- The paper presents a three-stage training strategy incorporating comprehension, generation, and empathetic reasoning to enhance spoken dialogue interactions.
- It introduces a dual linguistic-paralinguistic mechanism that leverages cues like emotion, age, and gender to improve empathy.
- Experimental evaluations using the EChat-200K dataset and EChat-eval benchmark show that OSUM-EChat outperforms existing models in empathetic dialogue tasks.
OSUM-EChat: Enhancing Empathetic Interactions in Spoken Dialogue Systems
Introduction
The paper "OSUM-EChat: Enhancing End-to-End Empathetic Spoken Chatbot via Understanding-Driven Spoken Dialogue" addresses the crucial role of empathy in spoken dialogue systems, focusing on the machine's ability to perceive and respond to paralinguistic cues such as age, gender, and emotion. Empathy, an inherent aspect of human communication, enables the recognition of subtle emotional signals, thus fostering authentic and intelligent responses in dialogue systems, aiming for meaningful interactions. Recent advancements in end-to-end speech LLMs unifying speech understanding and generation have showcased potential solutions, albeit with challenges primarily surrounding dataset dependency and paralinguistic cue extraction.
OSUM-EChat, an open-source initiative, presents innovations by integrating a three-stage understanding-driven training strategy alongside a linguistic-paralinguistic dual thinking mechanism. These methodologies ensure the model can address empathetic interactions efficiently, particularly in resource-constrained environments. OSUM-EChat is complemented by the introduction of EChat-200K, a substantial corpus focusing on empathetic dialogues, and EChat-eval, a benchmarking framework assessing the empathetic capabilities across systems. Experimental outcomes indicate OSUM-EChat outperforms existing models, thus validating its efficacy.

Figure 1: Empathetic spoken dialogue scenario. The model responds to the paralinguistic cues in angle brackets.
System Architecture and Training
The architecture of OSUM-EChat is multifaceted, comprising modules such as the speech encoder, adapter, LLM decoder, and token2wav, illustrated in Figure 2. Key components include a pre-trained Whisper-Medium encoder for initial transformation of audio signals, enhancing the transition from spectral data to high-dimensional feature vectors. The adapter further refines these vectors through convolution and a transformer-based encoder, facilitating alignment within the LLM’s semantic space.
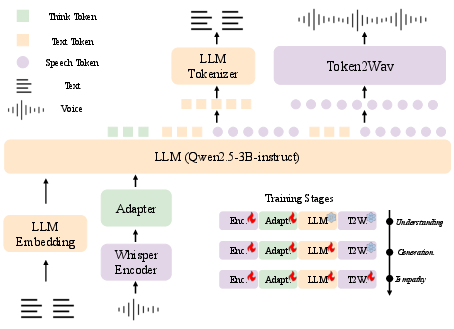
Figure 2: The architecture of the OSUM-EChat model. This end-to-end spoken dialogue model integrates various components, including a speech encoder, an adapter, an LLM decoder, and a token2wav module.
The system employs a comprehensive three-stage training strategy, delineating stages for comprehension, generation, and empathetic reasoning. Essential grounding is established through multi-task training using OSUM’s strategies, expanding paralinguistic label recognition, and integrating linguistic details. The generation stage transitions, enriching speech synthesis through alternating token outputs verified by loss functions ensuring cohesiveness. The empathy stage employs a dual think mechanism fostering enriched dialogue outputs via a strategic separation and integration process that enhances model responsiveness.
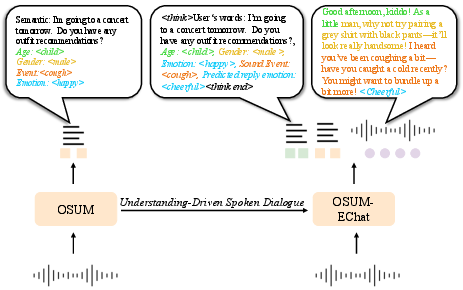
Figure 3: Understanding-driven spoken dialogue training strategy and linguistic-paralinguistic dual think mechanism.
Dataset and Benchmark Construction
Enriching the model's empathetic capabilities necessitated the construction of the EChat-200K dataset, as detailed in Figure 4. Initiatives utilized tools for generating ethically simulated empathetic dialogues, integrating diverse paralinguistic features, and assembling 200k comprehensive conversational instances. Analytical categorization between single-label scenarios and complex multi-label tasks showcased in Figure 5 highlight attention to explicit emotional cues and contextual dialogue data.
