- The paper introduces the KCR framework that enhances LLM reasoning by resolving both context-memory and inter-context conflicts in long inputs.
- It employs a two-phase methodology: generating structured reasoning paths and applying reinforcement learning with verifiable rewards to align correct logic.
- Experimental results show improved consistency, reduced hallucinations, and notable performance gains in handling long-context scenarios.
Resolving Long-Context Knowledge Conflicts via Reasoning in LLMs
Long-context knowledge conflicts present a significant challenge in the field of LLMs. These models are often overwhelmed by lengthy and contradictory contexts, leading to confusion and potential errors in output. The paper "KCR: Resolving Long-Context Knowledge Conflicts via Reasoning in LLMs" (2508.01273) introduces the Knowledge Conflict Reasoning (KCR) framework, designed to address these challenges by enhancing the reasoning capabilities of LLMs.
Introduction to Knowledge Conflicts
Knowledge conflicts in LLMs are broadly classified into two categories: Context-Memory Conflicts and Inter-Context Conflicts. Context-memory conflicts arise from discrepancies between external contextual information and the model's internal parametric knowledge, while inter-context conflicts occur when multiple contextual sources contradict each other. The paper highlights that inter-context conflicts become particularly challenging in long-context scenarios, where extended inputs increase the likelihood of mutually incompatible statements. Existing methods that rely on decoders to fuse conflicting information have proven insufficient, particularly in long-context scenarios, due to altered word distributions and degraded performance.
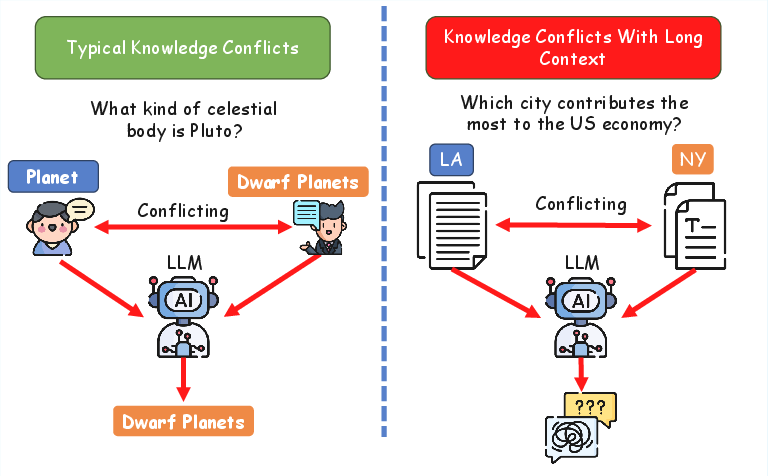
Figure 1: An illustrative example to demonstrate the struggle of LLMs directly address long-context knowledge conflicts.
The Knowledge Conflict Reasoning Framework
The KCR framework operates in two main phases: Conflicting Reasoning Paths Generation and Conflicts Reasoning Paradigm Learning.
Conflicting Reasoning Paths Generation
This phase involves extracting reasoning paths from conflicting long-context answers using both structured and unstructured formats. Key entities and relations are extracted from the query text to capture its semantics. For unstructured contexts, reasoning paths are constructed from the text, with token sequences representing entities and relations. In structured contexts, local knowledge graphs are constructed to encode structured knowledge, allowing for scalable reasoning without context length limitations.
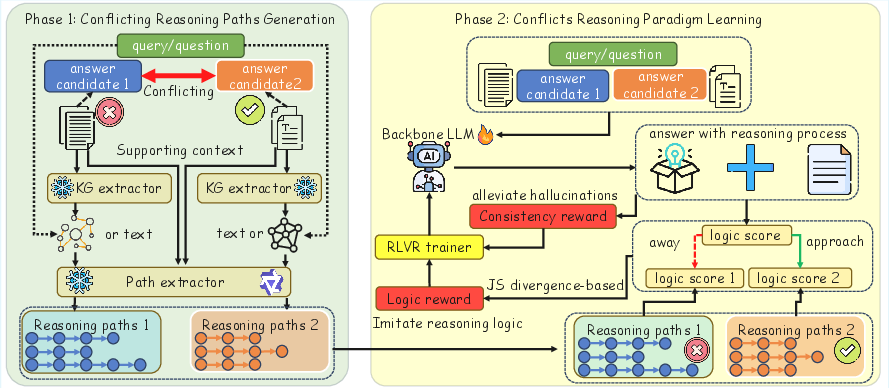
Figure 2: The overall framework of our method KCR.
