- The paper introduces S2M2-SAR, a novel semi-supervised method that fuses deep semantic and shallow spatial features for improved SAR-optical alignment.
- It employs an attention-based cross-modal feature enhancement module with pseudo-labeling to reduce labeling costs and boost matching accuracy.
- Experimental validation on SEN1-2 and QXS-SAROPT datasets demonstrates superior matching performance and lower RMSE compared to fully supervised methods under minimal supervision.
Semi-supervised Multiscale Matching for SAR-Optical Image: A Comprehensive Analysis
Problem Context and Challenges
Matching synthetic aperture radar (SAR) images with optical imagery is fundamental for multimodal remote sensing tasks including data fusion, geo-localization, and environmental monitoring. The intrinsic discrepancy in appearance, radiometry, and geometry—owing to the distinct imaging mechanisms of SAR and optical sensors—renders traditional mono-modal registration approaches ineffective. While SOTA deep learning methods increase matching performance by extracting modality-invariant features, their success heavily relies on extensive labeled correspondences, which are labor-intensive to annotate and infeasible to acquire at scale for diverse sensor types and scenarios.
Overview of S2M2-SAR
The paper introduces S2M2-SAR, a semi-supervised multiscale matching architecture. The method is designed to minimize supervision requirements by leveraging both labeled and abundant unlabeled SAR-optical image pairs while robustifying matching through multi-level feature integration. The framework integrates a Siamese ResNetFPN backbone, cross-modal feature enhancement, and a multiscale pseudo-labeling pipeline.
Key methodological innovations include:
Methodological Details
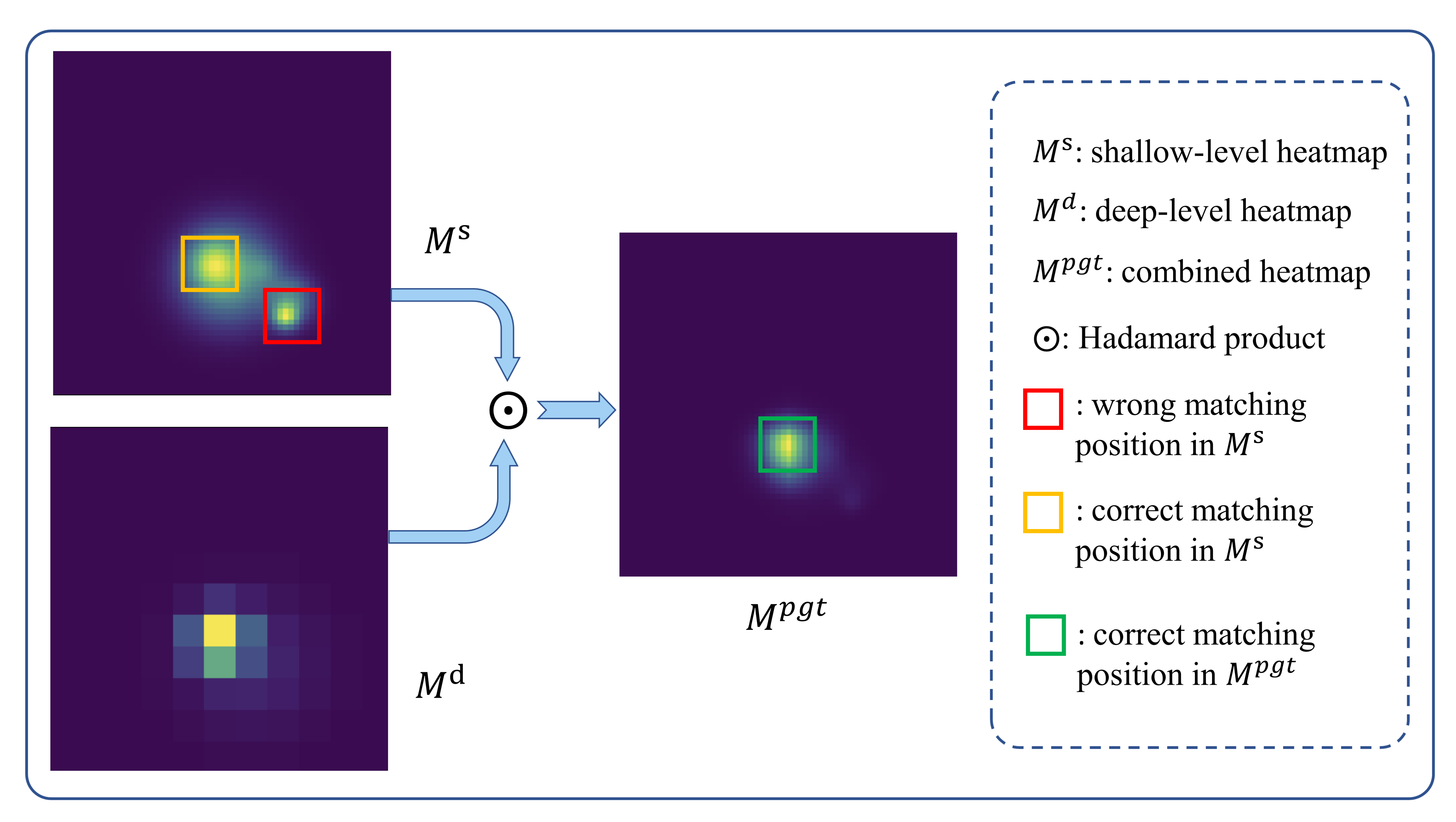
The Siamese ResNetFPN backbone extracts hierarchical features at both the original and subsampled resolutions. By omitting initial downsampling and introducing lateral pyramid connections, the system ensures shallow-level features maintain pixelwise accuracy, while deep features encode semantic context and spatial robustness.
