- The paper introduces MST-KDNet, which utilizes multi-scale transformer knowledge distillation to address challenges posed by missing MRI modalities in brain tumor segmentation.
- It integrates dual-mode logit distillation and a global style matching module to align features and maintain high segmentation accuracy.
- Experiments on the BraTS and FeTS 2024 datasets show significant improvements in Dice and HD95 metrics compared to existing methods.
Bridging the Gap in Missing Modalities: Leveraging Knowledge Distillation and Style Matching for Brain Tumor Segmentation
Introduction
The paper presents MST-KDNet, a novel framework designed to address the challenges of missing modalities in brain tumor segmentation. This issue arises when certain MRI modalities, essential for accurate diagnosis and treatment planning, are unavailable due to technical constraints or varied clinical settings. This work emphasizes the importance of overcoming modality loss to improve segmentation accuracy, which is vital for conditions such as gliomas that exhibit complex biological behaviors.
The authors introduce Multi-Scale Transformer Knowledge Distillation (MS-TKD), Dual-Mode Logit Distillation (DMLD), and a Global Style Matching Module (GSME) as innovations to tackle the segmentation challenges. Each component enhances the model's ability to learn and adapt without relying on all input modalities, thus improving robustness and performance.
Proposed Method
MST-KDNet utilizes MS-TKD to effectively capture cross-resolution attention weights. This technique improves the model's capacity to adapt to incomplete modality inputs by employing a detailed Extreme Value Distillation (EVD) process to handle attention inconsistencies:
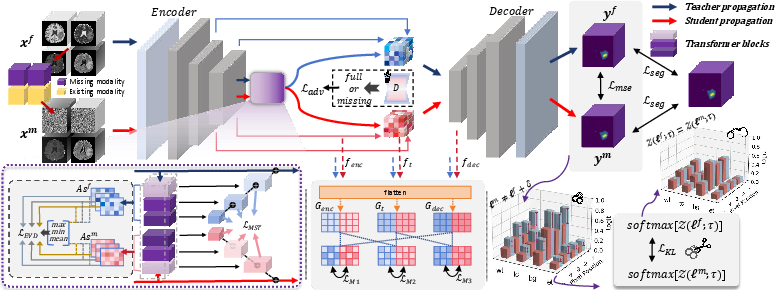
Figure 1: The overall framework of MST-KDNet. The teacher propagation processes all available modalities, while the student propagation accommodates incomplete inputs.
The EVD method calculates attention weights at each pixel position and distills critical information through a multi-scale approach, leveraging mean square error losses for between-model alignment.
Dual-Mode Logit Distillation
DMLD addresses the rigidity of traditional global temperature factors in knowledge distillation. It introduces logit normalization to allow flexible adaptation across varying model capacities, maintaining the core distribution relationship between logits of teacher and student networks. The distillation process combines discrepancy losses with a logit standardization KL loss, effectively bridging magnitude disparities in outputs.
Global Style Matching Module
The GSME tackles modality-induced variances by integrating MSE losses with adversarial learning. Style matching compensates for missing data by aligning available modality features through cross-modal feature fusion operations, aiding in consistent segmentation outputs:
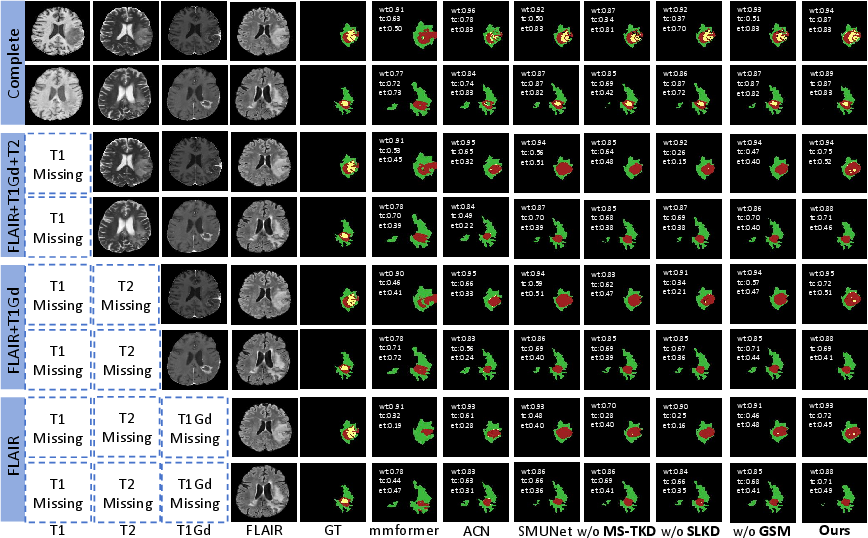
Figure 2: Comparison of segmentation results under four missing-modality scenarios. Color legend: WT = \textcolor[HTML]{9F2020}{red} + \textcolor{yellow}{yellow} + \textcolor[HTML]{3DB83D}{green}, TC = \textcolor[HTML]{9F2020}{red} + \textcolor{yellow}{yellow}, ET = \textcolor[HTML]{9F2020}{red}.
Experiments
Dataset and Implementation
Experiments were performed on the BraTS and FeTS 2024 datasets, which provide comprehensive multimodal MR brain images suitable for evaluating segmentation frameworks. Notably, MST-KDNet demonstrated significant improvements over existing approaches in both Dice and HD95 scores, reflecting enhanced segmentation precision and robustness under missing modality conditions.
Results and Analysis
MST-KDNet outperformed several state-of-the-art models in Dice score and HD95 metrics, highlighting its effectiveness in dealing with missing modalities and maintaining high segmentation accuracy across various combinations of available inputs. The ablation studies further confirmed the complementary roles of MS-TKD, GSME, and SLKD, as the removal of any component resulted in notable performance degradation.
Conclusion
The study successfully presents MST-KDNet as a robust solution for brain tumor segmentation under missing modality scenarios. By employing innovative knowledge distillation and style matching techniques, MST-KDNet achieves superior performance and stability, facilitating its practical application in real-world clinical environments. This opens avenues for further research into adaptive learning and multi-modality integration in medical imaging, ultimately improving diagnostic and therapeutic outcomes. Future enhancements could explore optimization for lower-resource settings or implementations on varying hardware architectures.