Conflicts Reasoning Paradigm Learning
The second phase aims to enhance the reasoning ability of the backbone LLM using Reinforcement Learning with Verifiable Rewards (RLVR). This involves training the model to imitate the reasoning logic of a potentially correct candidate while maintaining consistency. Logic scores are computed for candidate answers and the backbone LLM's reasoning output, guiding the model to align with correct logic and diverge from incorrect logic. Consistency constraints further ensure the output remains coherent, mitigating hallucinations and improving reliability.
Experimental Evaluation
The KCR framework was evaluated on datasets specifically designed for long-context knowledge conflicts, demonstrating substantial improvements. For example, models equipped with KCR outperformed their original counterparts, suggesting enhanced reasoning abilities. Key innovations include structuring information into reasoning paths to prevent models from getting lost in long contexts and reducing hallucinations through consistency constraints.
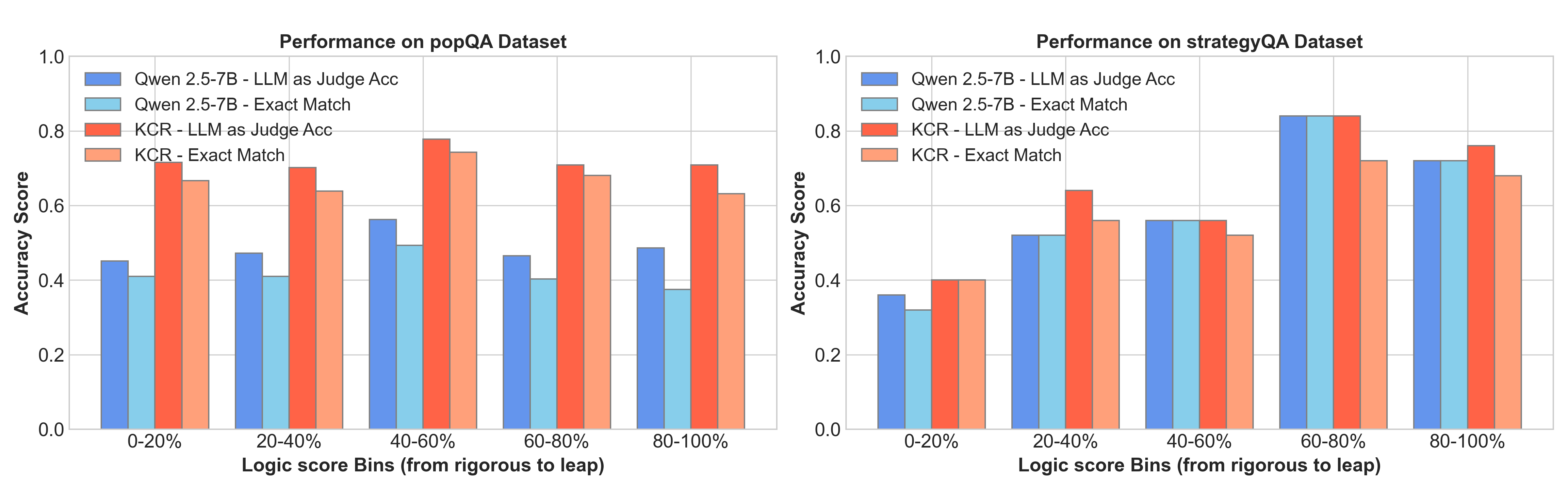
Figure 3: Analysis of reasoning logic across varying rigor levels.
Multilingual Spillover and Further Case Study
An intriguing phenomenon observed in experiments was the multilingual reasoning spillover in larger model variants, leading to performance degradation due to evaluations being strictly in English. The KCR framework effectively mitigated this by enforcing structured reasoning processes, preserving linguistic consistency and enhancing evaluation accuracy.