Matching is operationalized via FFT-accelerated NCC, producing two heatmaps per image pair: Md from deep maps, Ms from shallow maps. For inference and pseudo-label generation, upsampled deep heatmaps are elementwise-multiplied with shallow heatmaps, then normalized, enforcing consistency across scales.
The attention-based feature enhancement block consists of sequential self- and cross-attention layers with linear complexity, each followed by multiscale convolution, forming an efficient architecture for representation disentanglement.
Mutual information minimization between the extracted shared and modality-specific feature spaces serves as an unsupervised regularizer. This theoretical formulation is explicitly realized via the calculation of discrete mutual information on flattened feature maps, summed across SAR and optical modalities.
Experimental Validation
The proposed method is benchmarked on the large-scale SEN1-2 dataset and the QXS-SAROPT dataset, using a minimal supervision regime (6.25% labeled data). Quantitative evaluation on CMR (T=1, T=5), RMSE, and inference time demonstrates:
- Superior correct matching rates and lower RMSEs compared to both fully supervised (100% labeled) and semi-supervised baselines, despite significantly reduced supervision.
- Robustness to data scarcity, with high performance maintained as the proportion of labeled data decreases.
Comprehensive ablation experiments reveal:
- Cross-modal feature enhancement, even with a single block, significantly boosts matching performance.
- Combining multiscale matching with semi-supervised losses stabilizes the system and enhances pseudo-label quality.
- The number of enhancement blocks trades off between accuracy (particularly high-precision, low-threshold matching) and computational cost.
Analysis of Pseudo-labels and Label Scarcity
The pseudo-labels serve as a denoising and regularization mechanism, as evidenced by their superior RMSE and lower FMR relative to direct shallow-level matching during early training. As the network converges, the gap narrows, confirming their effectiveness for semi-supervised SAR-optical correspondence learning.
Experiments varying the labeled-unlabeled batch ratio highlight the scalability and adaptability of the approach: even few labeled samples suffice for competitive performance, and accuracy improves monotonically with additional annotation.
Practical and Theoretical Implications
Practically, S2M2-SAR drastically reduces annotation dependence for multimodal matching, facilitating rapid scaling to new SAR-optical data sources and sensor domains. Its use of unsupervised regularization and pseudo-label bootstrapping makes it robust to noisy or biased ground-truth, addressing a critical bottleneck in real-world deployments.
Theoretically, the integration of cross-modal mutual independence loss aligns with modern understanding of disentangled representation learning and cross-domain correspondence, offering a general template for semi-supervised multimodal learning. The architecture's emphasis on linear attention mechanisms also points toward computationally efficient scaling for dense remote sensing workloads.
The method's structure enables extensibility: more advanced backbones, alternative feature disentanglement losses, and self-supervised auxiliary objectives can be seamlessly integrated. This positions S2M2-SAR as a state-of-the-art paradigm for semi-supervised multimodal remote sensing correspondence, with implications for general cross-domain matching tasks in computer vision.
Conclusion
S2M2-SAR demonstrates that semi-supervised, multiscale feature integration, coupled with attention-based disentanglement and robust pseudo-labeling, can achieve performance competitive with or superior to fully supervised approaches for SAR-optical matching—even with minimal labeled data. The framework is computationally efficient, empirically sound, and theoretically grounded. Future research directions include fully unsupervised extensions, exploration of advanced feature backbones, and application of the architecture to other heterogeneous matching problems in vision, such as multimodal medical image registration and general remote sensing data fusion.