- The paper introduces an innovative framework leveraging multiple adversarially trained teacher models to enhance CNN robustness without direct adversarial training.
- It employs an adaptive learning strategy that dynamically weights teacher contributions using cosine similarity between logits.
- Experimental results on MNIST-Digits and MNIST-Fashion show superior accuracy and reduced computational cost compared to traditional methods.
Improving Adversarial Robustness Through Adaptive Learning-Driven Multi-Teacher Knowledge Distillation
The paper "Improving Adversarial Robustness Through Adaptive Learning-Driven Multi-Teacher Knowledge Distillation" introduces an innovative approach to enhancing the adversarial robustness of convolutional neural networks (CNNs) without requiring exposure to adversarially perturbed data during training. The authors present a framework that leverages multiple adversarially trained teacher models to supervise a student model, employing an adaptive learning strategy that dynamically weights the contribution of each teacher based on its prediction performance.
Background and Motivation
CNNs are highly effective in computer vision but vulnerable to adversarial attacks, which involve slight perturbations designed to mislead network predictions. Traditional adversarial training techniques involve augmenting the training set with adversarial examples, improving robustness but with significant computational costs. Knowledge distillation, typically from a single teacher model, offers an alternative by transferring robustness to smaller models. However, the limitations of single-teacher paradigms include a lack of generalization across diverse attack types.
Approach
The proposed framework, named MTKD-AR, introduces:
- Multi-Teacher Knowledge Distillation: Multiple adversarially trained teacher models are employed to transfer robustness to a single student model trained exclusively on clean data. Each teacher is trained using an adversarial strategy against different types of attacks, such as FGSM, FFGSM, RFGSM, and PGD.
- Adaptive Learning Strategy: The framework incorporates an adaptive learning mechanism, assigning dynamic importance weights to each teacher based on its prediction precision for given inputs. This ensures effective knowledge transfer prioritizing more reliable teachers, improving the student's resilience against adversarial attacks.
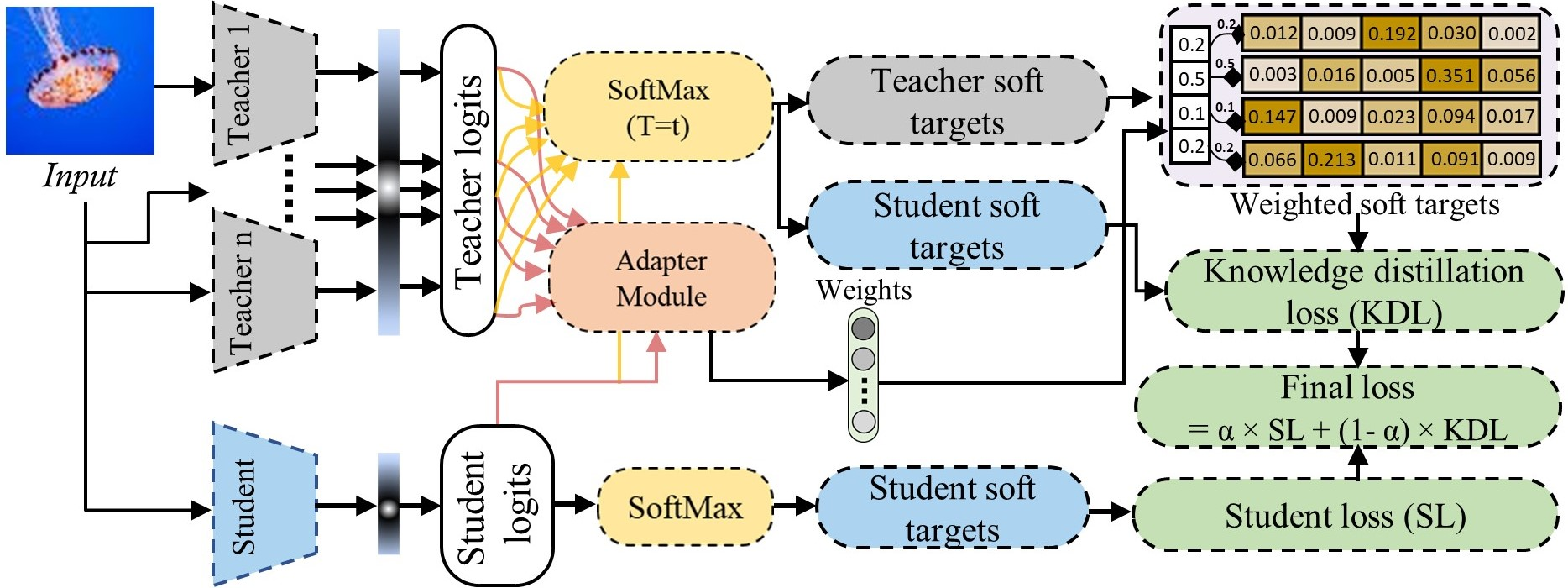
Figure 1: The brief visual overview and workflow of our proposed MTKD-AR method.