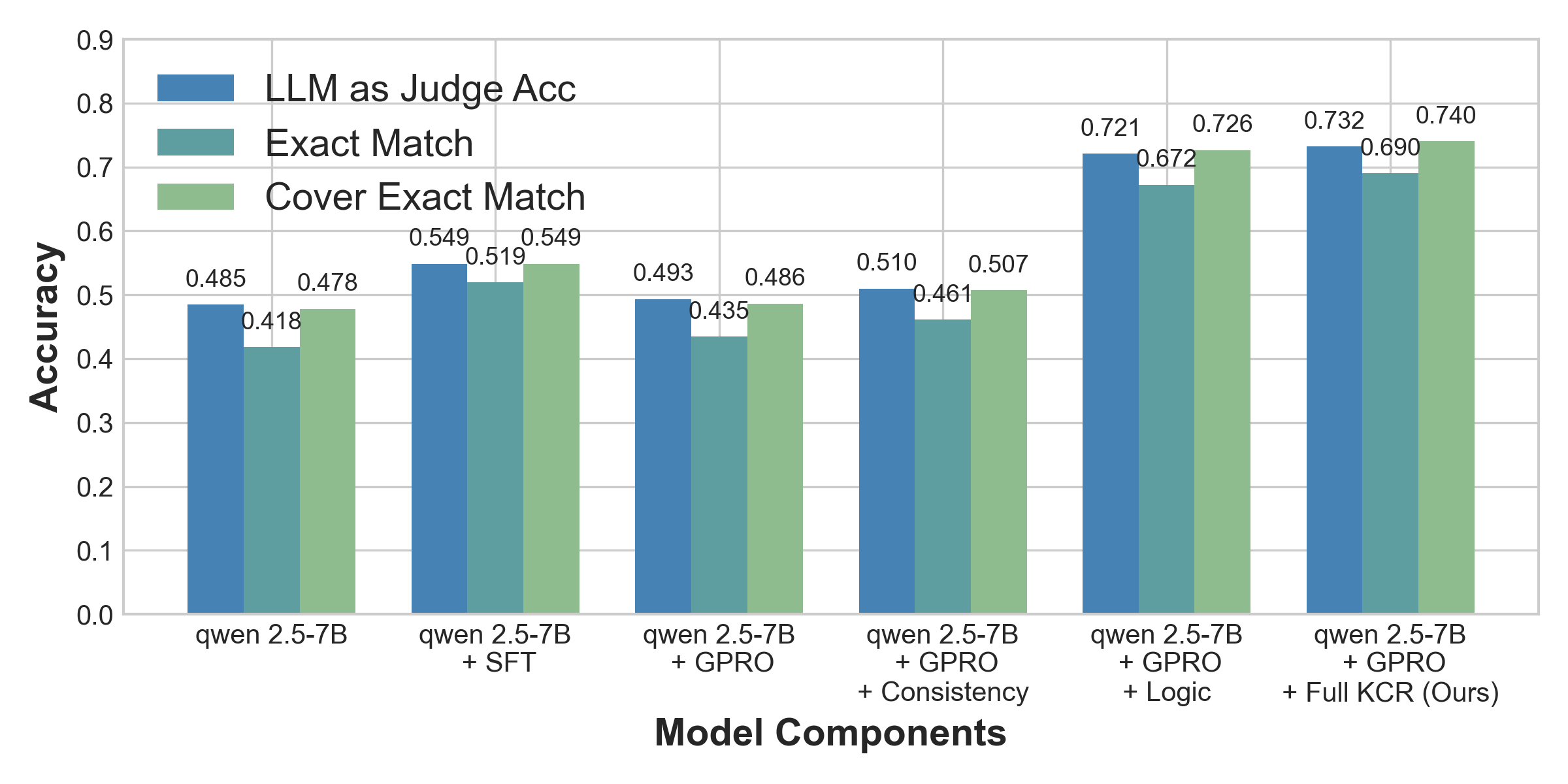
Figure 4: Analysis of fine-tuning approaches across varying rigor levels.
Conclusion
The KCR framework presents a novel approach to resolving inter-context knowledge conflicts in LLMs, offering significant improvements in reasoning and output consistency. By structuring information and reinforcing correct reasoning paradigms, KCR sets a new standard for handling long-context scenarios, mitigating hallucinations, and enhancing backbone models' performance across diverse tasks.
