- The paper presents a novel average squared discrepancy measure that overcomes the origin bias and inefficiencies of traditional L2 and L∞ star discrepancies.
- The paper demonstrates, through numerical studies using MPMC and sequential greedy methods, that optimized point sets achieve superior performance over standard sequences.
- The paper outlines practical implications for AI and numerical computing by establishing robust, scalable optimization methods for uniform point distribution.
On the Optimization of Discrepancy Measures
The paper "On the optimization of discrepancy measures" (2508.04926) addresses fundamental issues in the optimization of discrepancy measures, used to evaluate the uniform distribution of points in the unit cube [0,1]d. Discrepancy measures are crucial in fields such as multivariate integration, computer graphics, neural network training, and robotics. The paper introduces the average squared discrepancy as a novel measure that circumvents issues associated with other classical measures, particularly those highlighted by Matoušek. Through a comprehensive numerical study, the paper demonstrates the advantages of the average squared discrepancy in practical optimization settings.
Introduction to Discrepancy Measures
Discrepancy measures quantify how evenly points are distributed within the unit cube. The most common measure is the L∞ star discrepancy, but it suffers from computational inefficiencies and lacks differentiability. As a substitute, many researchers have utilized the L2 star discrepancy due to its computational tractability and differentiability properties.
However, both of these measures have notable limitations: they often overemphasize the corner of the unit cube anchored at the origin, leading to pathological distributions of points. Specifically, placing all points at the farthest corner from the origin can result in deceptively low discrepancy values, undermining the measure’s ability to accurately assess uniformity.
Average Squared Discrepancy
To address these limitations, the paper introduces the average squared discrepancy, denoted D2asd. This measure averages different versions of the L2 star discrepancy across all corners of the unit cube. The formulation of this measure not only avoids the origin bias but is also computationally feasible, with a Warnock-type formula enabling an O(dn2) algorithm. In doing so, the average squared discrepancy demonstrates a balanced approach to uniformity that eliminates the pathological behaviors identified by Matoušek.
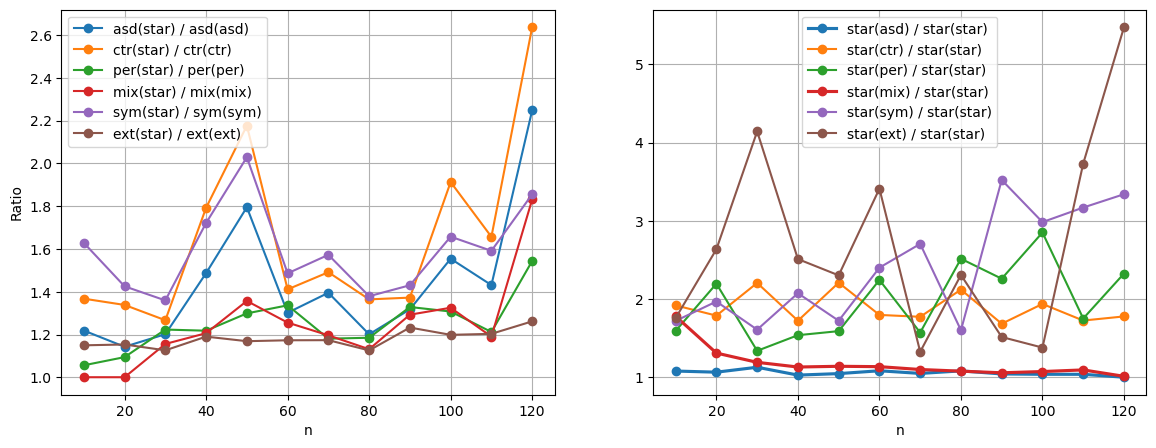
Figure 1: The left panel shows the ratio $(D_2^{\bullet}(x_1,\dots,x_n) / D_2^{\bullet}(\tildex_1,\dots,\tildex_n))$, evaluating discrepancies on star optimized sets vs. sets optimized by other criteria.
Numerical Comparisons and Optimizations
The paper conducts thorough numerical experiments comparing the average squared discrepancy with other traditional measures. Using the Message-Passing Monte Carlo (MPMC) method and sequential greedy approaches, the authors were able to optimize point distributions effectively across dimensions, demonstrating improvement over the Sobol' sequence.
