Capabilities of GPT-5 on Multimodal Medical Reasoning
Abstract: Recent advances in LLMs have enabled general-purpose systems to perform increasingly complex domain-specific reasoning without extensive fine-tuning. In the medical domain, decision-making often requires integrating heterogeneous information sources, including patient narratives, structured data, and medical images. This study positions GPT-5 as a generalist multimodal reasoner for medical decision support and systematically evaluates its zero-shot chain-of-thought reasoning performance on both text-based question answering and visual question answering tasks under a unified protocol. We benchmark GPT-5, GPT-5-mini, GPT-5-nano, and GPT-4o-2024-11-20 against standardized splits of MedQA, MedXpertQA (text and multimodal), MMLU medical subsets, USMLE self-assessment exams, and VQA-RAD. Results show that GPT-5 consistently outperforms all baselines, achieving state-of-the-art accuracy across all QA benchmarks and delivering substantial gains in multimodal reasoning. On MedXpertQA MM, GPT-5 improves reasoning and understanding scores by +29.62% and +36.18% over GPT-4o, respectively, and surpasses pre-licensed human experts by +24.23% in reasoning and +29.40% in understanding. In contrast, GPT-4o remains below human expert performance in most dimensions. A representative case study demonstrates GPT-5's ability to integrate visual and textual cues into a coherent diagnostic reasoning chain, recommending appropriate high-stakes interventions. Our results show that, on these controlled multimodal reasoning benchmarks, GPT-5 moves from human-comparable to above human-expert performance. This improvement may substantially inform the design of future clinical decision-support systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper tests a new AI model called GPT-5 to see how well it can “think like a doctor” using both words and pictures. In medicine, doctors don’t just read text; they also look at scans (like CTs), lab numbers, and patient stories. The authors ask: Can one general AI model understand all of that together and make good decisions without special medical training?
The main questions the researchers asked
- Can GPT-5 answer tough medical questions correctly when it only gets a normal prompt (no extra training), including questions that need reading medical images?
- Is GPT-5 better than older models (like GPT-4o) and smaller versions (GPT-5-mini and GPT-5-nano)?
- On these test-style questions, does GPT-5 do as well as, or even better than, trained human experts?
- Does GPT-5 especially improve at tasks that require step-by-step reasoning, not just memorizing facts?
How they tested the model (methods explained with easy analogies)
Think of this like giving different kinds of exams to the AI:
- Text-only medical exams: Questions where the model reads a paragraph and picks A, B, C, etc.
- Picture + text exams: Questions where the model reads a case and also looks at medical images (like radiology scans) before choosing an answer.
Here are the main “exams” they used:
- MedQA and MMLU-Medical: Big sets of medical multiple-choice questions covering many topics.
- USMLE sample exams: Practice questions from the U.S. medical licensing tests (Step 1, Step 2, Step 3).
- MedXpertQA: Very hard, expert-level questions. There are two versions: text-only and multimodal (text + medical images and test results).
- VQA-RAD: Yes/no questions about radiology images.
How they asked the questions:
- Zero-shot: Like giving the AI a test without showing it example answers first. No special extra training on these test sets.
- “Chain of thought” prompting: They asked the AI to “think step by step” before giving a final answer, similar to showing your work in math class.
- Same rules for all models: They used the same prompts and setup for GPT-4o, GPT-5, and the smaller GPT-5 versions. This makes the comparison fair—any difference is from the model, not the instructions.
How multimodal questions worked:
- The AI received the patient story plus the image(s) in the same message, so it could connect what it read with what it saw—like a doctor combining the chart and the scan.
What they found and why it matters
Big picture:
- GPT-5 did better than GPT-4o and the smaller GPT-5 models on almost every benchmark.
- It was especially strong on questions that require careful, multi-step reasoning and on tasks that combine text and images.
Highlights:
- MedQA (text-only): GPT-5 scored about 96%, higher than GPT-4o. That suggests strong medical knowledge and reasoning.
- USMLE samples: GPT-5 averaged about 95% across Steps 1–3, with the biggest jump on Step 2 (the step focused on clinical decision-making).
- MedXpertQA Text (hard expert-level questions): GPT-5 gained more than 25 percentage points over GPT-4o on measures of reasoning and understanding.
