Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Published 11 Aug 2025 in cs.LG, cs.AI, and cs.CL | (2508.07629v2)
Abstract: We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model's exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
The paper introduces a novel Gradient-Preserving Clipping Policy Optimization (GPPO) that retains gradient information to improve exploration and convergence in LLMs.
The paper demonstrates that integrating a quality-centric supervised fine-tuning pipeline with GPPO yields state-of-the-art results on benchmarks like AIME2024 and LiveCodeBench.
The paper shows that employing soft reward strategies and rigorous data filtering enhances stability and overall performance in long-form reasoning tasks.
Klear-Reasoner: Gradient-Preserving Clipping for Advanced Reasoning in LLMs
Overview
Klear-Reasoner introduces a principled approach to enhancing mathematical and programming reasoning in LLMs by integrating a quality-centric supervised fine-tuning (SFT) pipeline with a novel reinforcement learning (RL) algorithm: Gradient-Preserving Clipping Policy Optimization (GPPO). The work provides a comprehensive analysis of post-training workflows, ablation studies, and empirical results, demonstrating that careful data curation and advanced RL optimization can yield state-of-the-art performance in long-form reasoning tasks.
Motivation and Background
Recent advances in LLM reasoning, exemplified by models such as DeepSeek-R1 and Qwen3-8B, have relied heavily on RL post-training. However, reproducibility and stability issues persist due to incomplete disclosure of training details and limitations in existing RL algorithms, particularly those employing hard clipping strategies (e.g., PPO, GRPO, DAPO). These methods often suppress critical exploration signals and ignore suboptimal trajectories, impeding both convergence and exploration.
Klear-Reasoner addresses these challenges by:
Prioritizing high-quality, difficult data in SFT, leveraging the insight that incorrect samples can be beneficial for hard tasks.
Proposing GPPO, which retains gradient information from all tokens, including those clipped by traditional methods, thereby improving both exploration and convergence.
Data Curation and Supervised Fine-Tuning
The SFT pipeline is built on a compact set of high-quality sources for both mathematics and code, with strict deduplication and contamination filtering. Teacher responses are generated using DeepSeek-R1-0528, and all responses are retained for difficult samples, following empirical findings that mixed correctness data benefits hard tasks.
Key findings include:
For easy tasks, training on only correct data is optimal.
For hard tasks, including incorrect samples improves performance, likely by enhancing exploration and discrimination between valid and invalid reasoning paths.
Reinforcement Learning: GPPO Formulation
GPPO modifies the classical PPO/GRPO objectives by decoupling gradient flow from clipping constraints. Instead of discarding gradients for tokens outside the clipping bounds, GPPO gently backpropagates bounded gradients from all tokens, preserving valuable learning signals while maintaining training stability.
The GPPO loss for token-level policy optimization is:
where δ is the importance sampling ratio, and A~(j) is the group-relative advantage.
GPPO's gradient update strategy is pessimistic: it suppresses overly optimistic updates for positive advantages and fully trusts negative feedback, in contrast to concurrent methods such as CISPO.
Empirical Results and Ablations
Klear-Reasoner-8B achieves strong results across multiple benchmarks:
These scores surpass or match state-of-the-art models of comparable scale, even when trained with a 32K context window and evaluated at 64K using YaRN scaling.
RL Algorithm Comparison
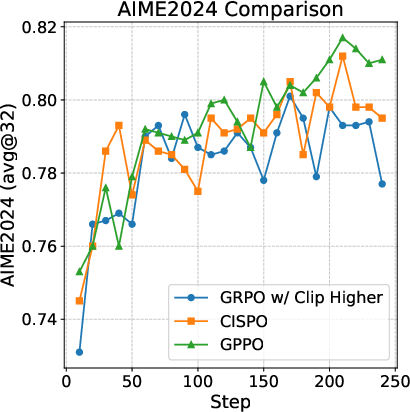
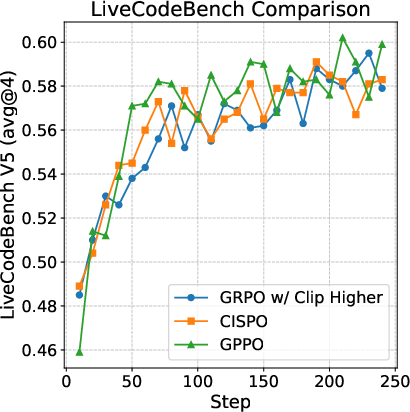
Klear-Reasoner demonstrates that GPPO outperforms GRPO w/ Clip-Higher and CISPO in both stability and final performance on math and code RL tasks.
Figure 1: GPPO achieves superior and more stable learning curves compared to GRPO w/ Clip-Higher and CISPO in mathematical RL training.