The study finds that point sets optimized using the average squared discrepancy not only achieve low values for the measure itself but also boast near-optimal performance when evaluated with other discrepancy metrics such as the star discrepancy.
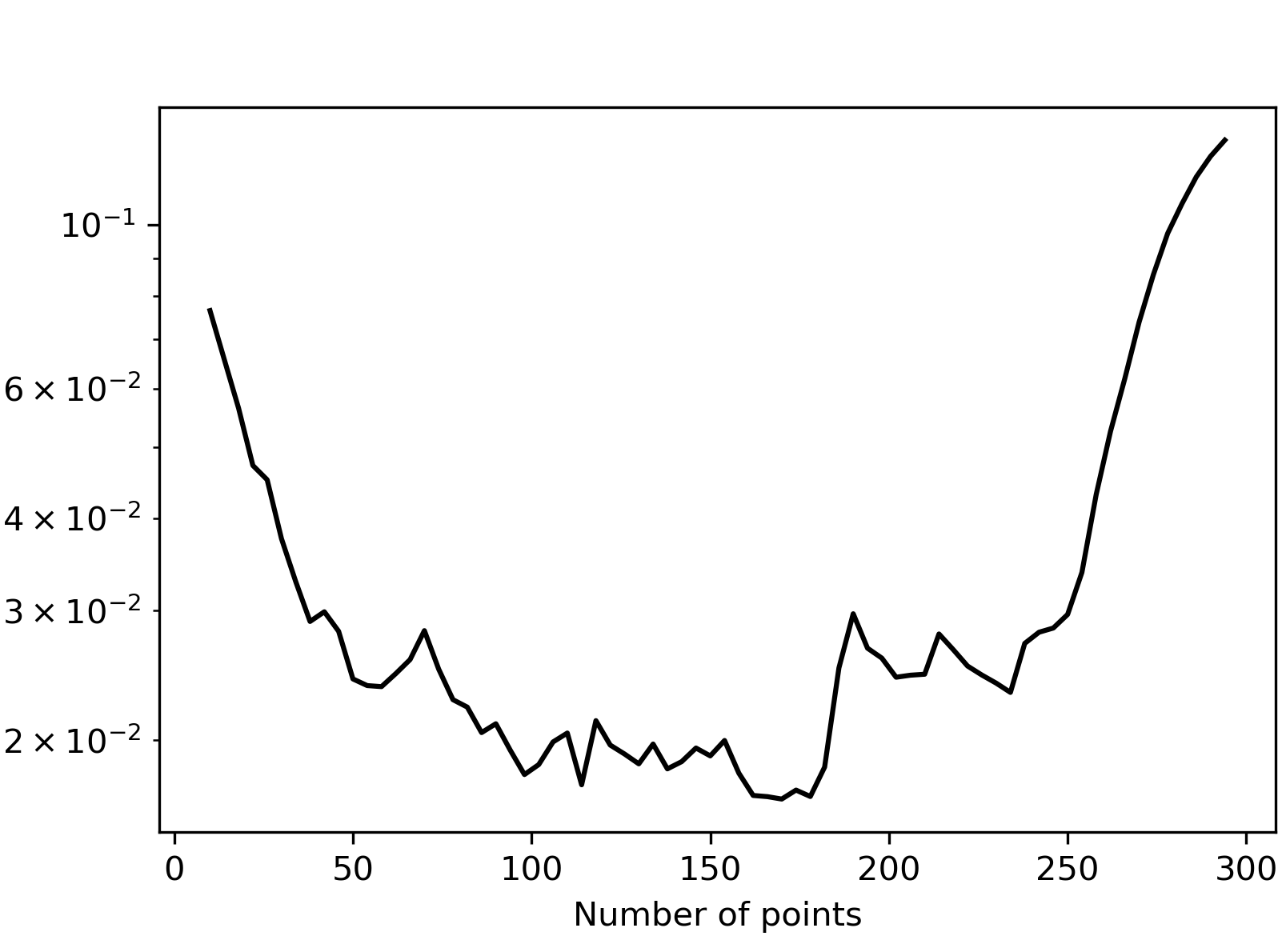
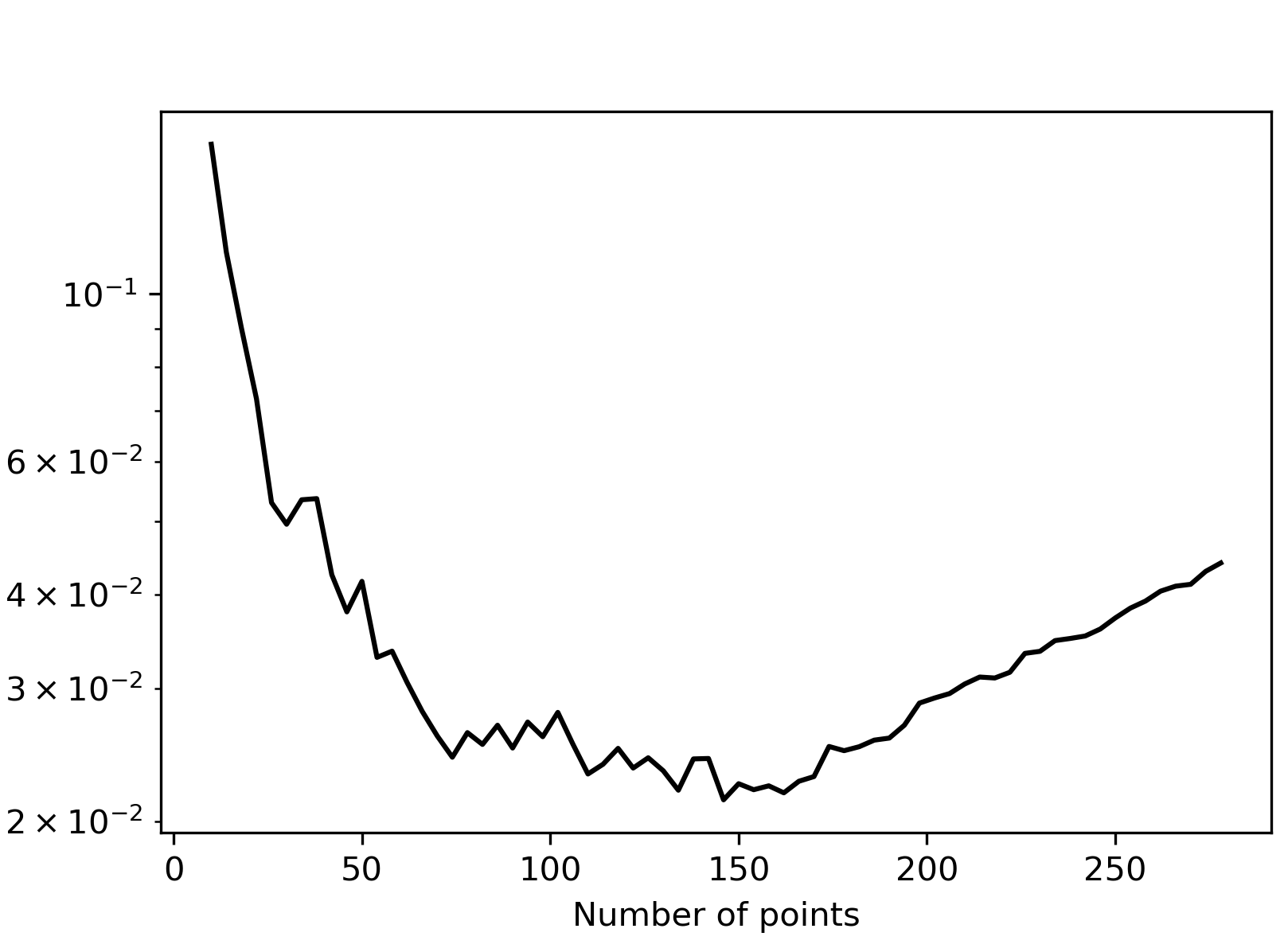
Figure 2: Average squared (left) and centered L2 discrepancies (right) obtained when greedily adding 4 points at a time, starting with the singleton {(0.5,0.5)}.
Implications and Future Directions
The findings suggest that employing symmetry and averaging across multiple point cube corners results in more robust point distributions. These distributions outperform traditional measures and maintain better generalization across different evaluation criteria.
