- The paper introduces a scalable autoencoder featuring a Sparse Motion Dictionary for interpretable and controlled facial motion transfer.
- It employs an edit-warp-render strategy that enables precise manipulation of head pose and facial expressions in both self- and cross-reenactment tasks.
- Comparative evaluations show superior performance over state-of-the-art methods, with scalability to nearly 1B parameters on large-scale datasets.
LIA-X: Interpretable Latent Portrait Animator
Introduction
The LIA-X framework introduces a scalable, interpretable approach to portrait animation, enabling fine-grained control over facial dynamics transferred from a driving video to a source portrait. Unlike prior methods that rely on explicit structure representations or dense, entangled latent codes, LIA-X leverages a Sparse Motion Dictionary within an autoencoder architecture to disentangle and control facial motion semantics. This design supports an "edit-warp-render" pipeline, allowing for precise alignment and manipulation of head pose and facial expression prior to animation. The model is demonstrated to scale to approximately 1 billion parameters and is trained on a diverse, large-scale dataset, achieving superior performance in both self-reenactment and cross-reenactment tasks.
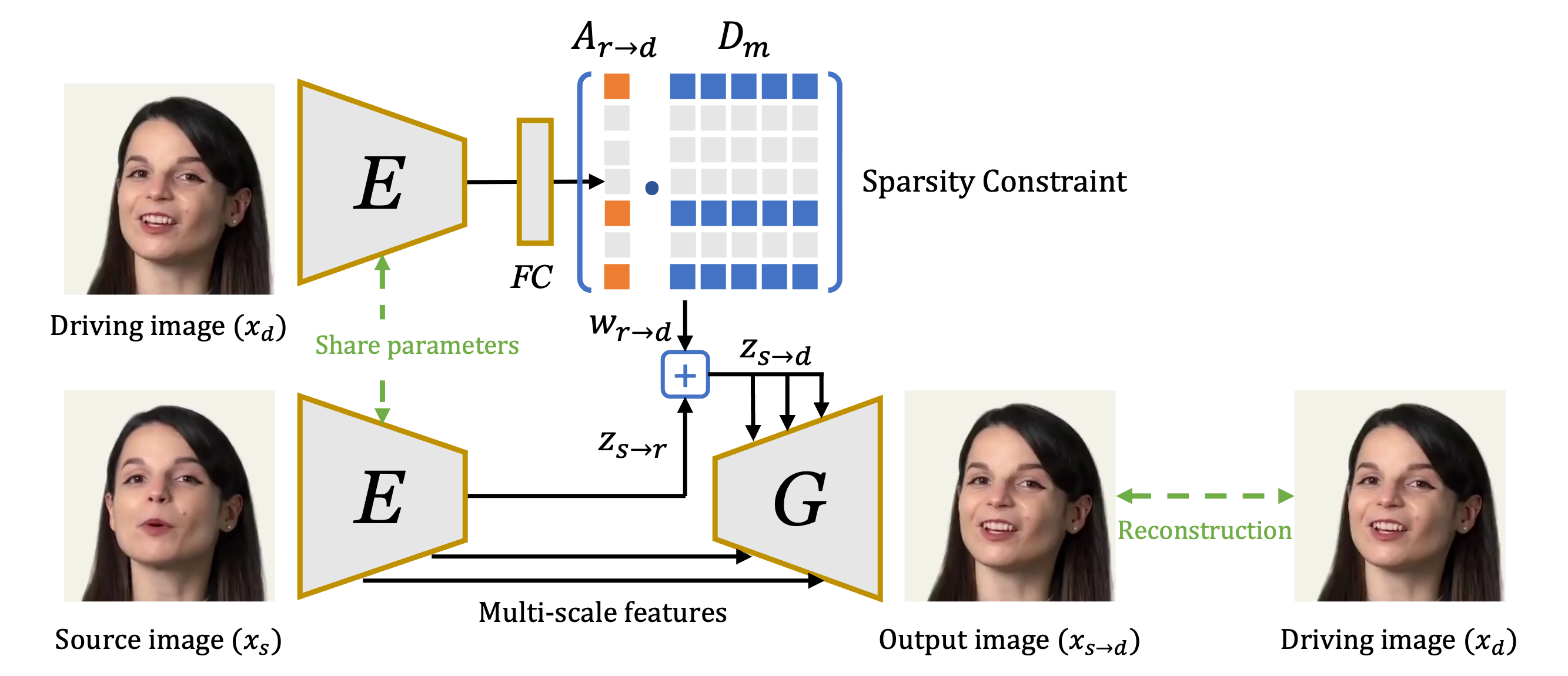
Figure 1: Overview of LIA-X architecture, highlighting the encoder, optical-flow generator, rendering network, and the sparsity-constrained motion dictionary.
Methodology
Architecture and Sparse Motion Dictionary
LIA-X builds upon the Latent Image Animator (LIA) autoencoder, comprising an encoder E, an optical-flow generator Gf, and a rendering network Gr. The key innovation is the Sparse Motion Dictionary Dm, a set of motion vectors with enforced sparsity via an L1 penalty on the motion coefficients Ar→d. This constraint encourages the model to reconstruct each driving image using a minimal subset of motion vectors, promoting disentanglement and interpretability of facial dynamics.
The animation process is formalized as linear navigation in latent space:
zs→d=zs→r+i=1∑Maidi
where zs→r is the transformation from source to reference image, and ai are the sparse coefficients for each motion vector di.
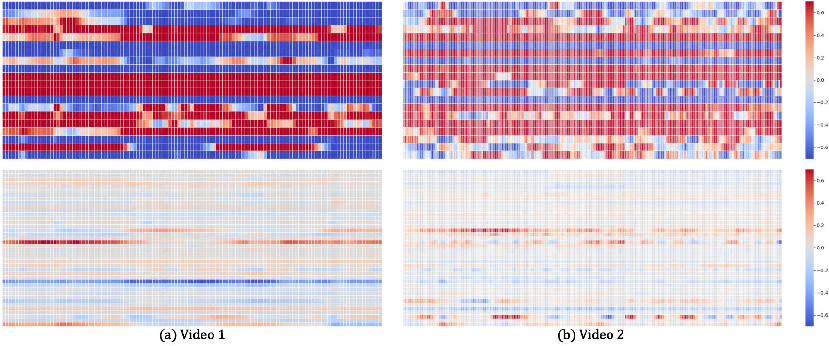
Figure 2: Sparsity analysis comparing activations of motion vectors with and without the sparsity constraint, demonstrating selective activation in LIA-X.
Edit-Warp-Render Strategy
The interpretable nature of the Sparse Motion Dictionary enables a controllable "edit-warp-render" pipeline. Users can manipulate the source portrait by adjusting specific motion vectors to align pose and expression with the driving frame before applying motion transfer. This is particularly effective in cross-identity scenarios with large initial discrepancies.
Training and Scalability
LIA-X is trained in a self-supervised manner using a composite loss: L1 reconstruction, VGG-based perceptual, adversarial, and sparsity penalties. The architecture incorporates advanced residual blocks inspired by StyleGAN-T, facilitating scalability to 1B parameters. Training utilizes a mixture of public and internal datasets, totaling 0.5M sequences and 94M frames, with gradient accumulation on 8 A100 GPUs.
Interpretability and Controllability
Empirical analysis reveals that the sparse motion vectors correspond to human-interpretable facial attributes and 3D-aware transformations. Manipulating individual vectors enables control over yaw, pitch, roll, and fine-grained semantic attributes such as mouth, eyes, and eyebrows.



