- The paper introduces Reinforcement Learning with Performance Feedback (RLPF) that leverages CTR as a reward, achieving a 6.7% advertiser-level CTR improvement over a supervised baseline.
- It employs a large-scale A/B test with nearly 35,000 advertisers and 640,000 ad variations to rigorously validate the impact of RL-based post-training on generative ad text.
- The study demonstrates that RL-enhanced ad text generation can increase both advertiser engagement and the number of ad variations, highlighting significant economic benefits in digital advertising.
Reinforcement Learning with Performance Feedback for Generative Ad Text: An Analysis of AdLlama
Introduction
This paper presents a rigorous empirical study of reinforcement learning (RL) for post-training LLMs in a high-stakes, real-world setting: generative ad text creation on Facebook. The authors introduce Reinforcement Learning with Performance Feedback (RLPF), a post-training paradigm that leverages aggregate, objective performance metrics—specifically, click-through rate (CTR)—as the reward signal for RL alignment. The resulting model, AdLlama, is evaluated in a large-scale A/B test involving nearly 35,000 advertisers and 640,000 ad variations, demonstrating a statistically significant 6.7% increase in advertiser-level CTR over a strong supervised imitation baseline. This work provides a rare, large-scale quantification of the economic impact of RL-based post-training for LLMs in an ecologically valid deployment.
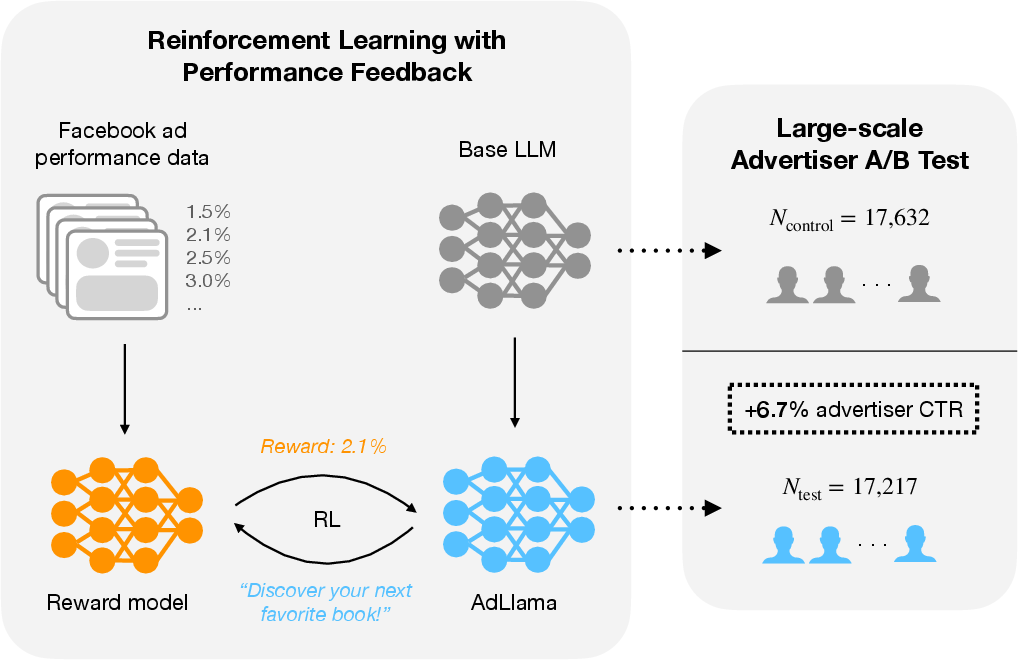
Figure 1: Overview of the RLPF approach and large-scale A/B test, showing both the RL-based post-training pipeline and the observed 6.7% CTR lift for AdLlama.
Meta's Text Generation Product and Baseline Models
Meta's Text Generation product, integrated into Ads Manager, enables advertisers to generate multiple ad text variations from a single human-written input. The interface allows advertisers to select, edit, or ignore AI-generated suggestions, with a cap of five variations per ad.