Reward Design
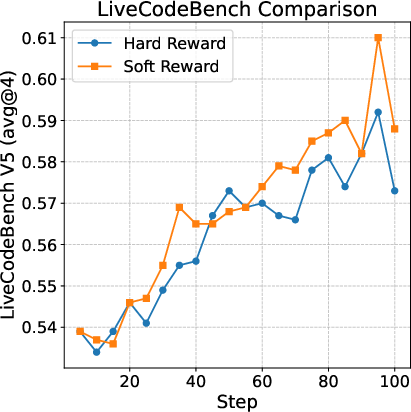
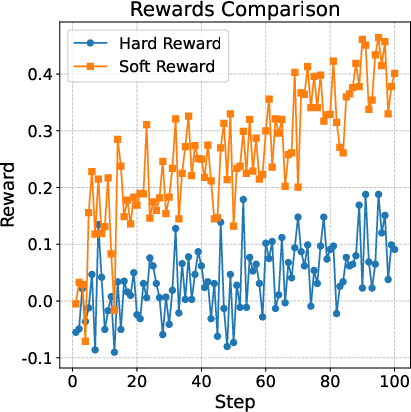
Soft reward strategies, which assign proportional rewards based on test case pass rates, yield higher average rewards and lower variance than hard binary rewards in code RL. This dense supervision enables learning from partially correct outputs and improves generalization.
Figure 2: Soft reward strategies consistently outperform hard reward baselines in code RL, providing denser and more stable learning signals.
Data Filtering
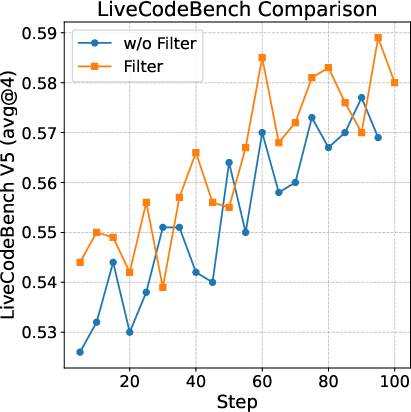
Filtering code RL data based on estimated pass@16 scores improves both final performance and training stability, mitigating the impact of flawed test cases.
Figure 3: Code RL performance on LiveCodeBench V5 is enhanced by filtering prompts with high estimated pass rates, reducing noise from faulty test cases.
Zero-Advantage Filtering
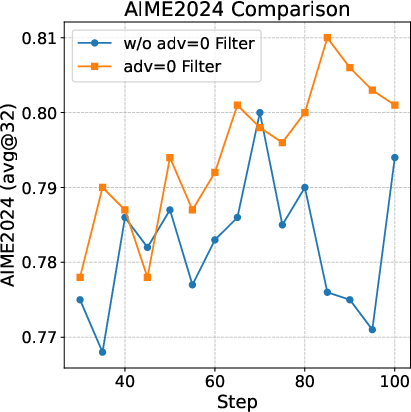
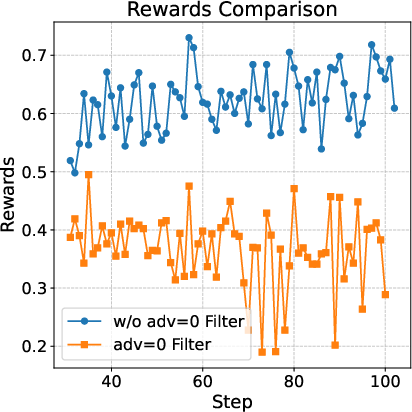
Excluding zero-advantage groups in math RL leads to more stable and consistent improvements, as these samples provide no meaningful learning signal and dilute optimization direction.
Figure 4: Filtering zero-advantage groups in math RL yields more stable and predictable improvements on AIME2024.
Implementation Considerations
Computational Requirements: Training is conducted with a global batch size of 128, sequence lengths up to 32K, and multi-stage RL (math followed by code). RL is performed jointly with SFT loss, with α set to 0.1 for optimal regularization.
Scaling: The model generalizes well to longer inference windows (64K) using YaRN, despite being trained at 32K.
Data Strategy: Emphasis on high-quality, difficult data sources and rigorous filtering is critical for both SFT and RL.
RL Stability: GPPO's bounded gradient propagation ensures stable training, even with aggressive exploration.
Implications and Future Directions
Klear-Reasoner demonstrates that principled data curation, targeted SFT, and advanced RL optimization can jointly deliver substantial improvements in long-form reasoning. The GPPO algorithm provides a robust framework for RL in LLMs, balancing exploration and stability without discarding valuable gradient information. The findings suggest that future developments should focus on:
Further refinement of gradient control mechanisms in RL.
Extension of GPPO to other domains requiring long-horizon reasoning and sparse rewards.
Investigation of dynamic reward shaping and curriculum learning in RL for LLMs.
Conclusion
Klear-Reasoner advances the state of reasoning in LLMs by integrating a quality-centric SFT pipeline with Gradient-Preserving Clipping Policy Optimization. The approach addresses key limitations of traditional RL algorithms, enabling stable and efficient learning from both positive and negative samples. Empirical results validate the effectiveness of the method, and the analysis provides actionable insights for future research in LLM post-training and RL optimization.