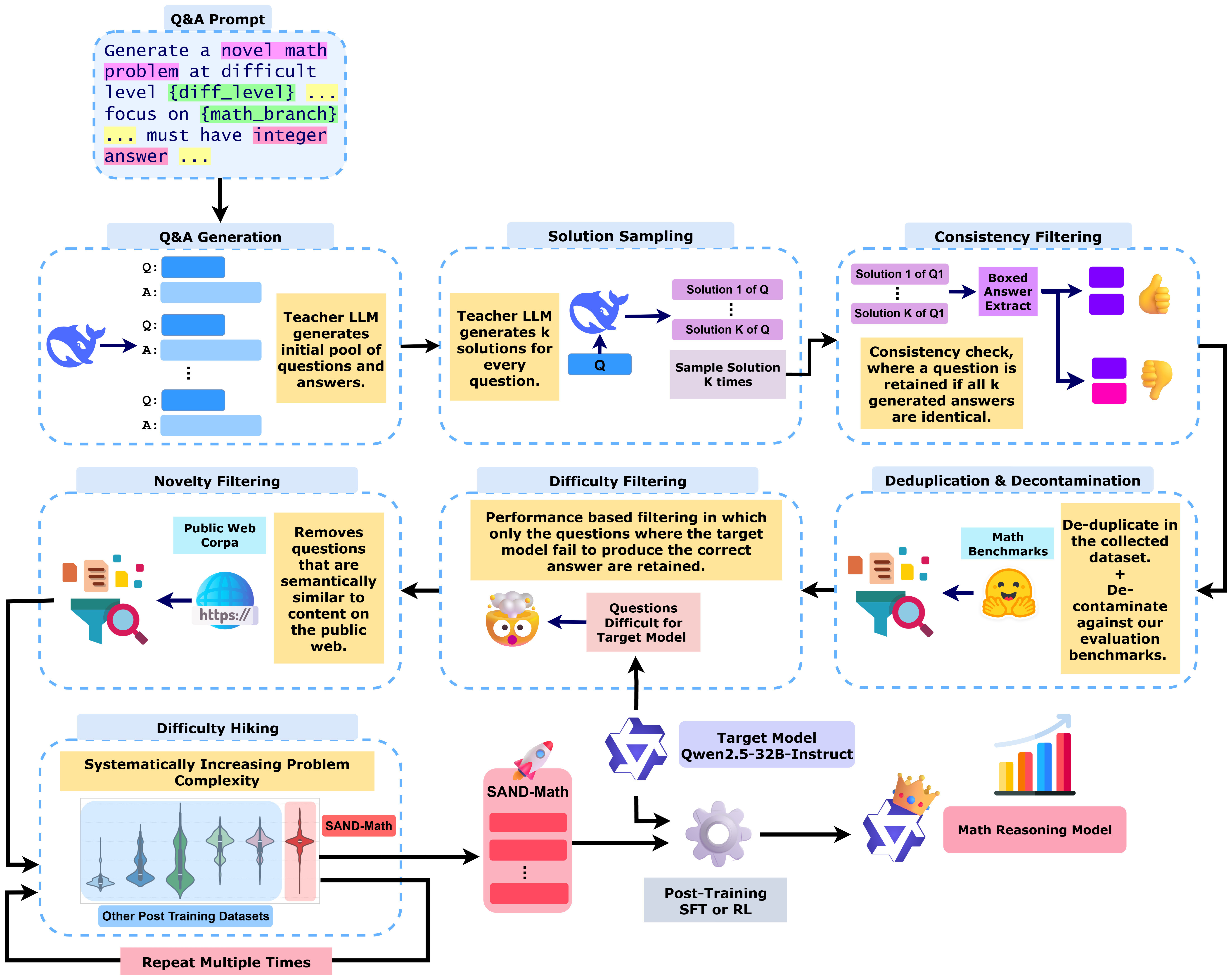
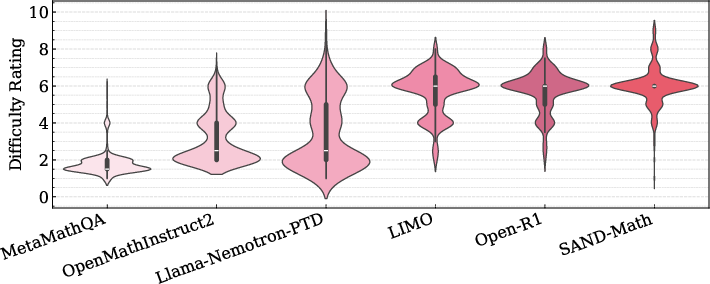
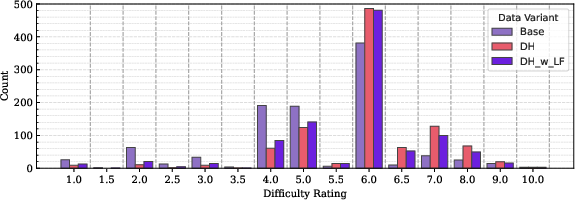
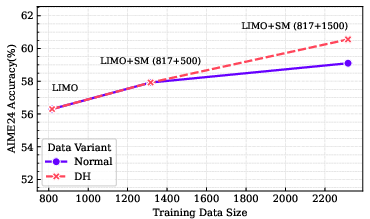
Abstract: The demand for LLMs capable of sophisticated mathematical reasoning is growing across industries. However, the development of performant mathematical LLMs is critically bottlenecked by the scarcity of difficult, novel training data. We introduce \textbf{SAND-Math} (Synthetic Augmented Novel and Difficult Mathematics problems and solutions), a pipeline that addresses this by first generating high-quality problems from scratch and then systematically elevating their complexity via a new \textbf{Difficulty Hiking} step. We demonstrate the effectiveness of our approach through two key findings. First, augmenting a strong baseline with SAND-Math data significantly boosts performance, outperforming the next-best synthetic dataset by \textbf{$\uparrow$ 17.85 absolute points} on the AIME25 benchmark. Second, in a dedicated ablation study, we show our Difficulty Hiking process is highly effective: by increasing average problem difficulty from 5.02 to 5.98, this step lifts AIME25 performance from 46.38\% to 49.23\%. The full generation pipeline, final dataset, and a fine-tuned model form a practical and scalable toolkit for building more capable and efficient mathematical reasoning LLMs. SAND-Math dataset is released here: \href{https://huggingface.co/datasets/amd/SAND-MATH}{https://huggingface.co/datasets/amd/SAND-MATH}
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