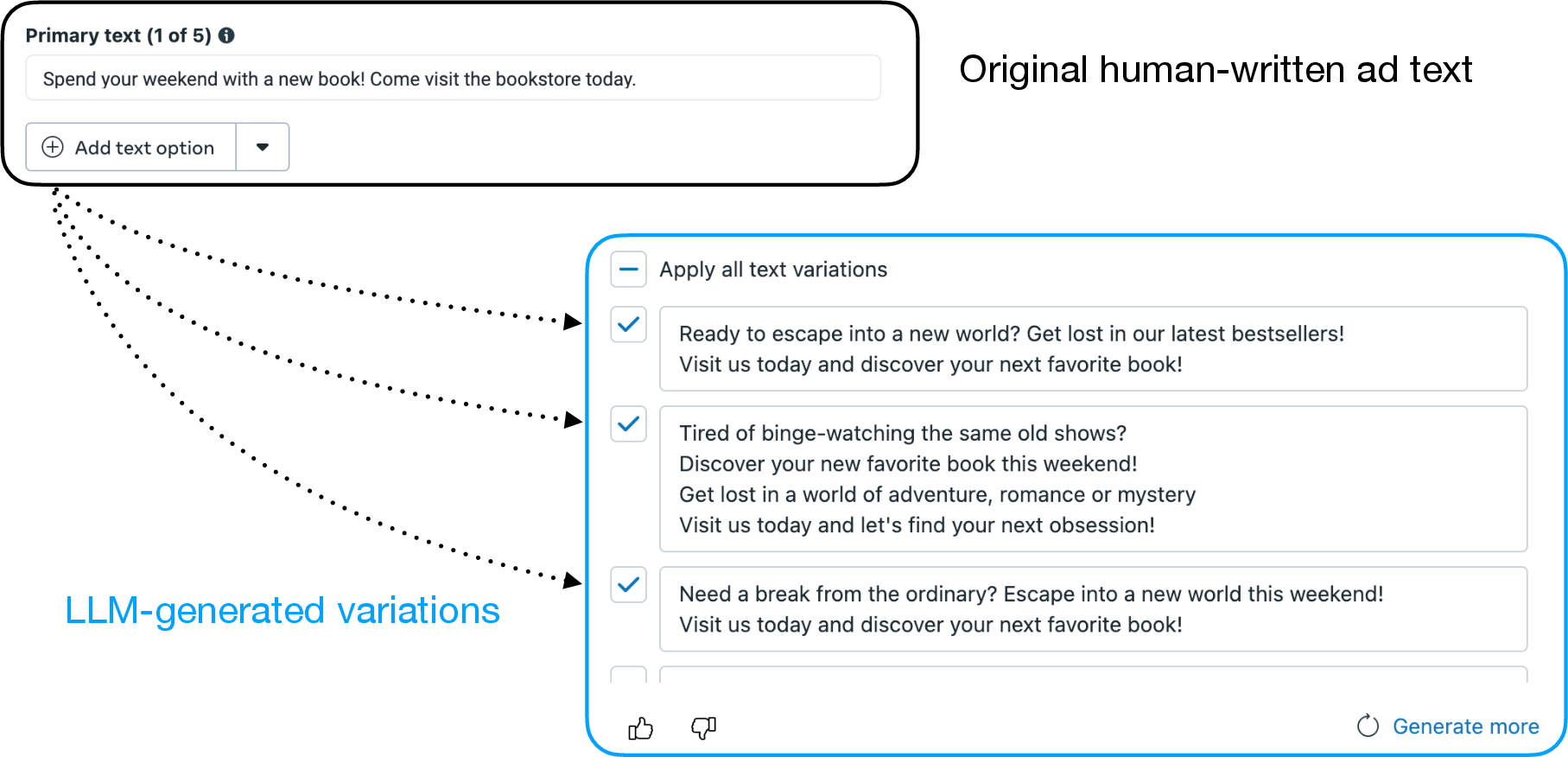
Figure 2: The user interface for Meta's Text Generation product, illustrating the workflow for generating and selecting ad text variations.