- MedXpertQA Multimodal (text + images): GPT-5 jumped about 26–29 percentage points over GPT-4o, a very large improvement. On these standardized tests, GPT-5 even scored higher than pre-licensed human experts by wide margins.
- VQA-RAD (radiology yes/no): A small exception—GPT-5 was slightly below GPT-5-mini here. The authors suggest the smaller model might fit this small, focused dataset a bit better, or that GPT-5 was more cautious.
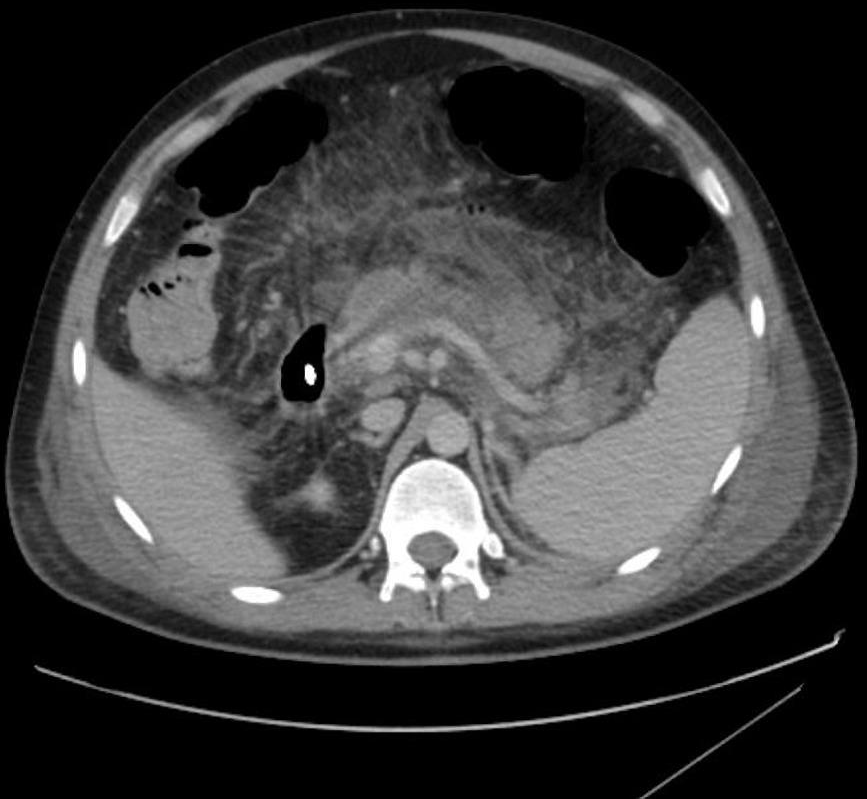
A real-case example (in simple words):
- The paper shows a case where a patient had severe vomiting, chest/neck crackling (air under the skin), and certain scan findings. GPT-5 correctly reasoned that this likely meant a tear in the esophagus (a dangerous emergency) and chose the right next test (a water-soluble contrast swallow). It explained why the other choices were wrong. This shows it can connect image clues with the story and labs to reach a high-stakes, sensible decision.
Why this matters:
- Medical work is multimodal—doctors constantly combine text, numbers, and images. GPT-5’s big gains with text+images suggest it’s getting better at the kind of integrated thinking doctors do.
What this could mean and what’s next
- Potential impact: On these controlled, test-style benchmarks, GPT-5 moves from “similar to humans” to “above human expert scores” in several areas, especially when combining text and images. That hints it could be a strong helper for clinical decision support—like a smart assistant that reads the chart, examines the scan, and offers a well-reasoned suggestion.
- Important caution: These are standardized tests, not real hospital situations. Real care involves messy, changing information, team communication, time pressure, and ethics. A model that aces exams still needs careful checks before being used with patients.
- What to do next: The authors recommend future work like real-world trials, better calibration, and safety measures, so the model’s advice is reliable, transparent, and used responsibly.
In short: This study shows GPT-5 is noticeably better at medical reasoning—especially when it has to blend text and images—and, on several tough benchmarks, it even beats trained human experts. That’s exciting for future medical AI tools, but careful testing and safeguards are essential before clinical use.
Collections
Sign up for free to add this paper to one or more collections.