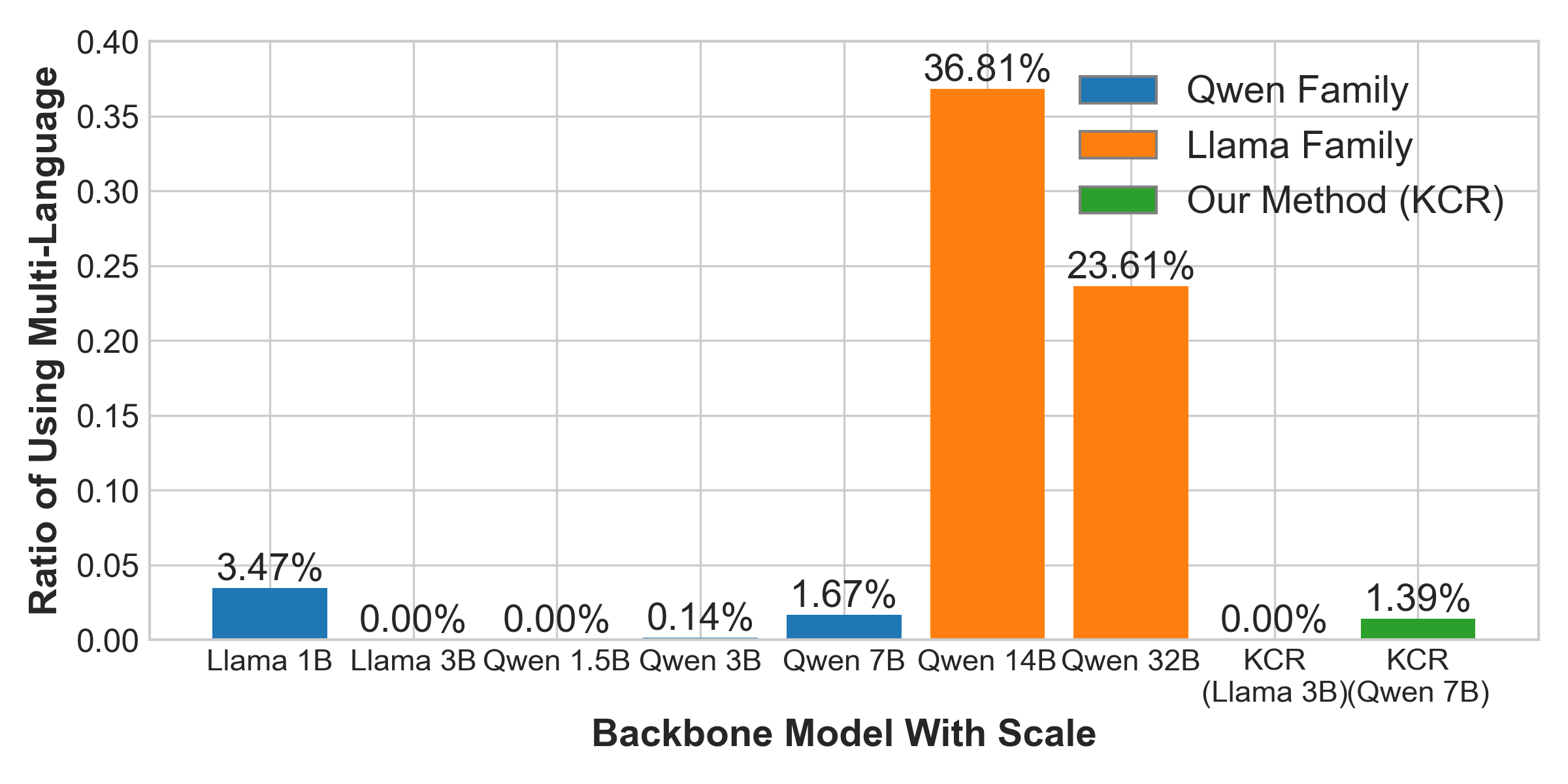
Figure 5: Analysis of reasoning logic with varying degrees of rigorous.
The paper contributes to deepening the understanding of LLMs' behavior in the face of complex knowledge conflicts and offers practical solutions for improving their reliability and efficiency.