The initial deployed model, Imitation LLM v1, was a 7B Llama 2 Chat model fine-tuned via supervised learning (SFT) to imitate curated ad text, primarily using synthetic data. Imitation LLM v2 improved upon this by incorporating both synthetic and human-written rewrites, but still relied solely on SFT, without explicit optimization for downstream performance metrics.
Reward Model Construction
The core innovation is the use of aggregate, verifiable performance data—CTR—as the reward signal for RL. The authors exploit historical multitext ad data, where only the body text varies across otherwise identical ads, to construct pairwise preference datasets. Each pair is labeled according to which text achieved higher CTR, enabling robust, scalable reward modeling.
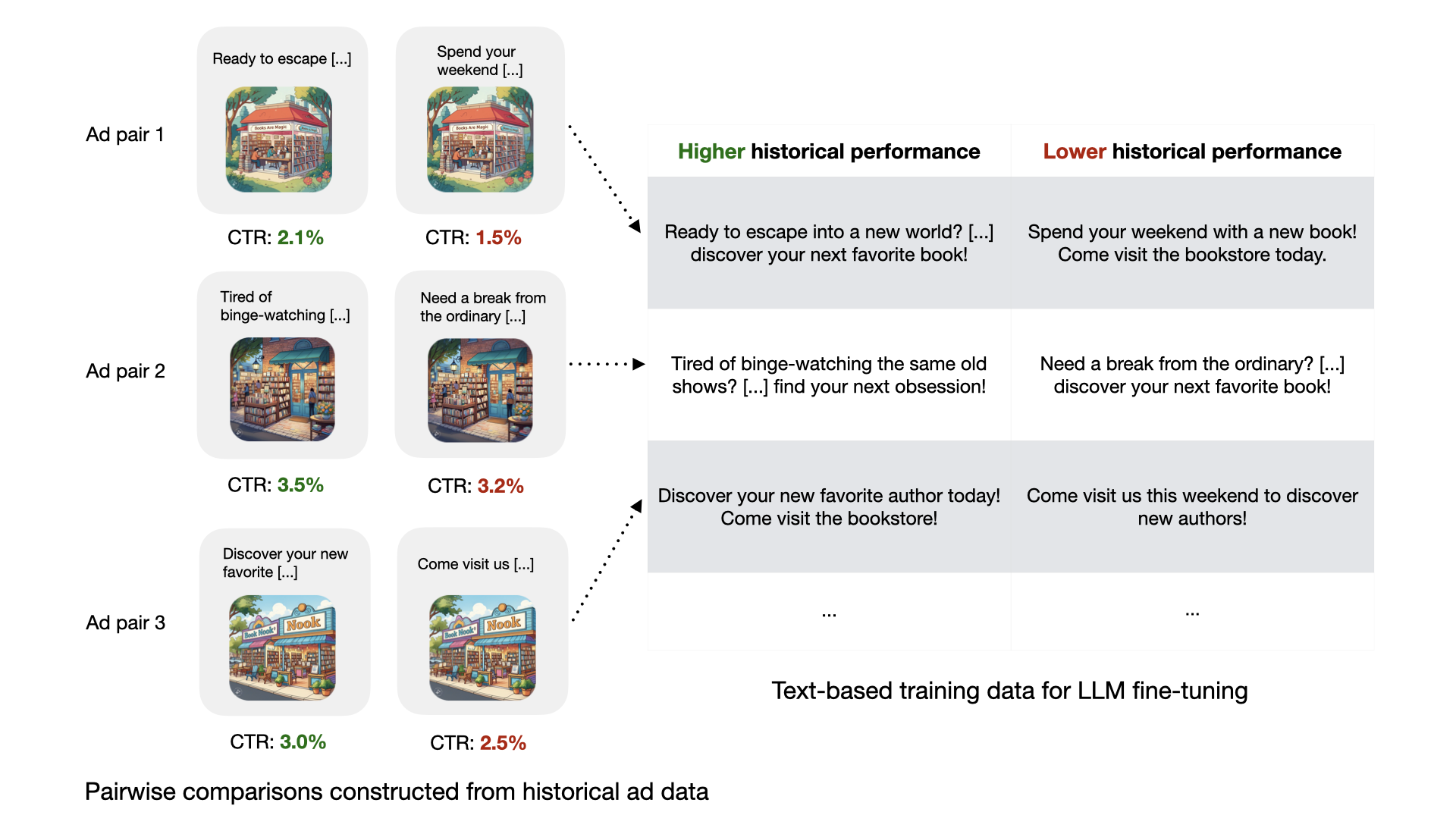
Figure 3: Construction of pairwise training data from multitext ad performance, isolating the effect of body text on CTR.