Implementation Details
The process begins with adversarial training of multiple clones of a baseline CNN model using various attack strategies. Once these models are trained, they serve as teacher models governing the student's learning through knowledge distillation on clean data. The student receives weighted predictions, calculated using cosine similarity between teacher and student logits. The integration of distillation loss and the standard supervised loss ensures effective knowledge transfer without exposure to adversarial data.
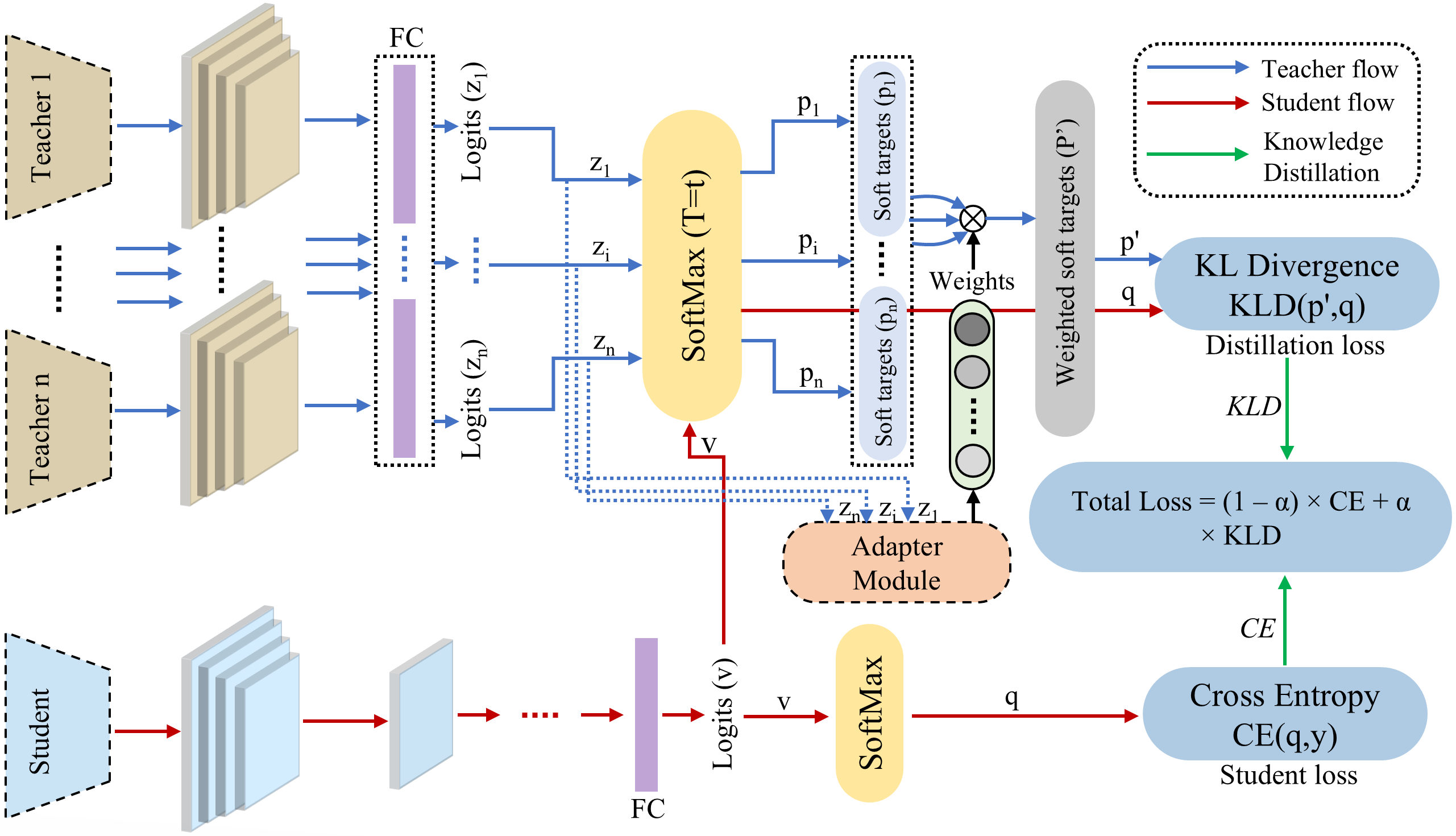
Figure 2: Detailed graphical overview of our proposed framework, depicting the overall workflow of adaptive learning-driven multi-teacher knowledge distillation for improving model robustness against adversarial attacks.
