Multi-head Transformers Provably Learn Symbolic Multi-step Reasoning via Gradient Descent
Abstract: Transformers have demonstrated remarkable capabilities in multi-step reasoning tasks. However, understandings of the underlying mechanisms by which they acquire these abilities through training remain limited, particularly from a theoretical standpoint. This work investigates how transformers learn to solve symbolic multi-step reasoning problems through chain-of-thought processes, focusing on path-finding in trees. We analyze two intertwined tasks: a backward reasoning task, where the model outputs a path from a goal node to the root, and a more complex forward reasoning task, where the model implements two-stage reasoning by first identifying the goal-to-root path and then reversing it to produce the root-to-goal path. Our theoretical analysis, grounded in the dynamics of gradient descent, shows that trained one-layer transformers can provably solve both tasks with generalization guarantees to unseen trees. In particular, our multi-phase training dynamics for forward reasoning elucidate how different attention heads learn to specialize and coordinate autonomously to solve the two subtasks in a single autoregressive path. These results provide a mechanistic explanation of how trained transformers can implement sequential algorithmic procedures. Moreover, they offer insights into the emergence of reasoning abilities, suggesting that when tasks are structured to take intermediate chain-of-thought steps, even shallow multi-head transformers can effectively solve problems that would otherwise require deeper architectures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of “Multi-head Transformers Provably Learn Symbolic Multi-step Reasoning via Gradient Descent”
What is this paper about? (Overview)
This paper explains, with math proofs, how a fairly simple AI model called a transformer can learn to solve step-by-step reasoning problems—kind of like solving a maze—by “thinking out loud.” The authors focus on a classic puzzle: finding a path in a tree (a branching structure like a family tree or a file folder system) from a starting point to a goal. They show that even a shallow (one-layer) transformer can learn to do this if it is allowed to produce and use intermediate steps (a chain-of-thought).
What questions does the paper ask? (Key objectives)
The paper looks at three main questions, written here in plain terms:
- Can a one-layer transformer learn to find paths in a tree by reasoning step by step?
- How do its “attention heads” (think of them as separate spotlights or mini-experts) learn to split up the job and work together?
- After training, can the model solve new tree puzzles it hasn’t seen before (i.e., does it generalize), or does it just memorize?
The authors study two related tasks:
- Backward reasoning: Start from the goal and walk up the tree to the root (goal → parent → grandparent → … → root).
- Forward reasoning: Start from the root and walk down to the goal (root → … → goal). This is harder because each parent can have multiple children, so you need to know the exact child to pick. The trick the model learns is to first find the backward path and then reverse it.
How did the authors study this? (Methods explained simply)
Here’s the setup using everyday language:
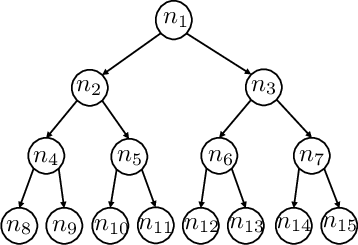
- Trees: A tree is a set of points (nodes) connected by links (edges). There’s one special starting node called the root and a target called the goal. Each node can have children (nodes below it) and a parent (the node above it), except the root which has no parent.
- Path-finding tasks:
- Backward: From goal to root—easy because each node has only one parent.
- Forward: From root to goal—harder because a parent can have multiple children, so you need the exact sequence.
- Transformers: Think of a transformer as a machine that reads inputs and writes outputs one step at a time. Its “attention heads” are like spotlights that focus on the most relevant pieces of information at each step. “Multi-head” means it has several spotlights that can specialize in different sub-jobs.
- Chain-of-thought (CoT): Instead of jumping straight to the final answer, the model writes down intermediate steps. Imagine tracing a maze by marking the path you’re taking; those marks help you decide the next move.
- Training with gradient descent: This is like playing a hot-and-cold game to adjust the model’s settings so it makes fewer mistakes over time.
- What they did:
- They built a one-layer transformer and showed exact settings (a “construction”) that make it solve the tasks.
- They then proved that normal training (gradient descent) actually finds those good settings.
- They also proved the model works on new trees it didn’t see during training (generalization).
- Finally, they ran small experiments to confirm the theory.
What did they find? (Main results and why they matter)
Here are the key discoveries:
- Backward reasoning is learnable with one attention head:
- The model learns to walk from the goal up to the root, one step at a time, by focusing attention on the current node’s parent.
- Training pushes the attention to become very sharp—like a spotlight that locks onto exactly the right node.
- Forward reasoning is learnable with two attention heads and a stage switch:
- Head 1: The “path-finder” that identifies the next node based on the current stage.
- Head 2: The “stage controller” that decides when to switch from building the backward path to outputting the forward path.
- The model first writes out the path backward (as scratch work), detects when it reaches the root, then flips and outputs the path forward.
- Training dynamics show specialization:
- During training, each head naturally becomes good at its role (path-finding vs. stage control) without being told which role to take.
- The authors prove this happens mathematically and show examples from experiments.
- Strong generalization:
- After training on certain random trees, the model correctly solves new trees it never saw before.
- This means it learned the rule for path-finding, not just the answers for specific trees.
- Big idea: Longer reasoning steps can replace model depth.
- By letting the model produce more chain-of-thought steps, even a shallow (one-layer) transformer can solve tasks that might otherwise need a deeper (multi-layer) model.
Why this matters:
- It gives a clear, step-by-step explanation of how reasoning can “emerge” from training.
- It shows how multi-head attention can self-organize into a team of mini-experts.
- It supports the idea that encouraging models to “show their work” (CoT) can unlock stronger reasoning.
What does this mean for the future? (Implications)
- Smarter training: If we design tasks that require intermediate steps, even simple models can learn complex reasoning skills.
- Efficient models: We might not always need deeper networks; sometimes letting models think step-by-step is enough.
- Better understanding: This work gives a “mechanistic” explanation—how and why the parts of the model learn to do the job—helping researchers build more reliable and interpretable AI.
- Practical tip: Prompting models to explain their steps (chain-of-thought) isn’t just a trick; it can reflect genuine reasoning ability that can be learned and generalized.
In short, the paper proves that with the right setup and training, even a simple transformer can learn to plan, switch strategies, and solve multi-step problems—by writing out and using its own intermediate steps.
Collections
Sign up for free to add this paper to one or more collections.