- The paper introduces a variational flow-matching policy (VFP) that leverages a variational latent prior to overcome mode averaging in multi-modal robot manipulation tasks.
- It employs Kantorovich Optimal Transport regularization to align predicted actions with expert demonstrations, ensuring diverse action trajectories.
- The Mixture-of-Experts flow decoder enhances sampling efficiency and achieves up to 11.5% improvement over state-of-the-art methods in both simulated and real-world settings.
Variational Flow-Matching Policy for Multi-Modal Robot Manipulation
Introduction and Background
The paper "VFP: Variational Flow-Matching Policy for Multi-Modal Robot Manipulation" (2508.01622) introduces a novel approach to the challenge of learning-based robot manipulation with multi-modal capabilities. Traditional flow-matching policies have been hindered by their inability to effectively capture and execute diverse action trajectories inherent in complex manipulation tasks, predominantly due to their tendency to average over modalities, resulting in non-optimal behavior. This research addresses these limitations by proposing a Variational Flow-Matching Policy (VFP), which integrates a variational latent prior, Kantorovich Optimal Transport (K-OT) regularization, and a Mixture-of-Experts (MoE) flow decoder to enhance both the policy's multi-modal representation and its sampling efficiency.
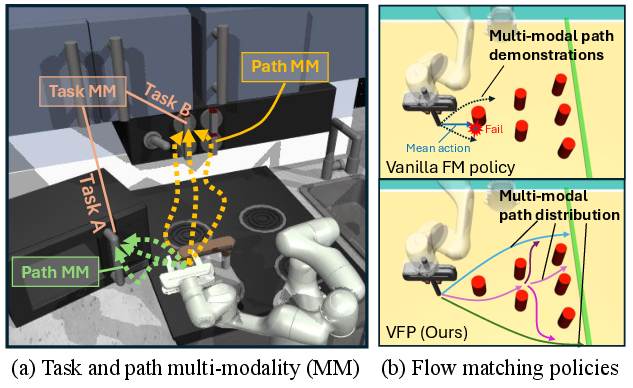
Figure 1: In Franka Kitchen environment, the robot finishes multiple tasks and each task has different paths, which necessitates the policy to capture the task and path multi-modality.
Methodology
Variational Flow-Matching Structure
The VFP framework centers around the use of a variational latent prior to model inherent multi-modality in robot manipulation scenarios. By doing so, it offloads the burden of mode identification to these latent variables, facilitating a more precise action generation by the downstream flow matching model. The approach seeks to address the mode averaging issue in conventional flow-matching policies by explicitly capturing distinct modes of behavior through a variational inference mechanism. This allows the flow-matching decoder to focus on generating actions conditioned on specific modes, thus increasing the expressiveness of the learned policy.
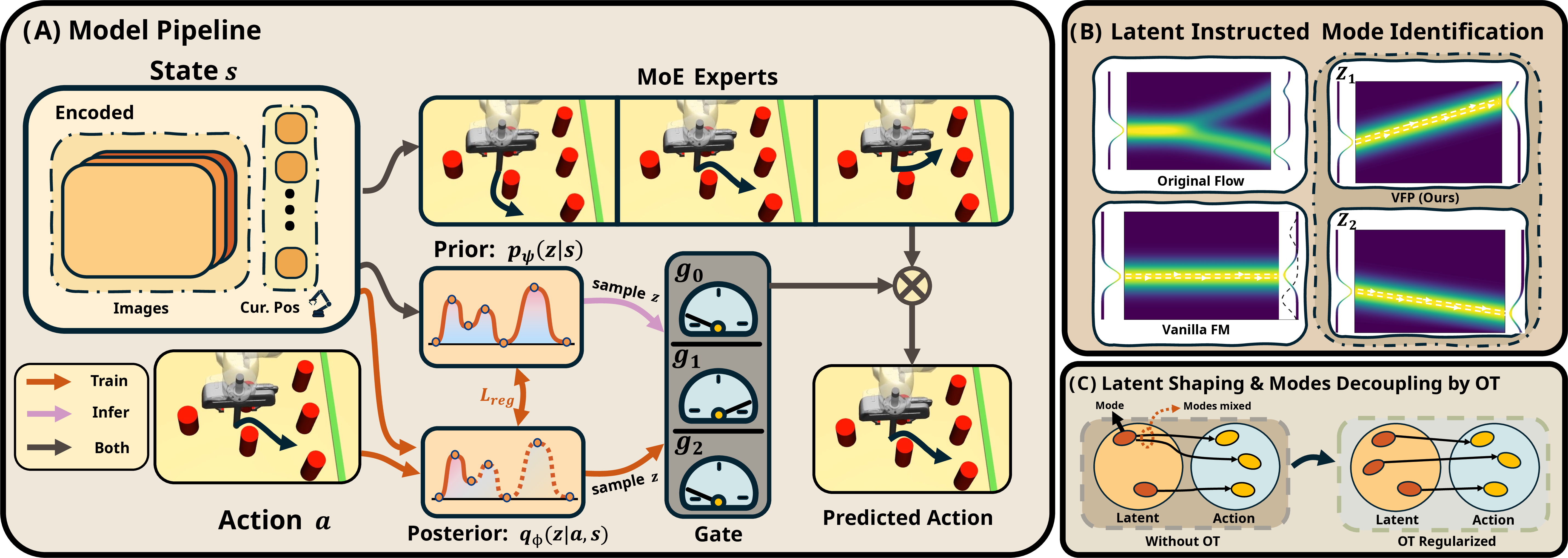
Figure 2: Overview of VFP, demonstrating model pipeline, latent-instructed mode identification, and latent shaping via OT.