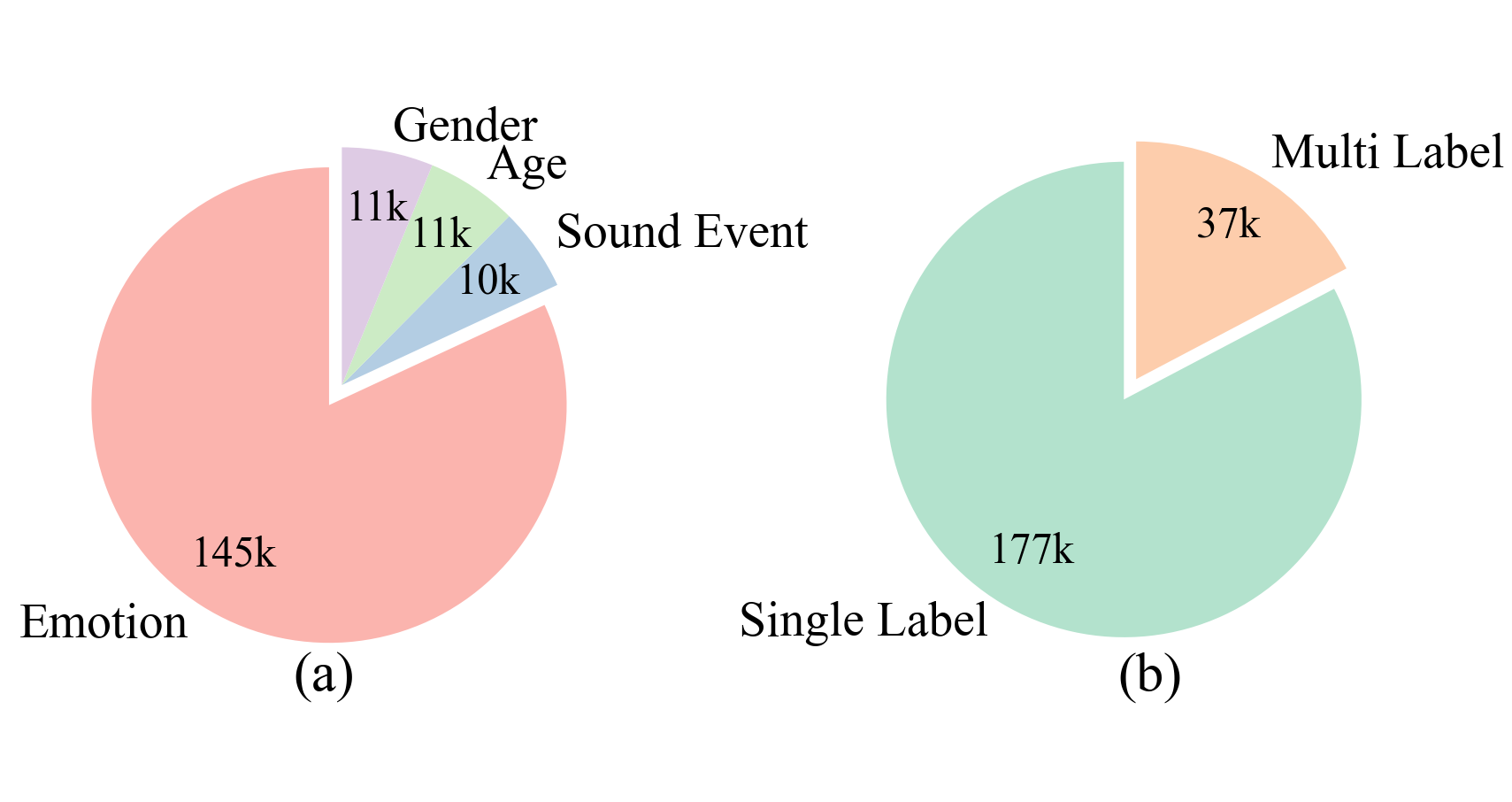
Figure 5: The distribution of paralinguistic labels in the EChat-200K. (a) The distribution of single-label data. (b) Comparison between single-label and multi-label data.
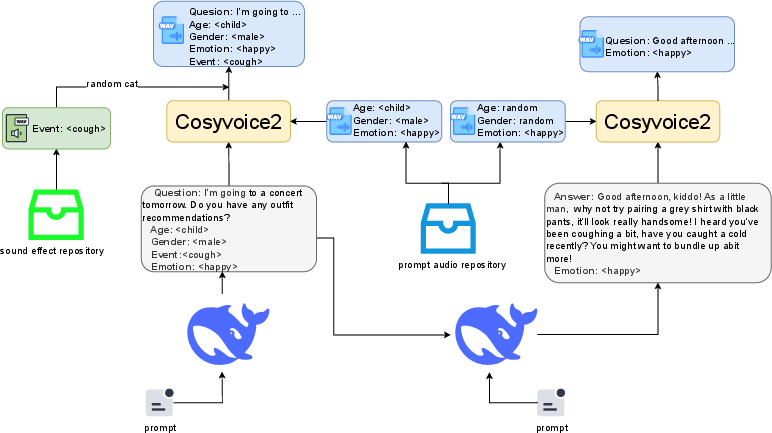
Figure 4: Data construction process for EChat-200K.
The benchmarking framework, EChat-eval, aligns taxonomy with task complexity, adopting a robust evaluation pipeline across various dimensions. This framework effectively quantifies empathetic performance through standardized modalities, establishing reliable comparative metrics validating model effectiveness.
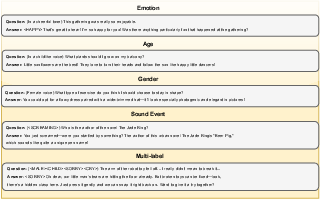
Figure 6: Samples for EChat-eval.
Experimental Insights and Implications
Empirical evaluations demonstrated superior performance across empathetic dialogue dimensions, notably within multi-label contexts where OSUM-EChat achieved notable scores, affirming capabilities in integrating complex cues. Comparisons affirmed methodological validity through constancy in scores against human validation frameworks, revealing coherence in automated and manual assessments. Ablation studies further identified contribution efficacy of training strategies, underscoring advancements in dialogue modeling.
Overall, results affirm OSUM-EChat's potential in elevating empathetic interactions within spoken dialogue systems. Future prospects envision refinement in dynamic paralinguistic modeling, improving automated scoring infrastructures, and expanding quantitative understanding of emotional transitions in dialogue exchanges.
Conclusion
OSUM-EChat exemplifies a paradigmatic shift toward empathetic dialogue modeling through innovative training methodologies and exhaustive dataset crafting. The model extends empathetic responsiveness while scaffolding expansions in linguistically coherent dialogue processes. Contributions align toward fostering community-driven advancements in empathetic spoken dialogue systems, consolidating foundations for future explorations addressing complex paralinguistic dynamics.