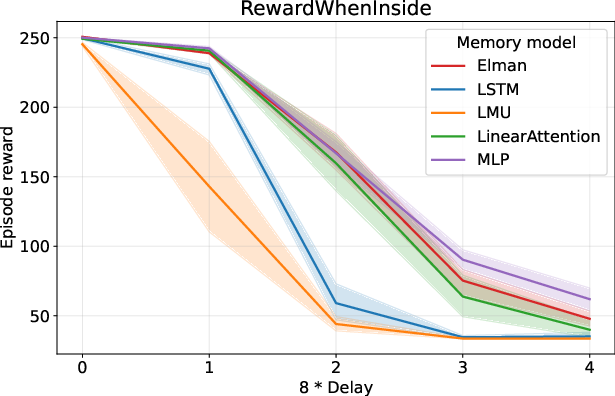
- The paper's main contribution establishes a theoretical framework (MDS) to design synthetic POMDPs for rigorous evaluation of memory-augmented RL.
- Using linear process dynamics and state aggregation techniques, the methodology offers configurable control over environment difficulty and memory demands.
- Experimental results reveal that simpler models can outperform complex architectures under uniform transition dynamics despite increased memory challenges.
Synthetic POMDPs to Challenge Memory-Augmented RL: Memory Demand Structure Modeling
Introduction
The paper presents a methodology to design Partially Observable Markov Decision Process (POMDP) environments, specifically constructed to evaluate reinforcement learning (RL) agents with memory augmentation. The primary motivation is to address the challenge of evaluating memory-augmented RL in scenarios where agents must rely on historical observations to make decisions. Traditional benchmarks tend to focus on real-world complexities but lack controlled manipulation over dynamics, which is crucial for attributing difficulty and understanding the capabilities of memory models.
Theoretical Framework
The research introduces a theoretical framework based on Memory Demand Structure (MDS) which offers a refined lens to quantify the memory requirements of POMDPs. Within this framework, two primary components are emphasized:
- Transition Invariance: It includes concepts like stationarity and consistency in transitions, describing how uniform or varied the process dynamics are over time and across trajectories.
- Memory Demand Structure (MDS): Defines the critical points within a trajectory that must be retained for accurate future state and reward estimation.
The paper demonstrates how to leverage these theoretical insights to develop synthetic environments where MDS can be explicitly controlled and varied to create targeted challenges for RL agents.
Construction Methodology
The authors propose a methodology synthesizing POMDPs using linear process dynamics, aggregating states, and redistributing rewards:
- Linear Process Dynamics: Utilizing AR processes allows constructing straightforward yet configurable dynamics, enabling explicit definition of environment difficulty by setting process order and coefficients.
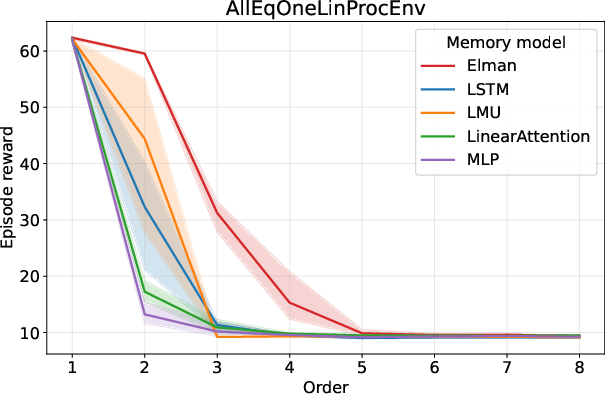
Figure 1: Linear processes with coefficients all equal to 1.
- State Aggregation and Reward Redistribution: Custom POMDPs are generated by aggregating states or redistributing rewards from existing MDPs. This preserves the underlying challenge while introducing new layers of difficulty, such as increased memory demands or delayed reward signals.
- Empirical Validation: The environments based on varying difficulty levels are empirically tested to validate the theoretical framework's effectiveness in discerning the strengths and weaknesses of different memory models.
Experimentation and Results
Experiments on the synthesized environments reveal significant performance insights. Interestingly, simpler models like the Elman RNN tend to outperform more complex counterparts such as LSTMs or attention-based models in tasks with uniform transition dynamics.
Implications and Future Work
The framework significantly enhances our understanding of how memory components in RL can be evaluated in a structured manner. By isolating difficulties arising specifically from memory demands, this research can guide the development of improved strategies in algorithmic design.
Future research avenues remain open, particularly in exploring more diverse MDS configurations and understanding their implications for novel RL model architectures. Additionally, empirical exploration of varying trajectory categories or environments with heterogeneous MDS patterns could provide deeper insights into designing RL agents that can generalize across complex environment dynamics.
Conclusion
This research provides a structured methodology for creating synthetic environments catered to benchmarking memory-augmented RL models. By shifting focus from heuristic-based benchmarks to theoretically grounded MDS-induced POMDPs, the paper lays the groundwork for enhanced RL algorithm design and evaluation in scenarios demanding robust memory capabilities.