- The paper provides a comprehensive survey on integrating pretrained language models with general-purpose text embeddings, highlighting key architectural paradigms and training strategies.
- It details the use of contrastive learning and advanced pooling methods, showcasing improvements in multilingual, multimodal, and code domains.
- The survey identifies emerging challenges such as safety, bias, and reasoning capabilities while proposing future directions for unified embedding frameworks.
The Role of Pretrained LLMs in General-Purpose Text Embeddings
Introduction
The survey "On The Role of Pretrained LLMs in General-Purpose Text Embeddings: A Survey" (2507.20783) provides a comprehensive and technically rigorous overview of the evolution, architecture, and future directions of general-purpose text embeddings (GPTE) in the context of pretrained LLMs (PLMs). The work systematically dissects the fundamental and advanced roles of PLMs in GPTE, covering architectural paradigms, training strategies, data curation, evaluation, and the extension of embeddings to multilingual, multimodal, and code domains. The survey also addresses emerging challenges such as safety, bias, and the integration of structural and reasoning capabilities.
Foundations of GPTE and PLM Integration
GPTE models encode variable-length text into dense, fixed-size vectors, enabling efficient computation of semantic similarity, relevance, and high-level feature extraction for downstream NLP tasks. The advent of PLMs—initially encoder-based (e.g., BERT), then encoder-decoder (e.g., T5), and more recently decoder-only LLMs (e.g., GPT, Qwen, Mistral)—has fundamentally transformed the landscape of text embeddings. The survey emphasizes that the core architecture of GPTE remains a multi-stage pipeline: initialization with a PLM backbone, unsupervised or weakly supervised pretraining (often via contrastive learning), and optional task-specific supervised fine-tuning.
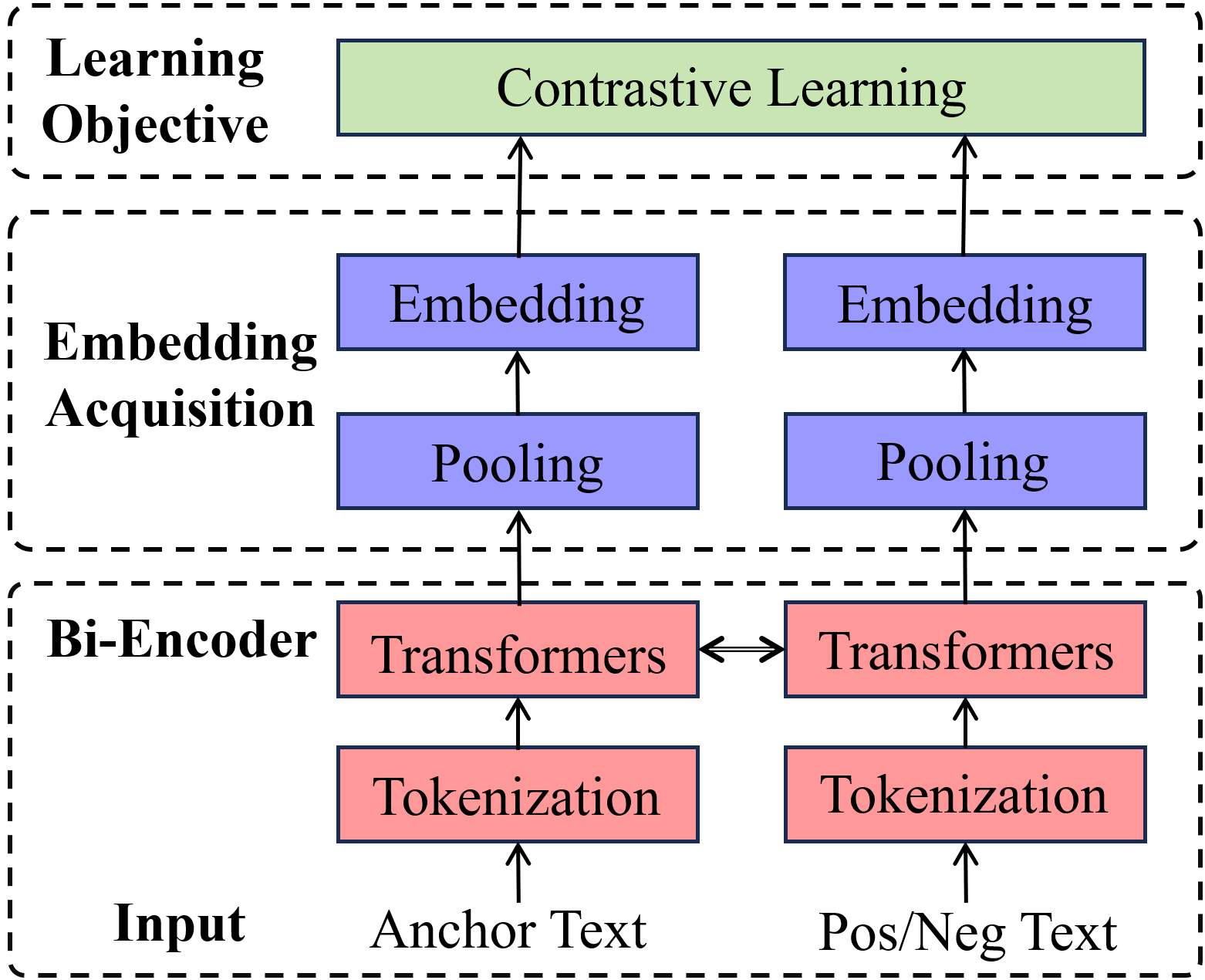
Figure 1: The typical architecture and training manner of GPTE models.
