- The paper introduces a novel framework that exploits predictive uncertainty through overconfidence and underconfidence attacks in machine unlearning.
- It employs a bi-level optimization and a regularized attack loss to significantly increase uncertainty metrics like the Expected Calibration Error on datasets such as CIFAR-10.
- The study exposes inadequacies in current defenses and calls for new security strategies to safeguard AI systems from uncertainty manipulations.
Unveiling Predictive Uncertainty Vulnerabilities in Machine Unlearning
Introduction
The paper "Towards Unveiling Predictive Uncertainty Vulnerabilities in the Context of the Right to Be Forgotten" (2508.07458) explores the intersection of uncertainty quantification (UQ) and machine unlearning, with a focus on potential vulnerabilities. Uncertainty quantification has become a critical aspect of deep learning model deployment, providing confidence estimates to improve model robustness and reliability. On the other hand, the right to be forgotten is driving research into methods for machine unlearning, which aim to remove specific data from pre-trained models without the necessity of complete model retraining. This paper investigates the unexplored area of vulnerabilities in predictive uncertainties that can arise during malicious unlearning attacks.
Key Contributions
The authors propose a novel class of malicious unlearning attacks aimed at manipulating predictive uncertainties. The adversary's goal is to intentionally affect the prediction confidence of models in a targeted manner without altering the accuracy of the label predictions. This is achieved through a sophisticated attack framework leveraging two forms of attacks: overconfidence and underconfidence. The overconfidence attack induces higher certainty in predictions, while the underconfidence attack aims to increase the uncertainty or perceived incompetence of the model's predictions.
Theoretical and Empirical Foundation
Through both empirical experiments and theoretical analysis, the paper validates the proposed attack methods. A key theoretical result (Theorem 1) suggests a correlation between sample proximity in the data distribution and resulting prediction confidence, thus supporting the development of a regularized attack loss that ensures the stealthiness and efficacy of the malicious unlearning requests.
Optimization Techniques
The methodology is underpinned by novel optimization frameworks. These include a regularized attack loss function that aligns the manipulated uncertainty with naturally occurring high-proximity data distributions, enhancing stealthiness. The approach employs a bi-level optimization technique to efficiently craft unlearning requests that maximize the attack’s impact on uncertainty metrics, such as the Expected Calibration Error (ECE).
Experimental Results
The study conducts extensive evaluations across several datasets (CIFAR-10, CIFAR-100, ImageNet-100, and ISIC 2018) and deep learning architectures (e.g., ResNet-18, VGG-19). The results demonstrate the efficacy of the proposed attacks over traditional methods, where significant increases in uncertainty metrics were observed under various settings, including attacks formulated under both white-box and black-box assumptions.
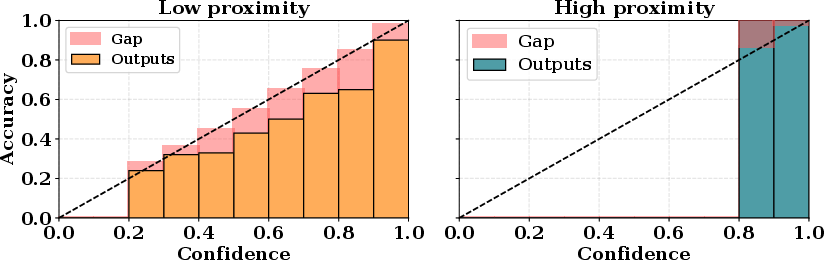
Figure 1: Relationship between the proximity and confidence on CIFAR-10. Samples with higher (lower) proximity tend to be more underconfident (overconfident).
Comparison with Existing Methods
Results show that existing defenses against traditional adversarial and poisoning attacks fail to mitigate the new class of attacks introduced in this paper. The authors demonstrate that the proposed attacks, by focusing on predictive uncertainty rather than label accuracy, can bypass these existing defenses with ease (Figures 2 and 3).
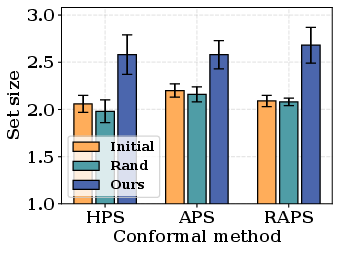
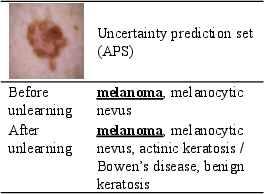
Figure 2: Attack performance compares the efficacy of the proposed method against traditional attacks, highlighting superiority in manipulating predictive uncertainties.
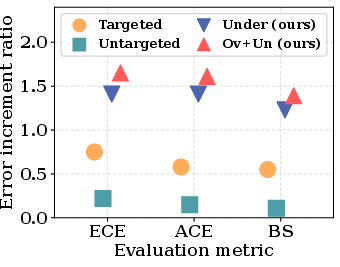
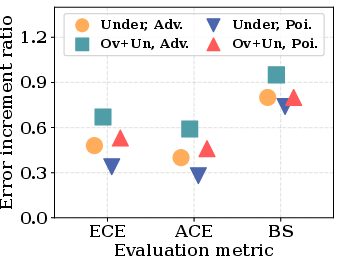
Figure 3: Attack comparison reveals the ineffectiveness of existing defenses in countering the proposed novel unlearning threats.
Implications and Future Work
This research highlights potential risks associated with the integration of machine unlearning and uncertainty quantification, particularly under scenarios where adversarial actors manipulate model confidence. The implications are profound, suggesting a reconsideration of defenses in AI systems to not only address label misclassification but also to secure against uncertainty manipulations. Future work may focus on developing robust defenses specific to this domain, refining unlearning methods for greater security without sacrificing computational efficiency.
Conclusion
The paper presents a comprehensive framework for understanding and exploiting the vulnerabilities in predictive uncertainties during machine unlearning, advancing the discourse in privacy-preserving machine learning. By illustrating the inadequacy of traditional defense mechanisms against these novel threats, it paves the way for new security strategies in the AI landscape.