Future work could focus on extending optimization and discrepancy measures to higher dimensions, exploring the effects on more complex distributions, and adopting these methods to different applications in AI. Furthermore, applying these approaches to distributed and parallel computing environments might render them more scalable and efficient for real-time applications.
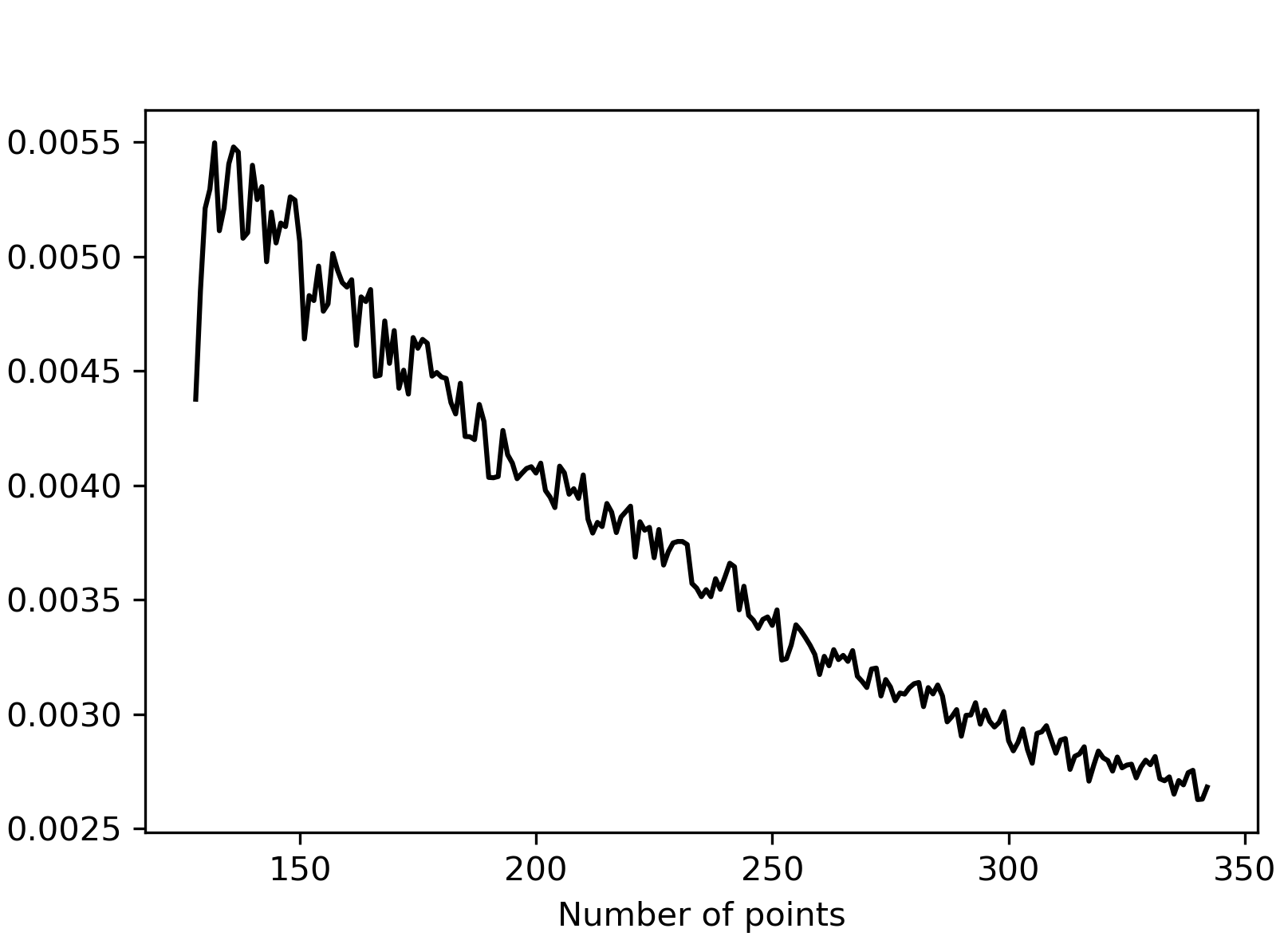
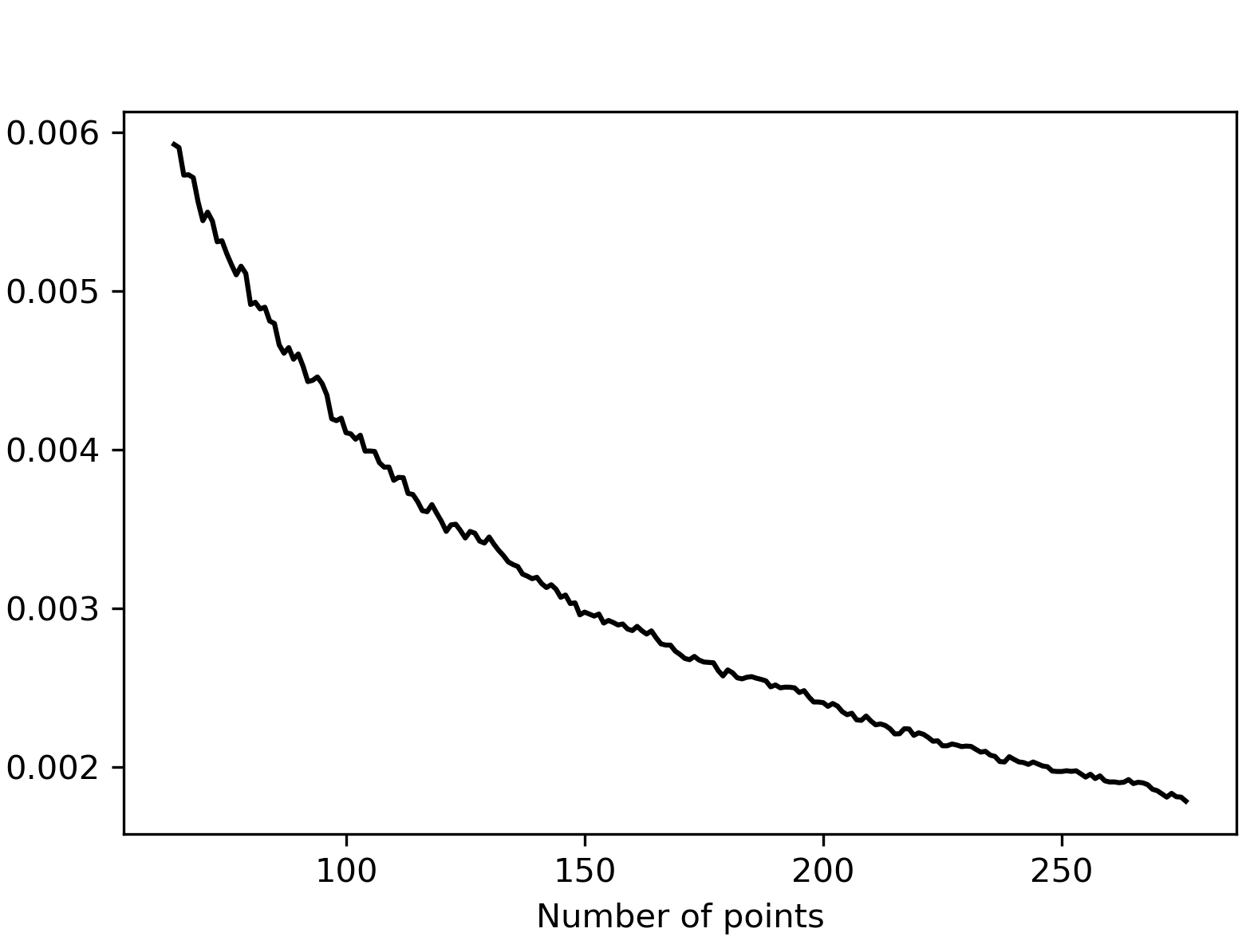
Figure 3: Average squared (left) and extreme (right) L2 discrepancies obtained when adding single optimal points sequentially, showing stable performance across iterations.
Conclusion
The paper demonstrates significant advancements in the optimization of discrepancy measures, particularly through the introduction of the average squared discrepancy. This measure effectively addresses previous limitations relating to bias and inefficiencies. Through robust optimization techniques and empirical evidence, the research highlights the practical benefits and implications for real-world applications. The study lays the groundwork for future investigations aiming to refine these techniques and expand their scope within AI and numerical computing fields.