A reward model is trained using a Bradley-Terry preference framework, optimizing the likelihood that the model assigns higher scores to higher-CTR text in each pair. The final reward model achieves 57% out-of-sample pairwise accuracy, indicating nontrivial signal in the data.
RL Fine-Tuning
The LLM is then post-trained using Proximal Policy Optimization (PPO), with the reward model serving as the environment. The objective is to maximize expected reward (predicted CTR), regularized by a KL penalty to the reference policy and a length penalty to discourage verbose generations:
πϕmaxEx,y∼πϕ[rθ(x,y)−βKL(πϕ(⋅∣x),πref(⋅∣x))−αlength(y)]
Careful checkpoint selection is required to avoid reward hacking and degradation of subjective text quality, using both an evaluation reward model and small-scale human preference labeling.
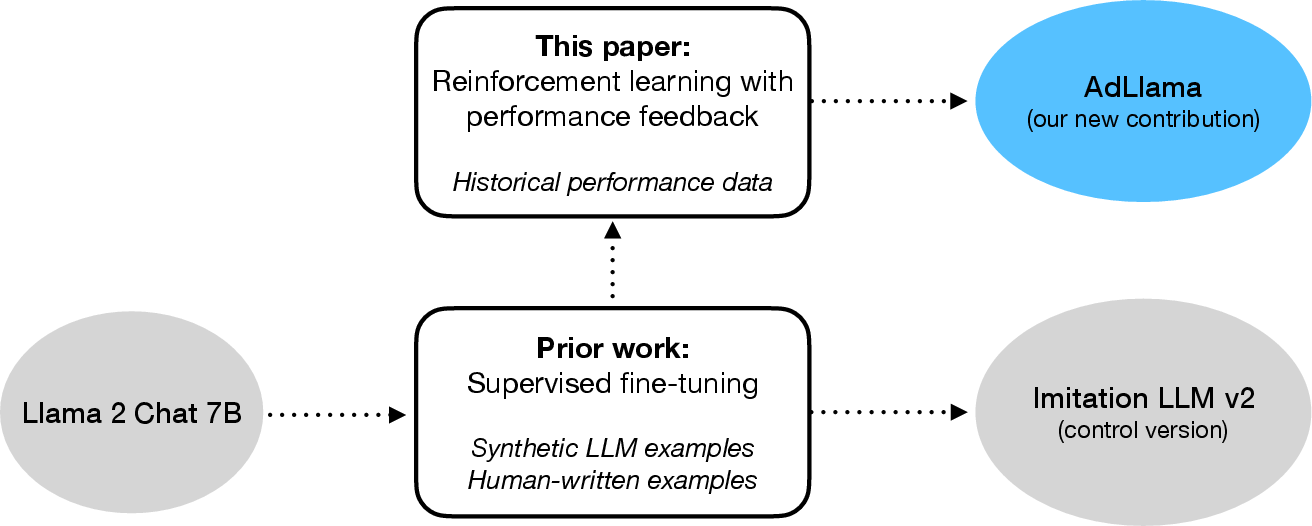
Figure 4: Comparison of AdLlama (RLPF-trained) and Imitation LLM v2 (SFT-trained), both initialized from Llama 2 Chat 7B.
Experimental Design
A 10-week, advertiser-level randomized controlled trial was conducted in the US, with 34,849 advertisers assigned to either AdLlama (RLPF) or Imitation LLM v2 (SFT). The primary outcome is advertiser-level CTR, aggregated over all direct-response ads during the experiment. Covariates include pre-experiment CTR, advertiser tenure, budget, expertise, and vertical, with no significant imbalances observed between groups.