Experimental Evaluation
The authors evaluated MTKD-AR using the MNIST-Digits and MNIST-Fashion datasets under various adversarial settings with perturbation magnitudes such as ϵ = 0.1, 0.2, and 0.3. Results consistently demonstrated MTKD-AR's superior performance in terms of accuracy across different attack types compared to single-teacher and baseline models. Notably, the student model trained through MTKD-AR achieved high robustness without direct exposure to adversarial data.
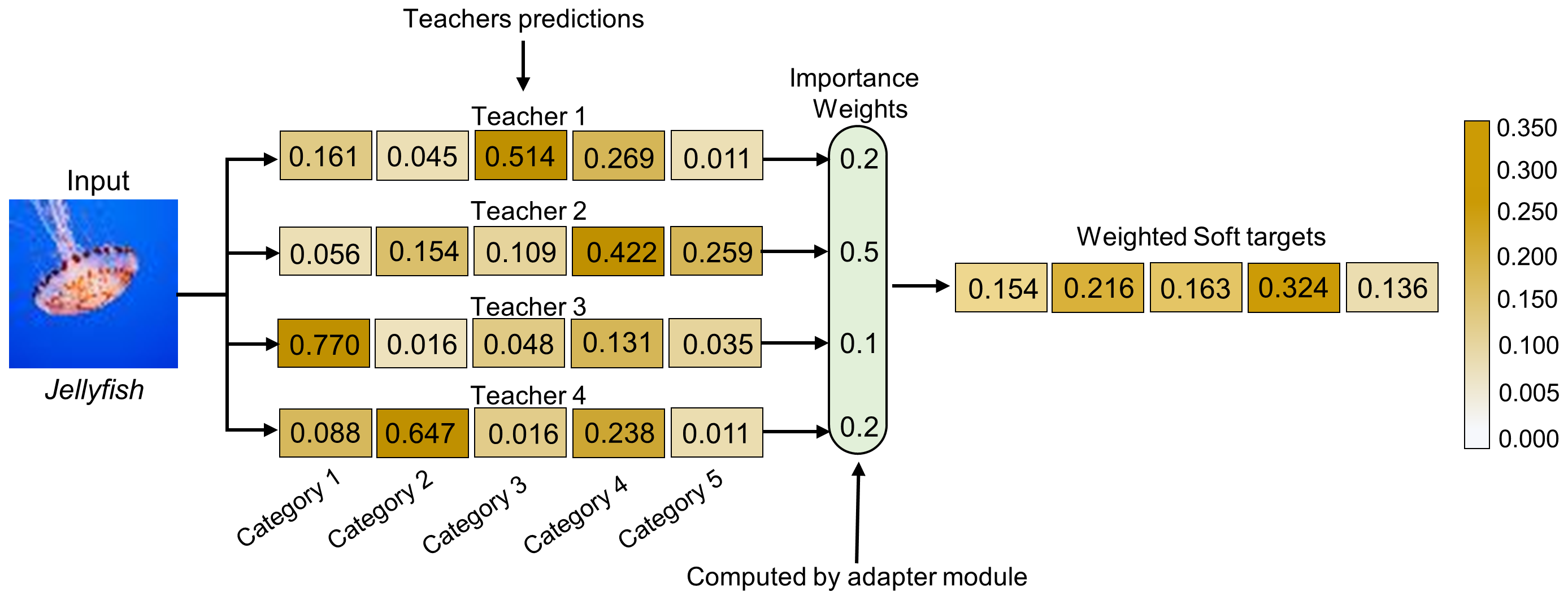
Figure 3: Pictorial overview of the proposed adaptive learning mechanism for multi-teacher knowledge distillation.
Conclusion
The MTKD-AR framework offers a novel method for mitigating adversarial vulnerabilities in CNNs, significantly reducing computational costs and enhancing adaptability to diverse attack scenarios. By leveraging multiple adversarially trained teacher models and employing an adaptive learning mechanism, MTKD-AR outperforms existing adversarial training and knowledge distillation methods, showcasing improved generalization and resilience. Future research may explore extending adaptive learning strategies to other domains, such as NLP and transformer-based models, and integrating certified defenses for enhanced security in AI systems. The versatile and scalable nature of MTKD-AR positions it as a robust defense mechanism ideal for various practical applications across different industries.