Figure 3: LIA-X enables 3D-aware portrait manipulation (yaw, pitch, roll) by adjusting corresponding motion vectors.

Figure 4: Image editing capabilities of LIA-X, demonstrating control over fine-grained semantic attributes via motion vector manipulation.
The disentanglement achieved by the sparse dictionary allows for compositional editing, supporting complex user-guided image and video manipulations without explicit 3D representations.



Figure 5: 3D-aware video manipulation, showing seamless rotation of head pose in real-world video while preserving identity.
Comparative Evaluation
LIA-X is evaluated against state-of-the-art GAN-based and diffusion-based methods (FOMM, TPS, DaGAN, MCNet, X-Portrait, LivePortrait) on self-reenactment and cross-reenactment tasks. Quantitative metrics (L1, LPIPS, SSIM, PSNR, FID, Identity Similarity, Image Quality) consistently favor LIA-X, with notable improvements in high-resolution (512×512) settings and challenging cross-identity scenarios.

Figure 6: Qualitative comparison on cross-reenactment, illustrating LIA-X's superior ability to handle large pose and expression variations via pre-animation editing.
Scaling analysis demonstrates that increasing model size from 0.05B to 0.9B parameters yields performance gains, though improvements saturate beyond 0.3B, suggesting dataset size as a limiting factor for further scaling.
Practical and Theoretical Implications
LIA-X's interpretable latent space and controllable animation pipeline have direct applications in entertainment, e-education, digital human creation, and user-guided editing. The framework's scalability and efficient inference (relative to diffusion models) position it as a practical complement to current generative approaches. The sparse dictionary paradigm may inform future research in disentangled representation learning and interpretable generative modeling.
Theoretically, LIA-X demonstrates that sparse coding principles can be effectively integrated into large-scale, self-supervised generative models to achieve both scalability and interpretability. The linear navigation formulation provides a unified framework for motion transfer, editing, and 3D-aware manipulation.
Limitations and Future Directions
Current limitations include fixed resolution support and reliance on convolutional architectures, which may constrain further scaling. Future work should explore dynamic resolution techniques and transformer-based architectures (e.g., DiT) for enhanced scalability and generalization. Expanding the training dataset could further improve model capacity and performance.
Conclusion
LIA-X advances portrait animation by integrating a Sparse Motion Dictionary into a scalable autoencoder, enabling interpretable, controllable, and high-quality motion transfer. The framework outperforms prior methods across benchmarks and supports diverse editing applications. Its design principles—sparse, disentangled latent codes and scalable architectures—are likely to influence future research in interpretable video generation and user-controllable generative models.