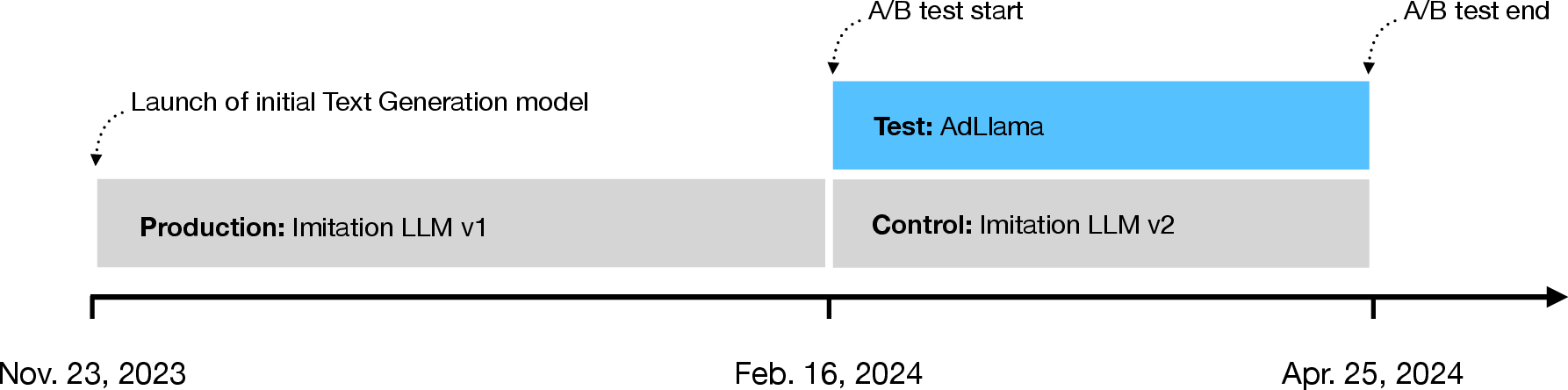
Figure 5: Timeline of the A/B test, contextualizing the deployment of Imitation LLM v1 and the experimental period.
Main Results
CTR Improvement
Log-binomial regression, controlling for covariates, estimates a 6.7% relative increase in advertiser-level CTR for AdLlama over Imitation LLM v2 (p=0.0296). The absolute CTR increases from 3.1% to 3.3%. Model-free, impression-weighted analysis corroborates this result, with a statistically significant difference (p=0.0046).
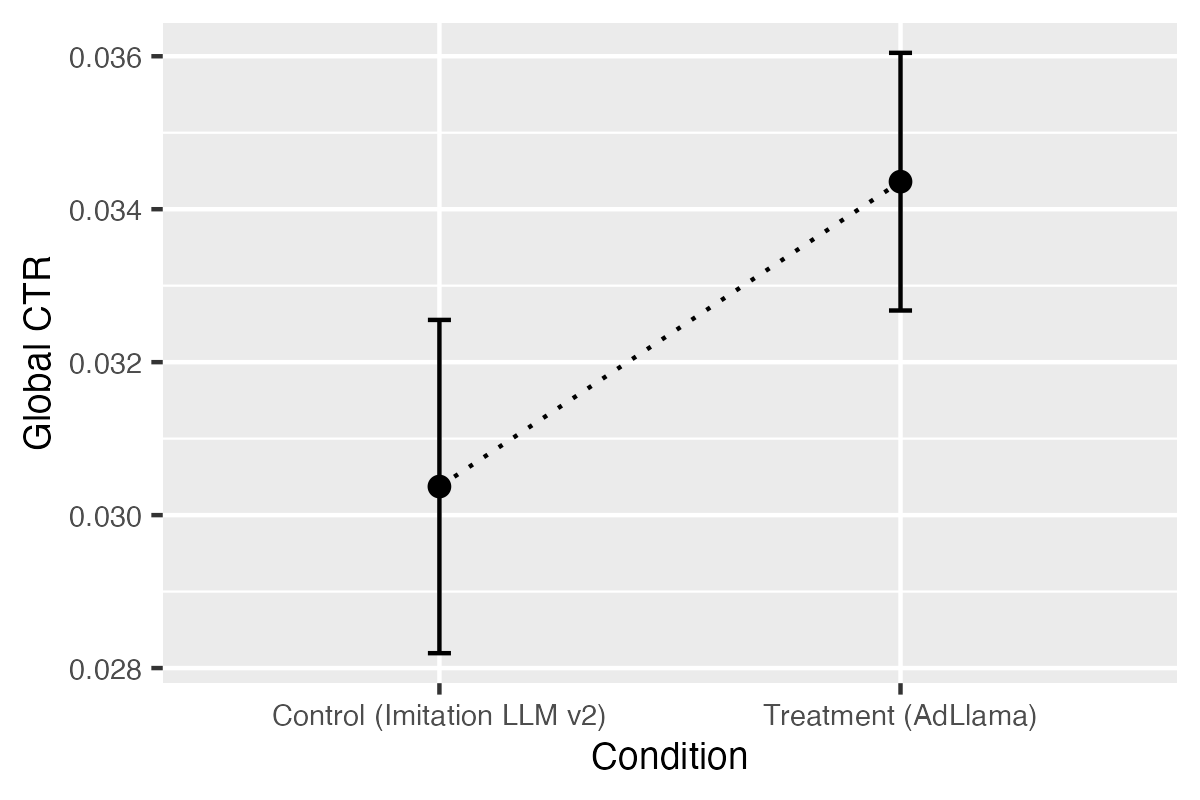
Figure 6: Model-free CTR estimates for control (Imitation LLM v2) and treatment (AdLlama), with 95% confidence intervals.
Robustness checks using alternative regression specifications (logistic, Poisson, quasi-binomial) yield consistent effect sizes. Separate regressions on clicks and impressions confirm that the CTR lift is driven by increased engagement, not increased ad delivery.
Advertiser Behavior
AdLlama also increases the number of ad variations created per advertiser by 18.5% (from 16.8 to 19.9, p<0.01), with no significant change in the number of ads created. This suggests higher advertiser satisfaction and willingness to adopt AI-generated suggestions.
Discussion
Practical Implications
This study provides strong evidence that RL-based post-training with aggregate, objective performance feedback can yield measurable business impact in a mature, highly optimized domain. The magnitude of the CTR lift is substantial in the context of digital advertising, where incremental gains are difficult to achieve at scale. The methodology is generalizable to any domain where aggregate performance metrics are available, including e-commerce, email marketing, and customer support.