The VFP employs a latent variable z, which dictates mode selection, and uses a structured flow decoder conditioned on this latent variable. The training leverages a variational lower bound to jointly optimize the distribution alignment and mode specialization, effectively enhancing the ability of the policy to capture complex behaviors without sacrificing the benefits of rapid inference provided by flow-matching models.
Kantorovich Optimal Transport (K-OT) Regularization
K-OT is integrated to enhance the alignment between predicted and expert distributions at each state, thus promoting better multi-modal behavior separation. This is essential for mitigating the averaging effect in multi-modal learning environments. By utilizing K-OT regularization, VFP ensures that predicted actions are diverse and aligned with expert demonstrations across mode configurations, achieving a more representative imitation learning outcome.
Mixture-of-Experts (MoE) Decoder
The policy decoder in VFP is structured as a Mixture-of-Experts, where each expert is trained to specialize in a distinct behavioral mode, enhancing the model's capability to express complex multi-modal distributions. This design not only contributes to higher representation capacity but also optimizes inference efficiency as it reduces unnecessary computational overhead by selecting specific experts based on mode identification during inference.
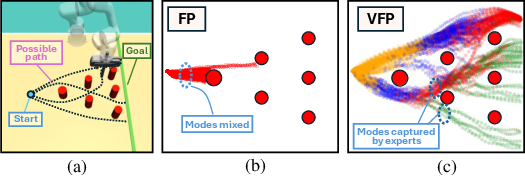
Figure 3: The Avoiding task and behaviors of policies, illustrating the advantage of VFP in maintaining distinct trajectory modes.
Experimental Validation
The performance of VFP was assessed through extensive benchmarking on both simulated and real-world robot manipulation tasks, demonstrating marked improvements in success rates over existing flow and diffusion-based baselines. The integration of variational inference, K-OT regularization, and MoE decoding proved particularly beneficial in scenarios characterized by high multi-modality. In simulated environments like D3IL and Franka Kitchen, VFP achieved up to an 11.5% improvement over state-of-the-art methods, effectively handling both task and path-level multi-modality.
Furthermore, real-world experiments confirmed the transferability of these gains to practical settings, with VFP significantly outperforming FlowPolicy and Diffusion Policy across real-robot benchmarks involving diverse bimanual tasks. The optimized policy structure not only ensured superior performance but also maintained fast inference speeds essential for real-time applications.


Figure 4: Ablation studies demonstrate the impact of the MoE decoder and K-OT regularization on capturing multi-modal distributions.
Conclusion
The VFP framework represents a significant advancement in robot manipulation by effectively addressing the challenges of multi-modal action distribution through a novel combination of variational objectives, optimal transport regularization, and a structured decoding approach. This methodology facilitates precise imitation of expert behaviors in complex, multi-modal environments, laying a robust foundation for future research and development in adaptive, real-time robotic systems.
In summary, VFP's integration of advanced techniques for both distribution alignment and mode specialization sets a new benchmark for multi-modal policy learning in robotic applications, underscoring the importance of holistic model design in the pursuit of high-performance robot manipulation tasks.