- The paper introduces a supervised foundation model that leverages multi-taxa datasets with innovative mixup generalization and self-distillation to achieve state-of-the-art embedding performance.
- It employs a modular architecture integrating EfficientNet-B3-based spectrogram extraction with three output heads—linear classifier, prototype learning, and source prediction—for robust species classification.
- The results demonstrate high transfer learning efficacy, outperforming specialized models on diverse benchmarks and even excelling in few-shot marine bioacoustics scenarios.
Perch 2.0: Supervised Foundation Model for Bioacoustics
Introduction
Perch 2.0 represents a significant advance in the development of pre-trained models for bioacoustics, expanding the scope from avian-only datasets to a large multi-taxa corpus. The model is designed to provide robust species classification and high-quality embeddings for transfer learning, with a particular emphasis on practical deployment in conservation and biodiversity monitoring. The architecture leverages supervised learning, self-distillation, and a novel mixup generalization, achieving state-of-the-art results on BirdSet and BEANS benchmarks. Notably, Perch 2.0 demonstrates strong transfer learning capabilities, outperforming specialized marine models despite minimal marine training data.

Figure 1: Australasian bittern, emblematic of the "bittern lesson"—that simple, supervised models remain difficult to surpass in bioacoustics.
Model Architecture and Training Pipeline
Perch 2.0 employs a modular architecture comprising a frontend for spectrogram extraction, an EfficientNet-B3 embedding model, and three output heads: a linear classifier, a prototype learning classifier, and a source prediction head.
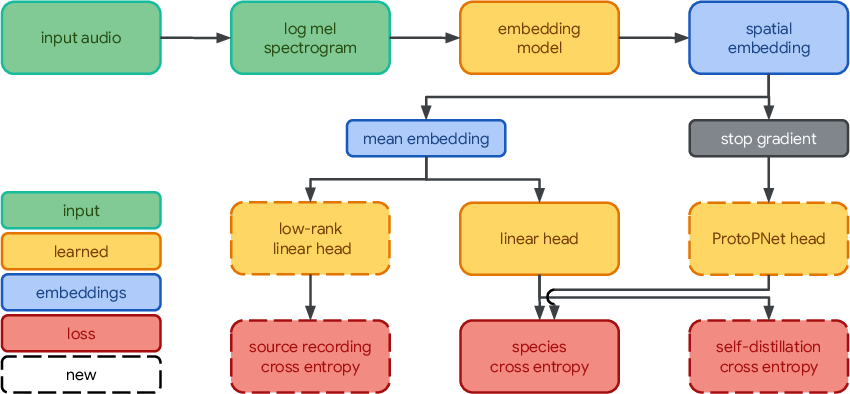
Figure 2: Perch 2.0 model architecture, illustrating the flow from raw audio to embeddings and multi-head outputs.
Data Sources and Preprocessing
Training utilizes four major labeled datasets: Xeno-Canto, iNaturalist, Tierstimmenarchiv, and FSD50K, totaling over 1.5 million recordings and nearly 15,000 classes. The data spans birds, amphibians, insects, mammals, and general sound events. Window selection is performed via random sampling and energy peak detection, with the latter using wavelet transforms to identify high-energy segments likely to contain target vocalizations.
Mixup Generalization
A key innovation is the generalization of mixup to more than two audio sources. The number of components is sampled from a beta-binomial distribution, and weights are drawn from a symmetric Dirichlet. The mixed signal is normalized to preserve gain, and multi-hot targets are used to reflect the presence of multiple vocalizations. This approach increases the difficulty of the classification task, which empirically improves embedding quality.
Output Heads and Training Objectives
- Linear Classifier: Projects mean embeddings to the class label space, optimized with softmax cross-entropy.
- Prototype Learning Classifier: Implements four prototypes per class, using maximum activation for prediction. An orthogonality loss encourages diversity among prototypes.
- Source Prediction Head: Predicts the source recording using a low-rank projection, serving as a self-supervised auxiliary loss.
Training proceeds in two phases: initial supervised learning, followed by self-distillation where the prototype classifier's predictions serve as soft targets for the linear classifier. Hyperparameters are optimized using Vizier, with distinct preferences for mixup, dropout, and loss weights in each phase.
Evaluation and Benchmarking
Perch 2.0 is evaluated on real-world tasks reflecting domain shift, transfer learning, and few-shot scenarios. Embeddings are frozen during evaluation to simulate practical deployment, where practitioners may lack resources for full fine-tuning.
- BirdSet Benchmark: Six fully-annotated avian soundscape datasets.
- BEANS Benchmark: Twelve cross-taxa tasks, including birds, mammals, amphibians, and insects.
- Marine Audio Transfer: DCLDE 2026, NOAA PIPAN, and ReefSet datasets for underwater audio.
Performance is measured via ROC-AUC, class-mean average precision (cmAP), and top-1 accuracy. Perch 2.0 achieves state-of-the-art results across all metrics, with prototypical probing further improving detection tasks. Notably, random window selection performs comparably to energy peak selection, attributed to the robustness conferred by self-distillation.
Label Granularity and Transfer Learning
Experiments demonstrate that fine-grained species labels are critical for transfer learning performance. Models trained with coarser labels (genus, family, order) exhibit degraded accuracy and mAP on BEANS tasks, underscoring the value of detailed supervision.
Marine Bioacoustics Transfer
Perch 2.0 outperforms specialized marine models (SurfPerch, Multispecies Whale) on few-shot classification tasks for cetacean species and reef sounds, despite limited marine training data. This highlights the generalizability of embeddings learned from diverse terrestrial taxa and the utility of Perch 2.0 as a foundational model for agile modeling in novel domains.
Discussion
Supervision vs. Self-Supervision
Contrary to trends in NLP and vision, supervised learning remains dominant in bioacoustics. The limited scale of available unlabeled data and the domain-specific nature of augmentations constrain the efficacy of self-supervised methods. The abundance of fine-grained labeled data and the diversity of birdsong facilitate robust supervised pre-training, yielding embeddings that transfer effectively across taxa and environments.
Model Efficiency and Deployment
Perch 2.0 is designed for practical deployment: its moderate size (12M parameters) enables efficient inference on consumer hardware, and its embeddings are linearly separable, supporting clustering, nearest-neighbor search, and few-shot learning without full model fine-tuning. This approach conserves computational resources and lowers the barrier for practitioners in ecology and conservation.
Implications and Future Directions
The results suggest that supervised pre-training on large, fine-grained bioacoustic datasets is a robust strategy for developing foundation models in this domain. The success of auxiliary objectives (source prediction) points to promising avenues for semi-supervised learning, particularly for underrepresented taxa. Future work should focus on developing benchmarks that better reflect real-world deployment scenarios and exploring the use of metadata (e.g., time, location) for constructing additional classification tasks.
Conclusion
Perch 2.0 establishes a new standard for bioacoustic foundation models, demonstrating that well-tuned supervised architectures with strong augmentations and auxiliary losses can deliver high-quality, generalizable embeddings. Its design prioritizes scalability, efficiency, and adaptability, making it a valuable tool for researchers and practitioners in biodiversity monitoring and conservation. The findings reinforce the importance of label granularity and supervised learning in bioacoustics, while opening pathways for future research in semi-supervised and metadata-driven modeling.