Theoretical Implications
RLPF bridges the gap between RLHF (subjective, small-scale human preferences) and RL with verifiable rewards (objective, automatically validated signals). By leveraging large-scale, real-world behavioral data, RLPF enables direct optimization of economically relevant outcomes, moving beyond proxy objectives.
Limitations and Future Directions
- Offline RL: The current approach is equivalent to a single round of offline RL. Iterative, online RL with real-time feedback could further improve adaptation and enable exploration of novel ad formats.
- Multi-objective Optimization: The focus on CTR may trade off against creativity, compliance, or advertiser intent. Future work should incorporate multi-objective reward modeling.
- Advertiser Selection Bias: The reward model does not account for the probability that a generated variation is selected by the advertiser. Incorporating this human-in-the-loop signal could further align model outputs with advertiser preferences.
- Platform-level Effects: The impact on ad diversity and user experience at the platform level remains unexplored.
Conclusion
This work demonstrates that reinforcement learning with aggregate performance feedback is an effective, scalable, and economically meaningful approach for post-training LLMs in real-world applications. The AdLlama deployment provides a rare, large-scale quantification of RL-based LLM alignment in production, with statistically significant improvements in both engagement and advertiser adoption. The RLPF paradigm is broadly applicable to any setting with reliable, aggregate performance metrics, and represents a promising direction for aligning LLMs with real-world objectives.