The figure above encapsulates the mainstream GPTE workflow: input text is tokenized and processed by a transformer-based PLM, followed by pooling (e.g., mean, max, or attentive pooling) to obtain a single vector representation. Contrastive learning (CL) is the dominant optimization paradigm, leveraging positive and negative text pairs to shape the embedding space.
Embedding Extraction and Expressivity
The survey details the nuances of embedding extraction across PLM architectures:
- Encoder-based PLMs: Typically use the [CLS] token or mean pooling over token representations. Multi-layer aggregation (e.g., top-K layers) and attentive pooling are employed to enhance robustness.
- Encoder-decoder PLMs: Pooling is performed on the encoder output, with some studies leveraging the decoder's start token.
- Decoder-only LLMs: Last-token pooling is standard due to the causal attention mechanism, but partial pooling (averaging over the tail segment) and prompt-based strategies (e.g., repetition or chain-of-thought prompts) are increasingly adopted to capture richer semantics.
The survey highlights that prompt-informed embedding and instruction-following paradigms, especially in LLMs, have led to significant improvements in embedding quality and task adaptability.
Optimization Strategies and Data Synthesis
Parameter optimization in GPTE has evolved from direct use of PLM parameters to sophisticated multi-stage training pipelines. Weakly supervised pre-finetuning on massive, noisy corpora is followed by fine-tuning on high-quality, task-specific datasets. The survey underscores the importance of large batch sizes in CL, the use of in-batch negatives, and the adoption of advanced objectives beyond standard CL, such as Matryoshka Representation Learning (MRL), angle-based losses, and knowledge distillation from cross-encoder teachers.
A notable trend is the use of LLMs for synthetic data generation, which enables scalable, diverse, and high-quality training data for both monolingual and multilingual GPTE. The survey documents the proliferation of LLM-synthesized datasets for anchor, positive, and hard negative pairs, which are now central to state-of-the-art embedding model training.
Evaluation and Model Selection
The evaluation of GPTE models has converged on unified benchmarks such as MTEB and MMTEB, which encompass a wide array of tasks, languages, and domains. The survey provides a comparative analysis of encoder-only and decoder-only architectures, noting that decoder-based models achieve top-tier performance at larger scales but are more resource-intensive. Mixture-of-Experts (MoE) architectures are identified as a promising direction for efficient scaling.
Advanced Roles: Multilingual, Multimodal, and Code Embeddings
Multilingual Embeddings
The integration of multilingual PLMs (e.g., mBERT, XLM-R) and the use of cross-lingual CL objectives have enabled robust multilingual GPTE. The survey catalogs a diverse ecosystem of multilingual embedding models and datasets, emphasizing the role of synthetic data and cross-lingual transfer in low-resource settings.
Multimodal Embeddings
The survey traces the evolution from dual-encoder models (e.g., CLIP, BLIP) to unified PLM-based multimodal embeddings that support text, image, and video modalities. Instruction-following and cross-modal alignment, powered by PLMs, have led to significant advances in universal multimodal retrieval and representation.
Code Embeddings
PLM-based code embeddings leverage both textual and structural information (e.g., ASTs, data flow graphs) and employ CL on code-code and code-text pairs. The methodology for code embedding closely mirrors that of textual GPTE, with adaptations for the unique properties of programming languages.
Scenario-Specific Adaptation and Emerging Challenges
The survey discusses adaptation strategies for specific tasks, languages, and domains, including the use of LoRA adapters and instruction-tuning. It also addresses critical challenges:
- Safety: GPTE models are vulnerable to backdoor attacks and privacy leakage via embedding inversion. The survey documents concrete attack vectors and underscores the need for robust defense mechanisms.
- Bias: Task, domain, language, and social biases are pervasive in GPTE, stemming from imbalanced training data and societal stereotypes. The survey calls for systematic bias identification, mitigation, and evaluation.
- Structural Information: Current GPTE models underutilize long-range and hierarchical structural information, which is essential for comprehensive document understanding and complex reasoning.
- Reasoning and Cognitive Alignment: The integration of GPTE with reasoning-capable LLMs is proposed as a path toward explainable, robust, and context-aware embeddings, drawing analogies to memory systems in cognitive neuroscience.
Future Directions
The survey identifies several underexplored but high-impact research avenues:
- Unified embedding and ranking frameworks that bridge the gap between bi-encoder efficiency and cross-encoder expressivity.
- Safety and privacy-preserving embeddings with formal guarantees against inversion and backdoor attacks.
- Bias mitigation through task-diverse pretraining, domain adaptation, and fairness-aware objectives.
- Structure-informed embeddings that capture global document coherence and support graph- or chain-based contrastive learning.
- Embedding-reasoning integration for dynamic, interpretable, and memory-augmented representations.
Conclusion
This survey provides a technically detailed and comprehensive roadmap of GPTE in the PLM era, elucidating the architectural, algorithmic, and data-centric advances that have shaped the field. By systematically analyzing the roles of PLMs in embedding extraction, optimization, and application, the work offers actionable insights for both foundational research and practical deployment. The outlined challenges and future directions highlight the need for continued innovation in safety, bias mitigation, structural modeling, and the integration of reasoning capabilities, which will be critical for the next generation of universal embedding models.